






整理了下大模型在SCIENCE中的应用案例:
浦科化学(chemllm)
2024年1月26日,上海人工智能实验室(上海ai实验室)开源发布首个科学大模型浦科化学(chemllm),拓展了大模型助力科学研究的探索路径。专注核心:化学知识注入,专业能力突出.
为了评估浦科化学的专业能力,上海ai实验室的研究人员对其在三种相关任务上的表现进行了测试:分子名称转换、分子性质预测和反应产物预测——这些任务分别涉及化学物质的表示、性质和转化,是化学研究的基础和核心。
分子名称转换方面,要求模型能够在不同分子表示方式之间进行准确转换,如smiles、iupac名称、分子式等;
分子性质预测方面,要求模型能根据分子的结构和组成,预测其化学性质,如沸点、密度、溶解度等;
反应产物预测方面,要求模型能根据给定的反应物和反应条件预测反应产物的结构。
依托书生·浦语2.0基座模型优秀的多语言能力,浦科化学在经过专业化学知识训练后,还具备了优秀的化学专业中英文翻译能力,可帮助化学研究者跨越语言障碍,准确地翻译化学文献中的专有名词,获取更多的化学知识。
在专业化学知识训练之外,浦科化学也进行了初高中知识的学习。在回答初高中化学题目时,不仅能给出答案,还能给出具体的解释。
举一反三:扩展大模型应用,助推科研新范式
对大语言模型进行化学专项训练,不仅扩展了大模型的应用空间,更为ai for science相关研究开启了新的探索路径。
上海ai for science团队面向化学、物理、生命、地球等科学领域,通过深入研究各学科基础理论,结合最新人工智能理论,探索ai驱动重大科学问题的研究范式,加速人工智能在化学、药物研发、新材料、气象等领域的渗透与落地,赋能各行业发展。其中,ai for chemistry方面的研究以语言模型为核心,通过大模型连接智能化实验设备,全方位提升实验效率,从而实现化学研究的自动化和智能化。相关研究范式的创新,将助推科学发现速度,实现更大的社会效益。
未来,基于浦科化学模型,人工智能可为化学研究提供智能化辅助,如化学合成路径规划、化学反应条件优化、实验结果自动化分析等,从而提升化学研究的效率和质量。
开源链接:
https://huggingface.co/ai4chem/chemllm-7b-chat
https://sghexport.shobserver.com/html/baijiahao/2024/01/29/1244545.html
xTrimoPGLM
xTrimoPGLM蛋白质语言模型由百图生科和清华大学共同开发,于23年 7 月发表
这些任务从蛋白质结构、可发展性、相互作用到功能分为四大类,具体又包括评估蛋白质特性,如溶解性、对蛋白酶的稳定性、温度敏感性、蛋白质结合亲和力、抗生素抗性等,这个蛋白质语言模型100B亿参数在其中的13个任务上都取得了SOTA。团队还计划把模型扩展到RNA、DNA等不同模态的生命科学数据上,甚至是跨细胞、跨组织层面,尝试实现更加通用的生命科学大模型。
论文地址:https://www.biorxiv.org/content/10.1101/2023.07.05.547496v1
2023 年 3 月 23 日,百图生科在北京发布生命科学大模型驱动的 AIGP —— AI Generated Protein 平台。

xTrimoGene
https://zhuanlan.zhihu.com/p/635839720
https://www.biorxiv.org/content/10.1101/2023.03.24.534055v1
Med-PaLM2 https://zhuanlan.zhihu.com/p/629973364
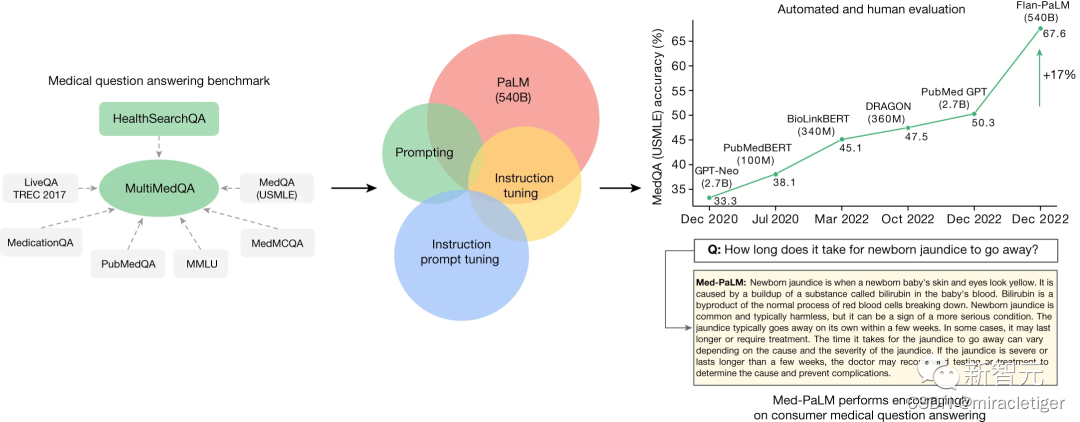
5月16日,Google Research和DeepMind发布了Med-PaLM 2,迈向专家级医疗问答的大语言模型(Towards Expert-Level Medical Question Answering with Large Language Models)
Med PaLM是第一个超过美国医师执照考试(USMLE)样例问题“合格”分数的模型,在MedQA数据集上得分67.2%。
Med-PaLM 2,它利用一系列LLM改进(PaLM 2)、医学领域微调和提示策略(包括一种新的集成精炼方法ensemble refifinement approach)来弥补这些差距。
基础LLM 对于Med-PaLM,基础LLM是PaLM 。Med-PaLM 2建立在PaLM 2之上,这是Google的大型语言模型的新版本,在多个LLM基准测试任务上表现有显著改进。谷歌构建的最新基准MultiMedQA,是由七个医学问答数据集组成的基准。
通过少样本、CoT、以及自洽性提示策略的组合,Flan-PaLM在MedQA、MedMCQA、PubMedQA和MMLU临床主题上取得了SOTA,超越几个强大LLM基线。
Coscientist
Coscientist 由匹兹堡的 Coscientist 大学和卡内基梅隆大学的 Wilton E. Scott 能源创新研究所共同研发。这个智能助手可以通过互联网搜索相关资料,使用机器人实验的应用程序接口 (API),并借助其他大语言模型来完成多样化的任务。Coscientist 的研发是独立进行的,与其他自主智能体的研究[23–25]同步展开,化学领域的 ChemCrow[26] 也是一个相关的例子。我们在论文中展示了 Coscientist 在六大任务方面的灵活性和高效能力,包括:(1)利用公开数据规划已知化合物的化学合成;(2)高效搜索和浏览大量硬件文档;(3)利用文档在云实验室执行高阶指令;(4)通过低阶指令精准控制液体处理设备;(5)处理需要多个硬件模块协同和多数据源整合的复杂科学任务;(6)解决分析既往实验数据的优化问题。
Coscientist 系统架构
Coscientist 通过与多个模块(包括网络和文档搜索、代码执行)的互动以及执行实验,获取解决复杂问题所需的知识。其中,主模块“Planner”负责根据用户输入来规划行动,通过调用下文定义的几种命令。Planner 是一个基于 GPT-4 的聊天功能实例,充当助手的角色。用户的初始输入和命令输出都作为消息传递给 Planner。系统为 Planner 设计的提示(定义了 LLM 目标的静态输入)是以模块化的方式制定的[1,27],包含四个定义行动空间的命令:‘GOOGLE’、‘PYTHON’、‘DOCUMENTATION’ 和 ‘EXPERIMENT’。Planner 根据需要调用这些命令来收集知识。其中,GOOGLE 命令负责利用 ‘Web searcher’ 模块在互联网上进行搜索,这个模块本身也是一个 LLM。
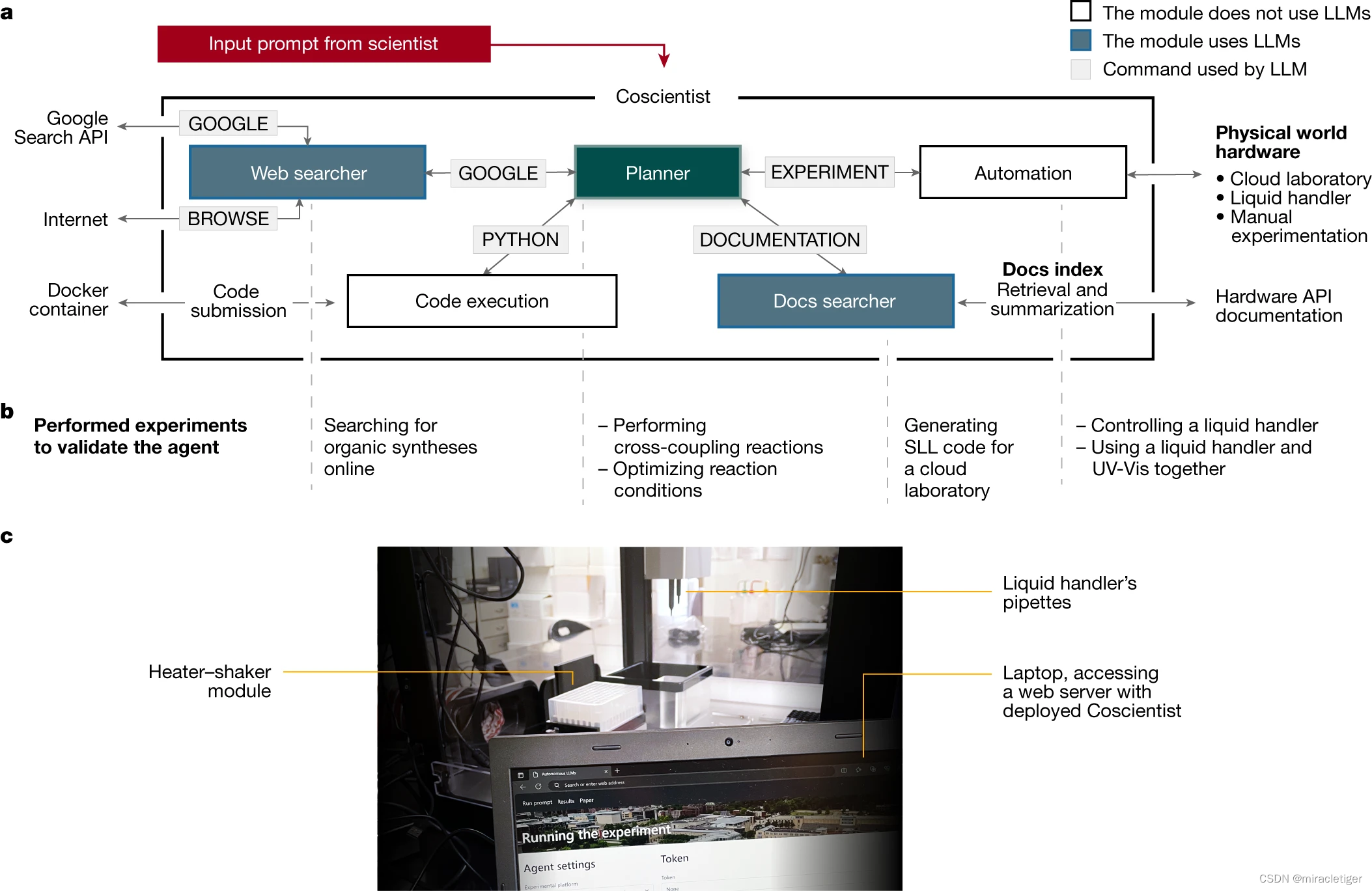
图系统架构。a, Coscientist 由多个模块组成,这些模块互相交换信息。蓝色背景的方框表示 LLM 模块,Planner 模块以绿色显示,输入提示为红色。白色方框表示不使用 LLM 的模块。b, 展示了使用单个模块或其组合时进行的各种实验类型。c, 实验装置的图片,其中包括一个液体处理器。UV-Vis 指的是紫外 - 可见光谱。
Coscientist的运作系统 规划者(Planner) ,即主模块,是整个系统的智能中枢,能够根据用户输入的内容,调用和协调其他模块来规划和推进整个实验。“大脑”能够给下面的四个模块下达指令,包括GOOGLE、PYTHON、DOCUMENTATION和EXPERIMENT。 网络搜索(Web searcher) 会接收到来自Planner的GOOGLE指令,负责在互联网中检索实验相关信息,而该模块本身也是个LLM。 代码执行(Code execution) 会接收到来自Planner的PYTHON指令,提供一个独立的python执行环境,为接下来的实验做准备。 文件检索(Docs searcher) 会接收到来自Planner的DOCUMENTATION指令,主要负责进行文本检索和文档理解,能够为主模块提供有用的信息,比如提供实验参数以及操作细节等文档。 自动操作(Automation) 会接收到来自Planner的EXPERIMENT指令,也就是最终的实验执行环节。该模块能够将控制中枢下发的实验方案转换为设备控制代码,根据DOCUMENTATION描述的API来自动化控制实验设备,完成实验操作。 百说不如一练,这个最新研发出来的AI“化学家”Coscientist的表现究竟如何? 为了测试其在已知化合物的化学合成上的真实能力,研究者要求Coscientist自行通过网络搜索,来完成多种药物分子的合成。并对比了OpenAI的GPT-3.5和GPT-4、Anthropic的Claude 1.3和Falcon-40B-Instruct等不同模型的能力。
https://blog.csdn.net/csdn_codechina/article/details/135692909
https://www.nature.com/articles/s41586-023-06792-0
ChemCrow

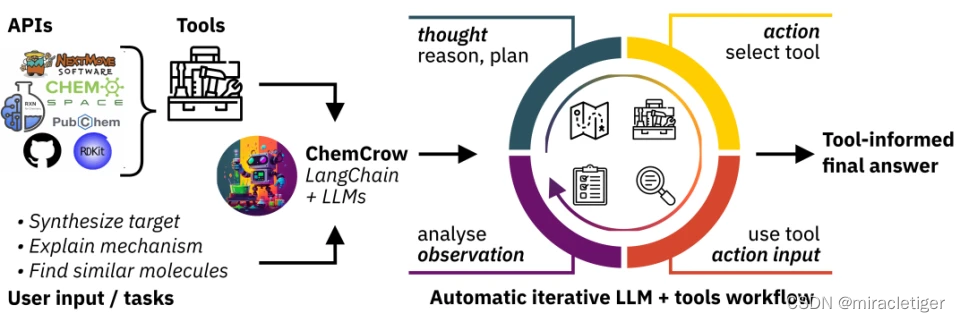
来自洛桑联邦理工学院(EPFL)和罗切斯特大学的研究人员开发了 ChemCrow,一种 LLM 化学智能体,受 LLM 在其他领域成功应用的启发,研究人员提出一个 LLM 驱动的化学引擎 ChemCrow,旨在简化药物、材料设计和合成等领域中各种常见化学任务的推理过程。
通过集成 13 种专家设计的工具,ChemCrow 增强了 LLM 在化学方面的表现,并出现了新的功能。该研究通过 LLM 和专家人工评估,证明了 ChemCrow 在自动化各种化学任务方面的有效性。令人惊讶的是,作为评估器的 GPT-4 无法区分明显错误的 GPT-4 completions 和 GPT-4 + ChemCrow 性能。
ChemCrow 充当专家化学家的助手,同时通过提供一个简单的界面来获取准确的化学知识,从而降低非专家的进入门槛。研究人员分析了 ChemCrow 在 12 个用例上的功能,包括合成目标分子、安全控制以及搜索具有相似作用模式的分子。
结果表明,ChemCrow 大大优于普通的 LLM,尤其是在更复杂的任务上。GPT-4 未能系统地给出事实准确的信息(平均得分为 4.79,而 ChemCrow 为 9.25),示例中的大多数错误要么给出了错误的分子名称或 SMILES,要么预测了错误的反应。在完成分数上,GPT-4 的表现略好于 fact 分数 (6.87),但仍远低于 ChemCrow 的水平 (9.62),显示出 ChemCrow 在解决化学任务方面的有效性。
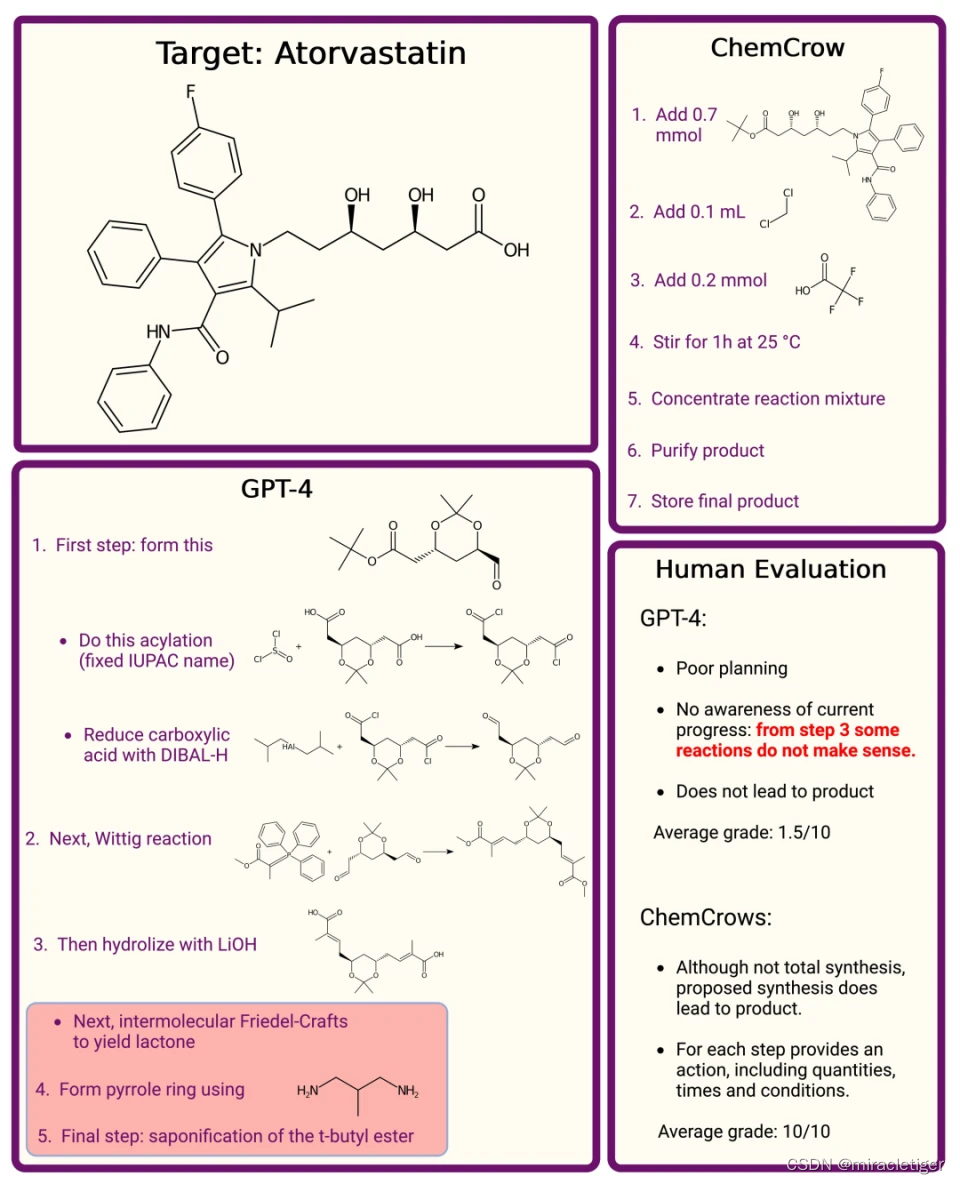
https://new.qq.com/rain/a/20230430A02ZXF00
论文链接:https://doi.org/10.48550/arXiv.2304.05376
ChatGPT Chemistry Assistant
来自加州大学的研究团队使用 AI 模型 ChatGPT 执行一项特别耗时的任务:搜索科学文献。利用这些数据,他们构建了第二个工具,一个预测实验结果的模型。
研究人员使用提示工程(prompt engineering )来指导 ChatGPT 从不同格式和风格的科学文献中自动进行金属有机框架 (MOF) 合成条件的文本挖掘。这有效地缓解了 ChatGPT 产生信息幻觉的倾向,这是以前在科学领域使用大型语言模型(LLM)具有挑战性的问题。这个称为 ChatGPT 化学助手 ( ChatGPT Chemistry Assistant,CCA) 的新系统也可用于其他化学领域。
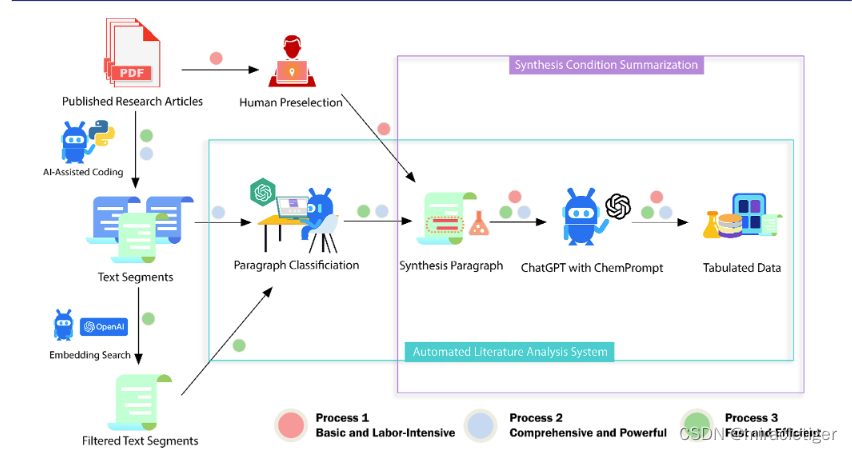
流程 1 中,研究人员开发了提示来指导 ChatGPT 总结这些论文中指定实验部分的文本。为了取代人工干预来获取合成部分的需要,在流程 2 中,为 ChatGPT 设计了一种方法,将文本输入分类为「实验部分」或「非实验部分」,使其能够生成用于摘要的实验部分。在流程 3 中,进一步设计了一种技术来快速消除不相关的论文部分,例如参考文献、标题和致谢,这些部分不太可能包含全面的综合条件。这加快了后续分类任务的处理速度。因此,在流程1中,ChatGPT 单独负责总结和列出合成条件,并需要一段或多段实验文本作为输入,而流程 2 和流程 3 可以被认为是一个「自动论文阅读系统」。虽然流程 2 需要对整篇论文进行彻底检查以仔细检查每个部分,但更高效的流程 3 会快速扫描整篇论文,删除最不相关的部分,从而减少 ChatGPT 必须仔细分析的段落数量。
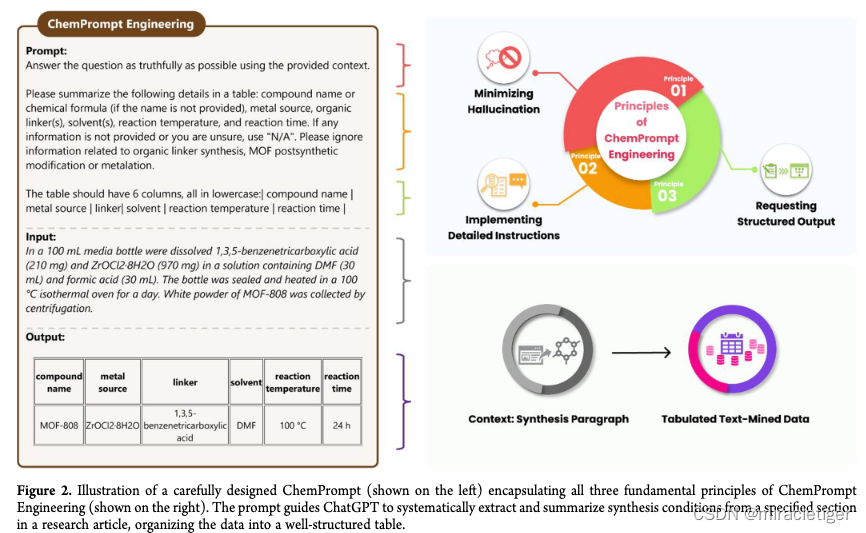
指示工程在化学相关任务领域,通过采用提示工程 (PE) 可以显著提高 ChatGPT 的性能,这一精心设计提示的方法,可引导 ChatGPT 生成精确且相关的信息。研究人员提出了以化学为重点的应用中提示工程的三个基本原则,称为 ChemPrompt engineering:
(1)最小化幻觉,这需要制定提示以避免从 ChatGPT 中引出捏造或误导性的内容。
(2)实施详细说明,即在提示中提供明确的指示,以帮助 ChatGPT 理解上下文和所需的响应格式。
(3)请求结构化输出,包括纳入有组织且定义明确的响应模板或指令以促进数据提取。
通过问题后的附加提示,可以最大限度地减少幻觉并迫使 ChatGPT 根据其知识回答问题
论文链接:https://doi.org/10.1021/jacs.3c05819
scGPT
23年5 月份,加拿大多伦多大学和彼得·蒙克心脏中心(Peter Munk Cardiac Centre)的研究人员,通过利用呈指数增长的单细胞测序数据,首次尝试对超过 1000 万个细胞进行生成预训练来构建单细胞基础模型。这是第一个基于单细胞生物学的大型语言模型。
随后,7 月份,该研究团队首次尝试对超过 3300 万个细胞进行生成预训练来更新 scGPT。
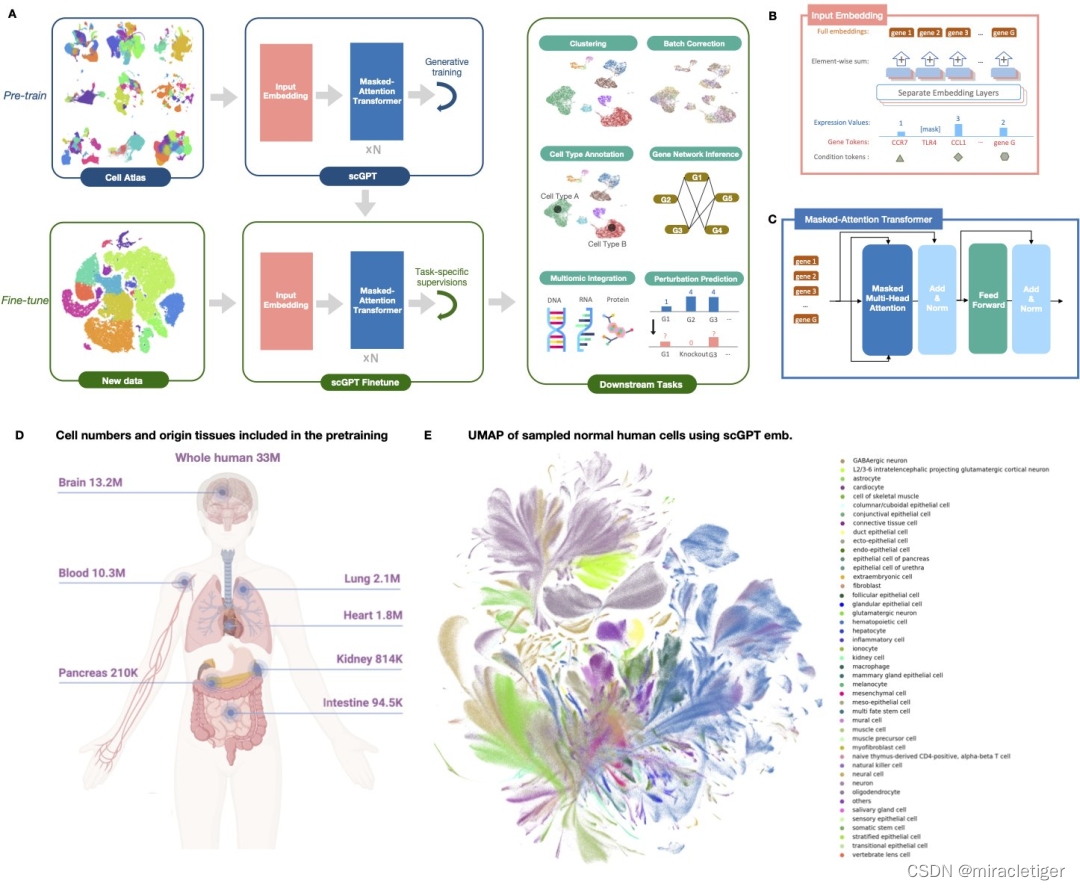
scGPT 模型概述。
推荐阅读:
GeneCompass
23年9 月底,中国科学院多学科交叉研究团队组成的「指南针联盟」(Xcompass Consortium)在 AI 能赋能生命科学研究方面取得了重要突破,成功构建了世界首个跨物种生命基础大模型——GeneCompass。
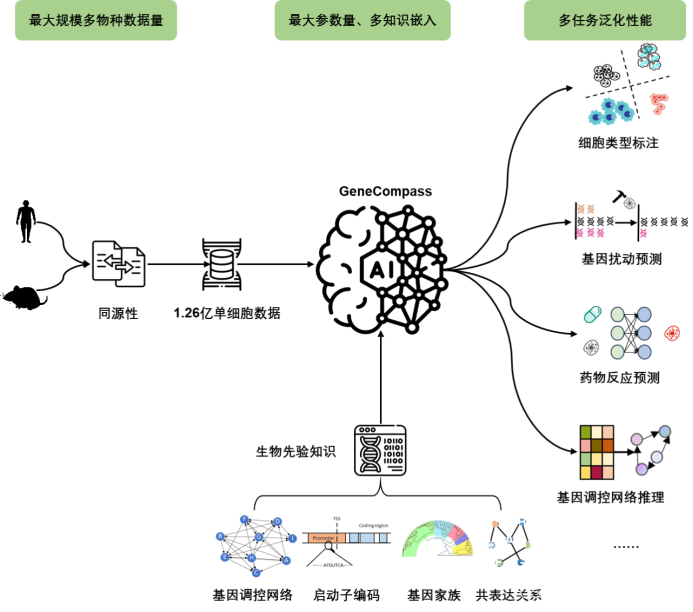
GeneCompass:首个跨物种生命基础大模型。
推荐阅读:
中国科学院团队两篇齐发:首个跨物种生命基础大模型+新型细胞命运预测AI模型发布
ChatDD
23年9 月 21 日,清华系初创团队水木分子发布了新一代对话式药物研发助手 ChatDD (Drug Design) ,覆盖药物立项、临床前研究、临床试验的各阶段,作为制药专家的得力 AI 助手,提升药物研发效率。当天,团队还发布了全球首个千亿参数多模态生物医药对话大模型 ChatDD-FM 100B,在权威中文基础模型 C-Eval 评测中达到全部医学 4 项专业第一,也是在该四项任务上截至目前唯一平均分超过 90 分的模型。

聂再清教授发布药物研发助手 ChatDD。
推荐阅读:
「制药版ChatGPT」,清华系团队水木分子发布生物医药行业千亿参数大模型 ChatDD
BioGPT
23年9 月份,微软亚洲研究院的研究团队提出了 BioGPT,这是一种在大规模生物医学文献上进行预训练的特定领域生成式 Transformer 语言模型。研究人员在六项生物医学自然语言处理任务上评估了 BioGPT,并证明他们的模型在大多数任务上优于以前的模型。
推荐阅读:
微软亚洲研究院开源 BioGPT,一种基于生物医学研究文献进行训练的大型语言模型
MolReGPT
香港理工大学和密歇根州立大学的研究人员在分子发现领域利用 LLM 的强大功能进行了探索尝试。开发了一个基于检索的提示范式 MolReGPT,使用提示来指导 LLM 在分子和分子文本描述之间进行翻译。
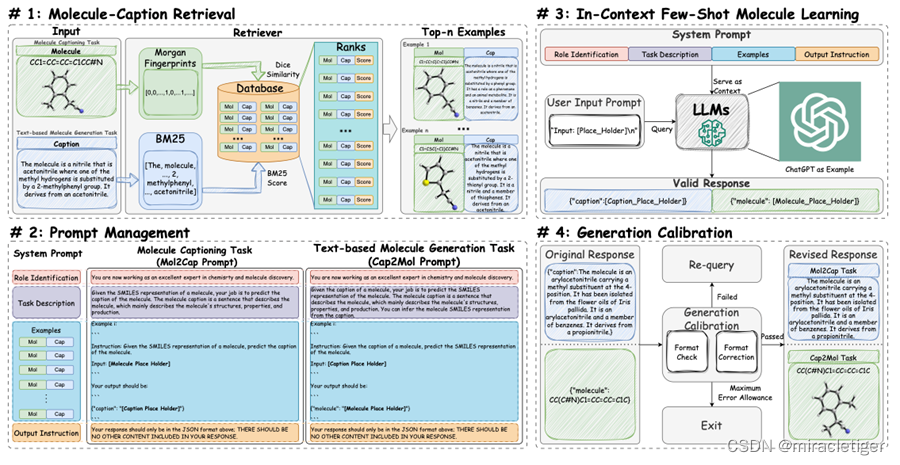
MolReGPT 的总体流程框架。
推荐阅读:
MolReGPT: 利用大型语言模型探索分子发现——分子与文本描述间相互翻译
多模态科学文献大模型
深势科技推出的 Uni-Finder 正在改变这一局面。这个革命性的智能文献数据库平台,不仅提供高效的多模态检索功能,还能通过先进的自然语言交互技术灵活提取关键数据,大大优化了科学文献的理解和分析过程。
科研活动中,科学文献的阅读和分析是一个至关重要但极为耗时的步骤。以药物研发为例,研究人员需要阅读大量文献来分析特定靶点的关键作用区域,收集活性小分子的数据等。这一过程虽关键,却往往需要耗费大量的时间和人力资源。传统的科学文献数据库,如 SciFinder,尽管提供了检索功能,却依旧让研究人员不得不人工筛选和阅读大量文献。此外,尽管像 ChatGPT 这样的大型语言模型在处理自然语言方面表现出色,但面对含有分子结构图、化学反应式等多模态元素的科学文献时,它们却显得力不从心。针对这一挑战,深势科技推出了革命性的智能科学文献数据库平台 Uni-Finder,旨在进一步提升科学文献的阅读和分析效率。该平台不仅具备传统数据库(例如 SciFinder)的多模态检索功能,还能通过自然语言交互,在筛选结果中灵活且自动化地提取所需信息,如多个专利的共同中间体或与特定靶点相关的小分子活性数据。此外,由于其对科学多模态元素的精确理解,Uni-Finder 在科学文献的内容理解和问答方面的性能也优于其他大型语言模型。
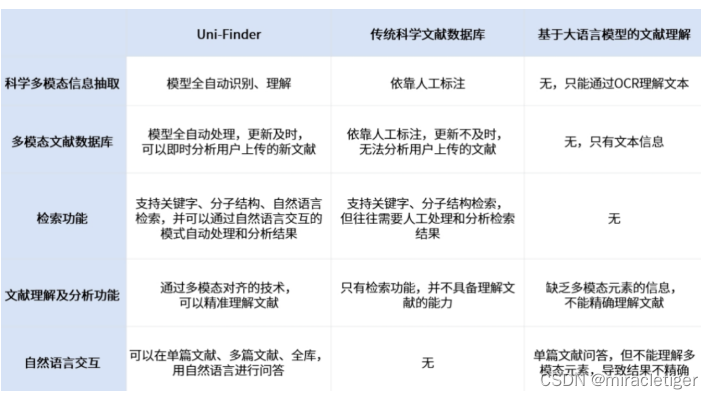
Uni-Finder 的核心技术是深势科技自研的科学多模态大模型 Uni-SMT(Universal Science Multimodal Transformer)。不同于之前仅关注纯文本的大型语言模型,Uni-SMT 综合考虑了科学文献中的多模态元素,如图表、数学方程、分子结构表示和化学反应方程式等。它运用多模态对齐技术,实现了对科学文献的更全面和精确理解。例如,对于某些专利,Uni-SMT 能够通过多模态对齐技术同时理解 markush 式(带有可变基团的化学分子式)和文本中对可变基团的描述,从而精确地识别和解析专利的保护范围。
产品使用场景:助力药物研发
随着信息时代文献数量的激增,科研人员在文献阅读和分析上花费大量时间,这影响了他们专注于核心研究的时间。Uni-Finder 应运而生,融合先进的多模态文献理解和灵活的自然语言处理技术,极大地提高了文献检索和分析效率。借助 Uni-Finder,科研人员可更高效处理科学文献,节省宝贵时间,集中精力解决科研难题。在一个模拟药物研发场景中,我们演示了 Uni-Finder 如何有效提高研究效率。研究人员关注 SOS1 靶点时,可通过 Uni-Finder 查询 SOS1 相关疾病和结直肠肿瘤信息。这为他们提供了关键科学知识,为后续研发工作打下了坚实基础。研究人员还可利用 Uni-Finder 的高级检索功能深入探索。选择「SOS1」靶点标签后,Uni-Finder 快速展示相关专利,证明了其在精准检索和信息筛选上的卓越性能。接着,研究人员对市场和科研趋势进行了全面分析。他们查看过去 10 年 SOS1 靶点的专利趋势,获取了市场动态和竞争环境的深刻洞察,辅助研发策略制定。通过 Uni-Finder 的跨文献分析,如骨架聚类,他们了解了该领域的最新进展和创新方向,为新药设计和开发提供了科学指引。最后,研究人员可深入分析特定专利。他们可以方便地审视保护的分子结构,提取高活性的实施例,并详细查看了特定实施例的信息。值得一提的是,通过上传分子结构图,并与 Uni-Finder 进行互动式对话,研究人员能够准确判断特定分子是否受当前专利保护。这一系列复杂分析突显了 Uni-Finder 在药物研发领域的强大实用性。
https://www.geekpark.net/news/327663


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









