







一.概述
- 大数据领域分类
- 离线处理
- 实时处理
- 大数据开发瓶颈
- IO
- 绝大多数的瓶颈都卡在这里
- 计算
- 一般涉及到深度学习,人工智能等领域会遇到计算瓶颈,一般放在GPU上去跑
- IO
- spark
- mapreduce遇到的瓶颈
- 操作类型有限,仅支持map和reduce两种操作
- 编程复杂较高,学习成本高
- 处理效率低
- map中间结果xie磁盘,reduce结果xiehdfs,多个mr之间通过hdfs交换数据
- 任务调度和启动开销比较大
- 在机器学习,图计算方面支持有限,性能较差
- 定义:一个快速通用的大数据计算引擎
- 特点
- 速度快
- 内存计算下,比hadoop快100倍
- 易用:
- 有80多个高级的运算符
- 跨语言
- 通用性
- spark提供了大量的库,不同语言的开发者可以无缝的使用这些库
- 支持多种资源管理器
- 例如 yarn,mesos,及其自身自带的集群资源管理器
- 组件丰富
- spark streaming 实时数据处理
- sparkSQL 使用sql语句操作spark引擎
- sparkR: r语言操作spark引擎
- mlib: 机器学习的算法库
- graphx: 图计算库
- 速度快
- mapreduce遇到的瓶颈
二.生态圈
在hadoop生态圈的地位
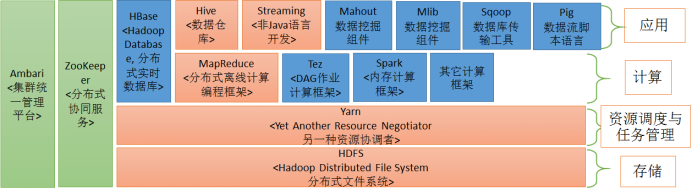
spark自己的生态圈

三.版本与就业前景
- 发展历程
- 2009年创立于伯克利大学
- 最新版本3版本
- 较为成熟的版本 2.3
- spark1和spark2的比较
- 优点:
- API更加抽象统一
- 统一DataFrames和DataSets为DataSets,API进行了全部统一
- 基本定位是低层API编程延用RDD,高级API编程均为DataSets,而大多数情况下用DataSets均可以解决问题。
- spark-streaming基于spark sql进行了API更高级抽象
- 对诸多组件中的旧的rdd计算逻辑用DataFrame或DataSet进行了重写优化,并扩充了更多的算法。
- 缺点
- 对以前版本不是完全兼容,只是绝大部分兼容。
- 相对于1.6.x来讲,稳定性略差
- 就业前景
- 岗位需求量和发展前景都很广阔,是未来3-5年的技术应用最大热门
- 优点:
















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











