






摘要
对比学习被广泛用于训练基于变换器的视觉语言模型,用于视频文本对齐和多模态表示学习。本文提出了一种新的算法,称为TACo,该算法利用两种新技术改进了对比学习。第一种是标记感知对比损失,它是通过考虑单词的句法类别来计算的。这是因为观察到,对于视频-文本对,文本中的内容词(如名词和动词)比虚词更可能与视频中的视觉内容对齐。其次,采用级联采样方法生成一组小的硬负示例,用于有效估计多模态融合层的损耗。为了验证TACO的有效性,在我们的实验中,我们对一组下游任务的预训练模型进行了微调,包括文本视频检索(YouCook2、MSR-VTT和ActivityNet)、视频动作步骤定位(CrossTask)、视频动作分段(COIN)。结果表明,与以前的方法相比,我们的模型在不同的实验环境中取得了一致的改进,在YouCook2、MSR-VTT和ActivityNet三个公共文本视频检索基准上建立了最新的技术水平。
介绍
在视觉语言(VL)研究的背景下,将语言与视频对齐或根植是一个具有挑战性的主题,因为它需要模型来理解视频[3]中的内容、动态和因果关系。受BERT在自然语言处理中的成功启发,将基于变换的多模态模型应用于视频文本对齐和表示学习越来越有兴趣。这些模型通常使用对比学习对大量有噪声的视频-文本对进行预处理,然后以零镜头的方式应用或微调用于各种下游任务,如文本-视频检索[51]、视频动作步骤定位[60]、视频动作分割[42]、视频问题回答[43,26]和视频字幕[57]。
在本文中,我们提出了一种新的对比学习变体,即Token-AwareCascade对比学习(TACo),以改进大规模预培训和下游特定任务的视频文本对齐。顾名思义,TACo对视频语言领域的传统对比学习进行了两次修改。第一种是标记感知对比损失,它是通过考虑单词的句法类别来计算的。这是因为观察到,给定视频及其相应的文本,内容词(如名词和动词)比虚词更有可能与视频中的视觉内容对齐(或基于视觉内容)。传统的对比学习通常在将文本中的所有单词和视频中的帧进行聚合后计算损失(图1中的lossl1orl3)。相反,标记感知对比损失仅使用其语法类别属于预定义集合的单词子集(例如,名词和动词)计算,这迫使单个单词与视频相关联(lossL2)。例如,我们特别注意图1中的“添加”、“番茄”、“平底锅”和“搅拌”。
我们介绍的第二种技术是一种级联采样方法,以找到一小组硬否定示例来训练多模态融合层。考虑一批k video -text对。对于每一个视频-文本对,理想的情况是我们使用剩余的k−1负视频或文本计算多模态融合后的对比度损失。然而,考虑到其高度的复杂性yo (K2×L2),其中包含视觉和文本标记的总数量,当与多模态融合层耦合时,计算对比损失的成本很快就变得令人望而却步。解决这个问题的传统方法是使用随机抽样来选择一小部分负对。在本文中,我们提出了如图1右上角所示的级联采样方法来代替随机采样,以便在训练过程中有效地选择一小组难的反例。它利用了在多模态融合层之前在L1andL2中计算的视频文本对齐得分,并帮助在没有任何额外开销的情况下更有效地学习多模态融合层。
硬负开采: 关于hard mining,比较生动的例子是高中时期你准备的错题集。错题集不会是每次所有的题目你都往上放。放上去的都是你最没有掌握的那些知识点(错的最厉害的),而这一部分是对你学习最有帮助的。
hard negative就是每次把那些顽固的棘手的错误,再送回去继续练,练到你的成绩不再提升为止.这一个过程就叫做’hard negative mining’.
方法
框架
视频编码模块fθv。它是由θv参数化的一堆自我注意层实现的。这里,我们假设输入视频特征已经使用一些预先训练过的模型提取出来,例如2D CNN(例如ResNet[18])或3D CNN(例如I3D[4],S3D[50])。给定输入的视频嵌入,视频编码器从一个线性层开始,将它们投影到与自关注层相同的维度。我们用一系列特征x={x1,…,xm}表示视频剪辑的视频编码器的输出∈Rm×d。特性的数量取决于采样帧速率和视频特性提取器的选择,我们将在第节中讨论。4.
语言编码模块fθt。我们分别使用预训练标记器[47]和BERT[10]来标记输入文本和提取文本特征。给定一个原始句子,我们在开头和结尾分别加上“[CLS]”和“[SEP]”。在顶部,我们可以获得一系列文本特征={y1,…,yn}∈ Rn×d。我们确保视频编码器的输出特征维数与语言编码器的输出特征维数相同。在训练过程中,我们更新语言编码器中的参数θ,以适应特定领域的文本,例如。GY ouCook2中的烹饪说明[57]。
3.3.TACo: our approach
- we compute the sentence-level contrastive loss:.
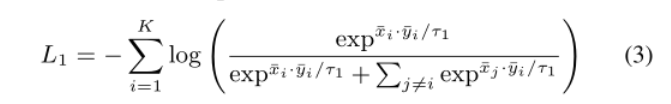
2.除了句子级别的损失,我们引入了一个令牌级别的对比损失:
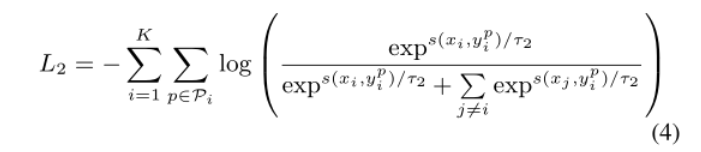
3.令牌的感兴趣程度:
在实践中,即使属于同一类型的名词或动词,它们的鉴别力也往往不同。例如,“man”是一个名词,但它的信息量不如“gymnast”。为了反映这一点,我们进一步通过计算它们的逆文档频率(idf)[21]来赋予不同的单词不同的权重。较高的idf意味着它在整个语料库中更独特,因此在计算令牌级别的对比损失时更有分量。计算损失的另一个实际问题是,由于BERT记号发生器,记号通常是子词。因此,对于属于同一个单词的所有标记,我们将相应地分配相同的权重。
在计算了标记感知的对比损失之后,我们将来自不同模态的特征输入到多模态融合层中,以实现它们之间的更多交互。与之前的工作[59]类似,我们采用与(m+n)输出中的“[CLS]”对应的特性。我们认为这是两种模式的总结,然后计算对比损失:
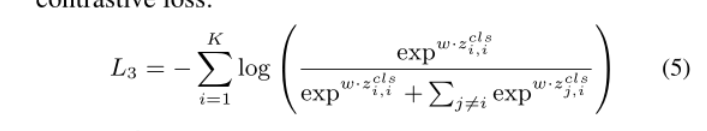
.
在Eq.5中,一个实际的挑战是我们很难在小批量中使用所有(K−1)负样本,因为在多模态融合中计算和存储成本很高。自注意层的o (d(m+n)2)复杂性使得无法将allK×Kpairs传递到多模态层中。之前的工作解决了这个问题,通过进行随机抽样,将负样本的数量减少到toK0。然而,随机选择负样本可能会导致次优学习,因为对是稀缺的。因此,我们引入一种级联抽样策略来寻找硬负,而不是随机负。
4.级联硬负抽样
为了降低方程5中的计算成本,我们从所有可能的视频文本对中选择一个最困难的子集。然而,使用eq .5计算所有对的对齐得分,然后选择硬否定是一个“先有鸡还是先有蛋”的问题。相反,我们建议使用在等式3和等式4中计算的所有视频-文本对之间的相似性作为指导。具体来说,对于每个文本-视频对(vj, ti),我们将它们的全局相似度¯xj·¯yic计算在等式3中,并将p p∈Pis(xj, yp i)对所有感兴趣的令牌inti进行聚合,得到令牌级别相似度。然后我们将这两个相似点相加,作为给定配对的对齐得分。对于每个文本,我们选择topk0对齐的负面视频,反之亦然。然后将得到的2k× (K0+ 1)对送入多模态融合层。通过这种策略,我们可以在不增加额外成本的情况下,有效地在动态中选择困难的阴性样本。由于多模态融合层具有更大的能力(参数)来区分这些硬负极和正负极,我们的采样策略自然地促进了三种对比损失之间的合作。最后,我们对表1中使用的对比学习方法进行了综合比较,以区分我们的模型与之前的工作。
目标
我们方法的训练目标是通过最小化上述三种对比损失的组合来找到最佳θ={θv, θt, θm}:
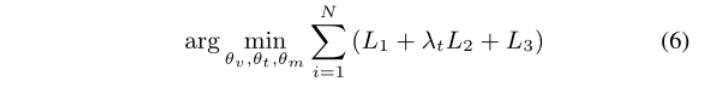
结论
在本文中,我们介绍了一种简单而有效的视频文本对齐对比学习方法Taco。它旨在解决当前对比学习管道中存在的两个问题:缺少细粒度对齐和多模态融合的低效采样。在不引入任何额外参数的情况下,我们的方法在不同评估协议下的三个文本视频检索基准上取得了令人满意的结果。我们进一步证明,学习到的表示可以有效地转移到其他任务,如动作步骤定位和分割。基于所有这些令人鼓舞的结果,我们相信TACOIS是传统对比学习管道的一个很好的替代品。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









