







好久没有写博客了,今天分享一篇新的目标跟踪论文。最后更新日期:2020.08.03
论文链接:https://arxiv.org/abs/2007.02024
代码链接:https://github.com/MasterBin-IIAU/AlphaRefine 2020.08.03作者目前还没发布
摘要:目前的目标跟踪算法大多采用多阶段(multiple-stage)的策略,即先对目标进行粗定位,再利用refinement modules对目标进行精细定位。作者认为现有的refinement modules的可移植性和准确性较差,因此作者提出了一种更为准确灵活的refinement module——Alpha-Refine,也就是本文的主角啦。Alpha-Refine利用pixel-wise correlation和spatial-aware non-local层来融合特征,并且可以预测出三种输出:bounding box、corners和mask。那么利用哪个输出结果作为最终的跟踪结果呢?作者在此提出了一个轻量的branch selector module进行选择。作者在现在大热的DiMP、ATOM、SiamRPN++、RTMDNet和ECO算法上进行了大量的实验,表明了所提模块的有效性。
引言:准确的目标尺度估计对于目标跟踪是十分重要的,早期的跟踪器通过多尺度搜索(multi-scale search,如SiameseFC、UPDT、ECO)或先抽样后回归的方法进行尺度估计,这些方法准确度不够高。近些年,有很多表现很好的新尺度估计方法,如DiMP和ATOM中的IoUNet、SiamMask等。
作者所提出的回归模块是单独训练好的,因此可以即插即用!!即插即用!!即插即用!!
不想了解相关工作的可以跳过这段,直接看方法!
相关工作:
- 现在的尺度估计:现有的高性能尺度估计方法包括RPN-based、Mask-based、IoU-based和Anchor-free-based四类。RPN-based方法学习region proposal网络,该网络判断当前anchor是否为目标,并对anchor回归。相比之下,Mask-based类方法更为准确。IoU-based类方法学习一个能够预测候选bbox和groundtruth之间重叠度的网络。Anchor-free-based类方法。。。
- 回归模块:DiMP和ATOM中的IoU-Net是可以单独训练的,可移植性较好,但精度有待提升。SiamMask方法也可以和任何跟踪器结合。
Alpha-Refine:单目标跟踪任务可以被分解为目标定位和尺度估计两部分。在本文的工作中,基准跟踪器用于定位目标,Alpha-Refine用于准确的尺度估计。当基准跟踪器获得粗略的跟踪结果后,裁剪跟踪结果的两倍大小作为搜索区域,并输入Alpha-Refine,然后Alpha-Refine输出更为准确的bbox作为最终跟踪的结果。下一帧将基于上一帧的结果剪裁搜索区域。
网络结构:Alpha-Refine有两个输入分支:reference分支和test分支。这两个分支分别以第一帧和当前帧中的搜索区域为输入,主干网络为参数共享(啥意思?)的ResNet-50。特征提取后,利用PrRoI Pooling层获得reference分支的目标特征。现有的方法大多采用correlation或depth-wise correlation来融合特征,Alpha-Refine则利用pixel-wise correlation和spatial-aware non-local层来整合特征,从而获得由reference引导的目标特征。此外,跟踪结果有三种输出类型:bounding box、corners和mask,利用branch selector进行选择。网络结构如Figure1所示。
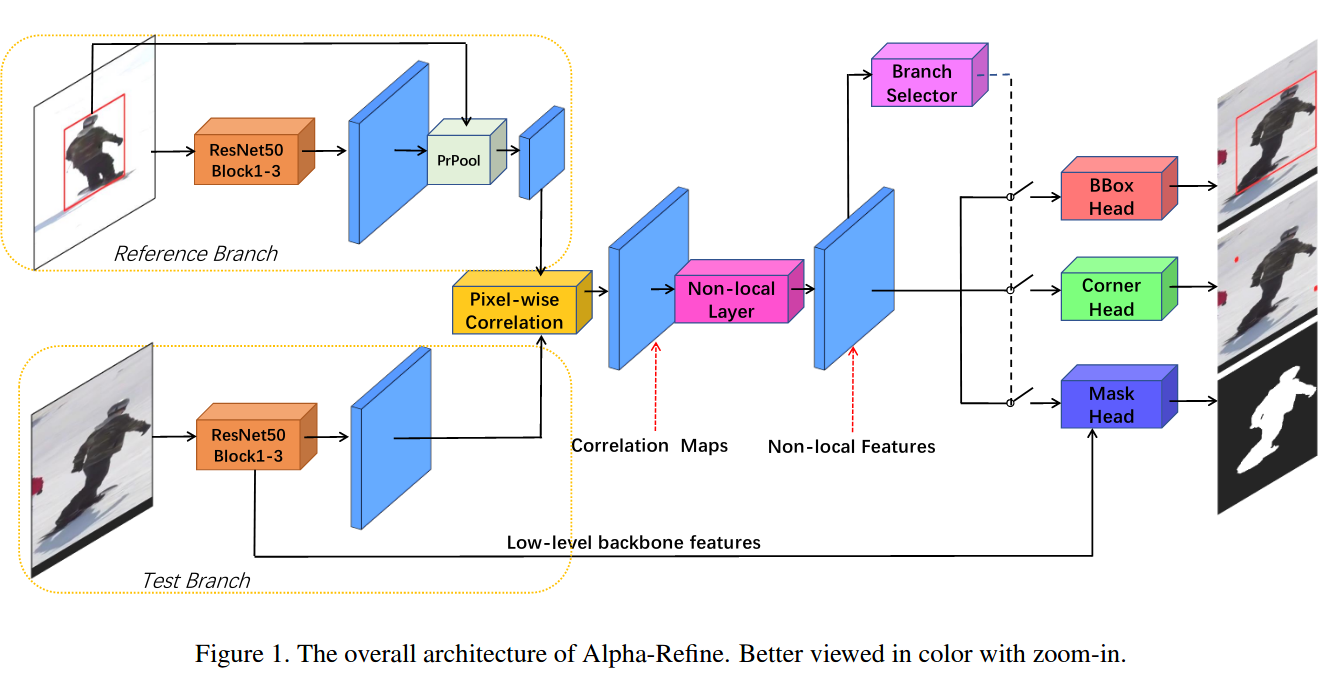
特征聚合:
1、准确的Pixel-wise Correlation:设和
分别为模板(template)和搜索区域
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3491
3491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









