






一、问题描述
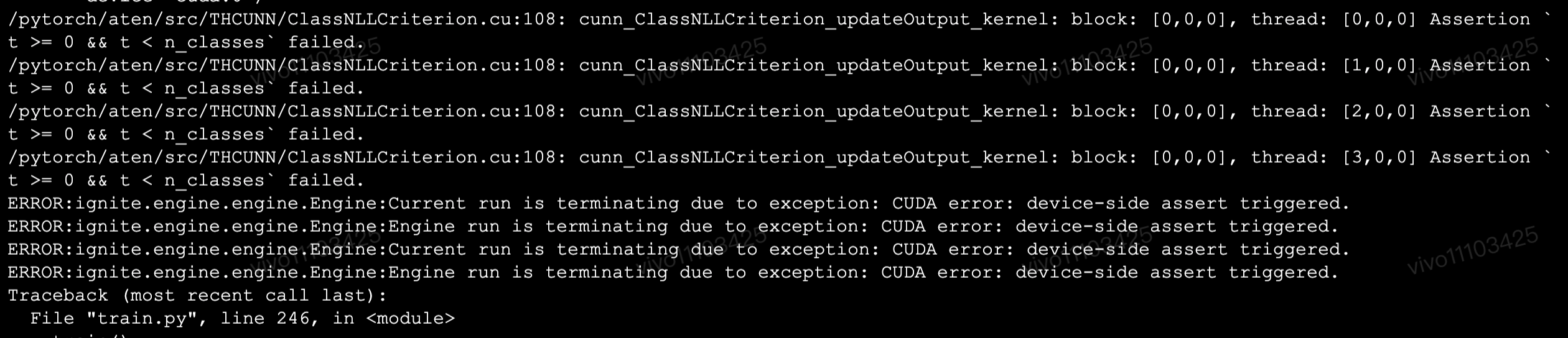
关键错误为:
ClassNLLCriterion_updateOutput_no_reduce_kernel: block: [0,0,0], thread: [1,0,0] Assertion `cur_target >= 0 && cur_target < n_classes` failed.
二、问题排查
1、训练使用的model是transformers.OpenAIGPTLMHeadModel,对应的参数:

关键错误为:
ClassNLLCriterion_updateOutput_no_reduce_kernel: block: [0,0,0], thread: [1,0,0] Assertion `cur_target >= 0 && cur_target < n_classes` failed.
1、训练使用的model是transformers.OpenAIGPTLMHeadModel,对应的参数:

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























