







- 简介
redo log 它是物理日志,记录内容是“在某个数据页上做了什么修改”,属于 InnoDB 存储引擎。redo log(重做日志)是InnoDB存储引擎独有的,它让MySQL拥有了崩溃恢复能力。 比如 MySQL 实例挂了或宕机了,重启时,InnoDB存储引擎会使用redo log恢复数据,保证数据的持久性与完整性。 - 刷盘策略
InnoDB 存储引擎为 redo log 的刷盘策略提供了 innodb_flush_log_at_trx_commit 参数,它支持三种策略:
① 0 :设置为 0 的时候,表示每次事务提交时不进行刷盘操作。
② 1 :设置为 1 的时候,表示每次事务提交时都将进行刷盘操作(默认值)。
③ 2 :设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache。
innodb_flush_log_at_trx_commit 参数默认为 1 ,也就是说当事务提交时会调用 fsync 对 redo log 进行刷盘 另外,InnoDB 存储引擎有一个后台线程,每隔1 秒,就会把 redo log buffer 中的内容写到文件系统缓存(page cache),然后调用 fsync 刷盘。除了后台线程每秒1次的轮询操作,还有一种情况,当 redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时候,后台线程会主动刷盘。 - 日志文件组
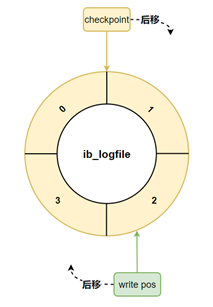
硬盘上存储的 redo log 日志文件不只一个,而是以一个日志文件组的形式出现的,每个的redo日志文件大小都是一样的。 比如可以配置为一组4个文件,每个文件的大小是 1GB,整个 redo log 日志文件组可以记录4G的内容。 它采用的是环形数组形式,从头开始写,写到末尾又回到头循环写,如下图所示。

在个日志文件组中还有两个重要的属性,分别是 write pos、checkpoint。write pos 是当前记录的位置,每次刷盘 redo log 记录到日志文件组中,write pos 位置就会后移更新。checkpoint 是当前要擦除的位置,每次 MySQL 加载日志文件组恢复数据时,会清空加载过的 redo log 记录,并把 checkpoint 后移更新。write pos 和 checkpoint 之间的还空着的部分可以用来写入新的 redo log 记录。
如下图所示,以顺时针为正方向,在write pos正方向和checkpoint负方向之间的部分可以用来写入新的 redo log 记录。
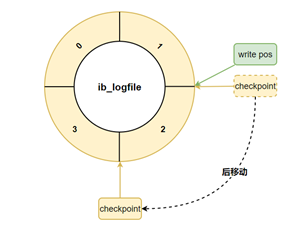
如果 write pos 追上 checkpoint ,表示日志文件组满了,这时候不能再写入新的 redo log 记录,MySQL 得停下来,清空一些记录,把 checkpoint 推进一下。
- redo log的优势
现在我们来思考一个问题: 只要每次把修改后的数据页直接刷盘不就好了,还有 redo log 什么事?它们不都是刷盘么?差别在哪里?
实际上,数据页大小是16KB,刷盘比较耗时,可能就修改了数据页里的几 Byte 数据,有必要把完整的数据页刷盘吗? 而且数据页刷盘是随机写,因为一个数据页对应的位置可能在硬盘文件的随机位置,所以性能是很差。 如果是写 redo log,一行记录可能就占几十 Byte,只包含表空间号、数据页号、磁盘文件偏移量、更新值,再加上是顺序写,所以刷盘速度很快。 所以用 redo log 形式记录修改内容,性能会远远超过刷数据页的方式,这也让数据库的并发能力更强。















 1771
1771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









