







本实战项目是中国大学MOOC国家精品课程《Python网络爬虫与信息提取》(by 嵩天 北京理工大学)学习笔记。代码段均可在ide中运行by now(2021-12-01).
1.爬取目标
爬取的是百度/360搜索某个关键词返回的页面信息。
首先看一下百度请求数据的url长下面这样,这里搜索的是关键词字符串是‘Python’。
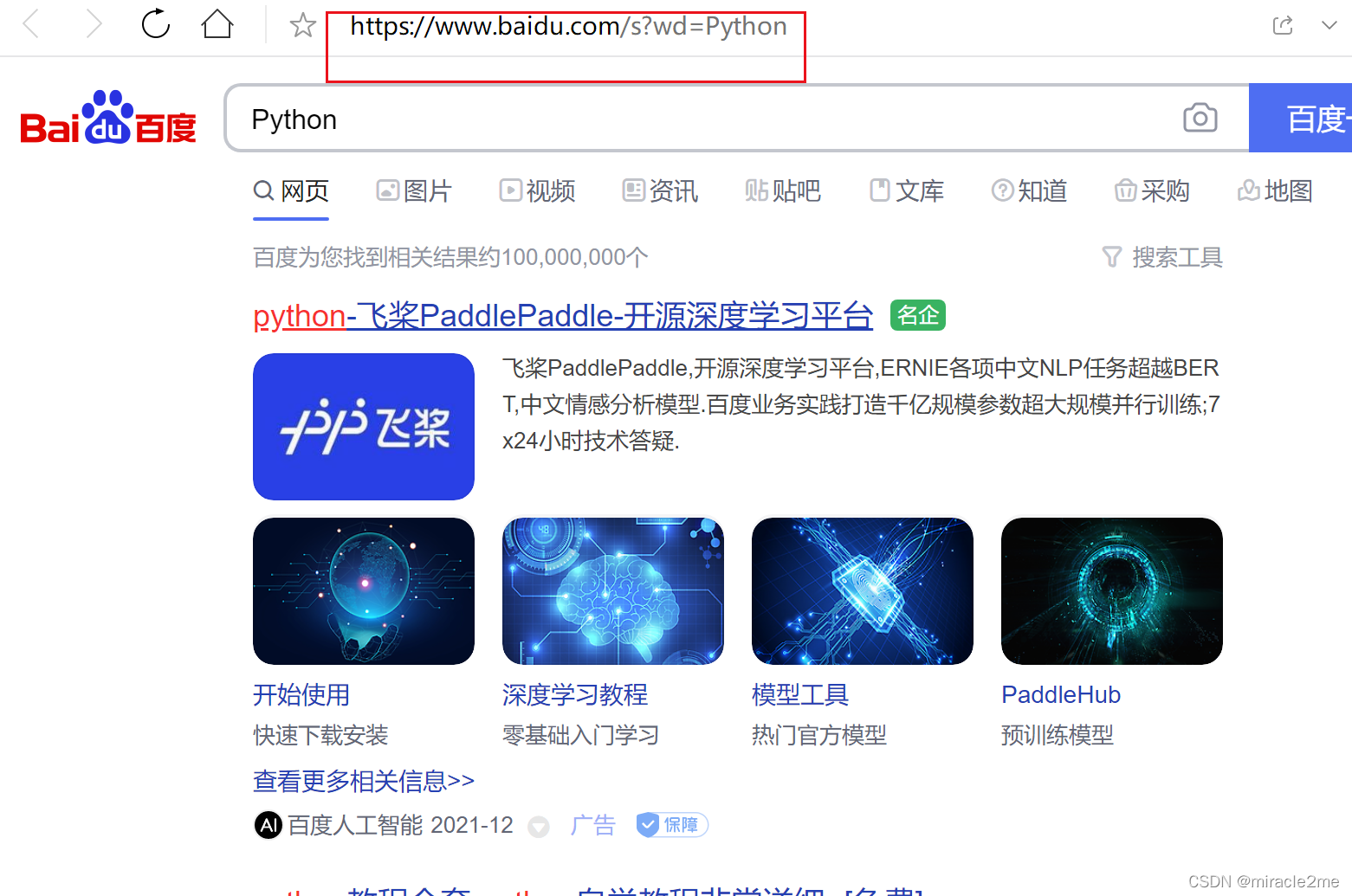
360搜索关键词'Python'的url及返回是下面这样的:
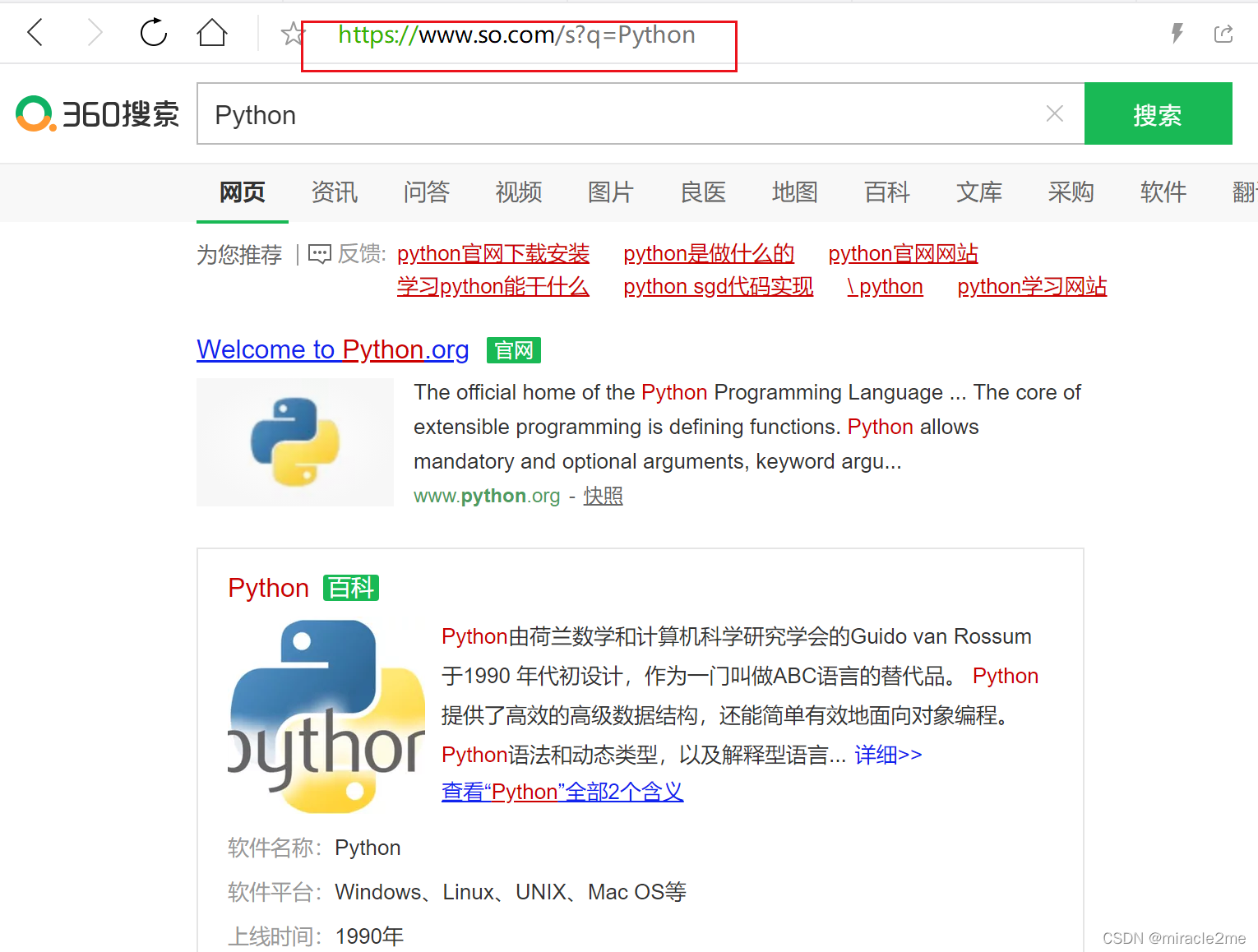
2.爬取链接
百度搜索url: http://www.baidu.com/s
360搜索url: http://www.so.com/s
3.技术路线
继续深入了解requests方法的参数,在上一讲headers参数上又增加新参数‘params’的使用。
上一讲地址:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











