







一.介绍
产生背景: web2.0时代到来,大量的数据需要处理,单机处理已经不能满足需求,分布式存储与计算进入历史舞台
是什么:是一个面向大数据处理的计算框架
基本特点:提供可靠的分布式计算,封装了细节开发流程简单,跨语言
二.运行流程



premap阶段
首先根据输入的文件,进行切片,一个block块就是一片
其中的每一片都会分配给一个map任务
一个计算节点可以并行执行多个map任务
分片完成后要按照回车符号进行kv格式化,k是字节偏移量,v是内容
map阶段
数据处理 Mapper
比如说将分片的数据的每行按照逗号分割
一个分片会产生一个map任务
一个map任务中会调用多次map方法(多少行就调用一次,map方法是按照行来进行处理的)
分区parttion
默认系统分区的代码如下:
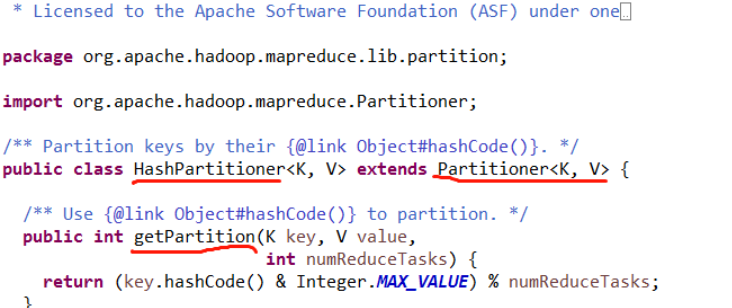
map处理后的key的hash值与上int的最大值,然后模上reduce节点的数量
分区的目的:将kv对儿均匀的发送到reduce节点上,使得reduce节点负载均衡
排序 sort
分区完成后进行排序,按照key进行排序
本地合并 combiner(可选,一般计算平均值的时候不进行这部操作)
排序完成后,按照key相同的进行合并,value合并成一个可迭代的集合
一般在计算平均值的时候不进行这步操作,因为combiner实际上也是调用的reduce类的方法,也会进行局部的求平均,最后结果会变成将多个局部平均再求平均,结果就错了
将结果输出到本地
shuffle阶段
将各个节点上相同分区的数据进行合并然后排序
reduce阶段
该阶段会将key相同的进行合并,这个和combiner一样
合并完了执行reduce方法
每个reduce都会在产生对应的结果文件(hdfs文件)
三.案例
1.单词统计
需求分析
在 hdfs 目录/tmp/tianliangedu/input/wordcount 中有一系列文件,内容均为",“号分隔,
求按”,"号分隔的各个元素的出现频率,输出到目录/tmp/tianliangedu/output/个人用户名的 hdfs
目录中。map
package com.fjh.mapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.stream.Stream;
/**
* @author Antg
* @date 2021/10/7 18:01
*/
public class Mapper01 extends Mapper<Object, Text,Text, IntWritable> {
//为了节省空间,这里将每个第一次分割开的单词频率记为1
private final static IntWritable one =new IntWritable(1);
//暂时存储每个分割开的单词,节省空间
private Text word = new Text();
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//将单词按照逗号分割开来
String[] splitResult = value.toString().split(",");
//循环将每个单词存储进context对象中
for(String e:splitResult){
word.set(e);
context.write(word,one);
}
}
}reduce
package com.fjh.reduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Antg
* @date 2021/10/7 18:09
*/
public class Reduce01 extends Reducer<Text, IntWritable,Text, IntWritable> {
private IntWritable result = new IntWritable();
//将map传来的结果进行合并
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//统计每个单词出现的频率
for (IntWritable val : values) {
//将 key 组中的每个词频数值 sum 到一起
sum += val.get();
}
result.set(sum);
//结果逐条输出
context.write(key,result);
}
}2.求和
需求分析
在 hdfs 目录/tmp/tianliangedu/input/wordcount 目录中有一系列文件,内容为","号分
号分
隔,分隔后的元素均为数值类型、字母、中文,求所有出现的数值的和。
map
package com.fjh.mapper;
import com.fjh.util.RegexUtil;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* @author Antg
* @date 2021/10/7 18:01
*/
public class Mapper02 extends Mapper<Object, Text, Text, LongWritable> {
@Override
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
for(String e:split){
if(RegexUtil.matchNum(e)){
context.write(new Text("求和结果:"),new LongWritable(Long.parseLong(e)));
}
}
}
}reduce
package com.fjh.reduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* @author Antg
* @date 2021/10/7 18:09
*/
public class Reduce02 extends Reducer<Text, LongWritable,Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//统计每个单词出现的频率
for (LongWritable val : values) {
//将 key 组中的每个词频数值 sum 到一起
sum += val.get();
}
result.set(sum);
//结果逐条输出
context.write(key,result);
}
}3.driver类
package com.fjh;
import com.fjh.mapper.*;
import com.fjh.reduce.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 1-8练习题主函数入口
* @author Antg
* @date 2021/10/7 17:36
*/
public class Main {
//获取配置
public static final Configuration conf = new Configuration();
/**
* 参数一:作业的顺序1-8数字
* */
public static void main(String[] args) throws Exception {
//任务名称
String jobName = "付君华-作业"+args[0];
//根据同的参数创建不同的任务
switch (args[0]){
case "1":
System.out.println("作业1--------->");
workDriverSchedule(jobName, Reduce01.class,Mapper01.class,Reduce01.class, Text.class, IntWritable.class,args[1],args[2]);
break;
case "2":
System.out.println("作业2--------->");
workDriverSchedule(jobName, null, Mapper02.class,Reduce02.class, Text.class, LongWritable.class,args[1],args[2]);
break;
case "3":
System.out.println("作业3--------->");
workDriverSchedule(jobName, null, Mapper03.class, Reduce03.class, Text.class, LongWritable.class,args[1],args[2]);
break;
case "4":
System.out.println("作业4--------->");
workDriverSchedule(jobName, Reduce04.class, Mapper04.class, Reduce04.class, Text.class, IntWritable.class,args[1],args[2]);
break;
case "5":
System.out.println("作业5--------->");
workDriverSchedule(jobName, null, Mapper05.class, Reduce05.class, Text.class, IntWritable.class,args[1],args[2]);
break;
case "6":
System.out.println("作业6--------->");
workDriverSchedule(jobName, null, Mapper06.class,Reduce06.class, Text.class, IntWritable.class,args[1],args[2]);
break;
case "7":
System.out.println("作业7--------->");
workDriverSchedule(jobName, null, Mapper06.class,Reduce06.class, Text.class, IntWritable.class,args[1],args[2]);
break;
case "8":
System.out.println("作业8--------->");
break;
default:
System.out.println("第一个参数错误,范围1-8");
break;
}
}
public static void workDriverSchedule(String jobName,Class combinerClass,Class mapClass,Class reduceClass,Class jobOutputKeyClass,Class jobOutputValueClass,String inputFilePath,String outputFilePath) throws Exception {
//创建任务
Job job =Job.getInstance(conf,jobName);
//指定执行主类
job.setJarByClass(Main.class);
//指定map类
job.setMapperClass(mapClass);
//如果有combiner类就指定combiner类
if(combinerClass!=null){
job.setCombinerClass(combinerClass);
}
//指定reduce类
job.setReducerClass(reduceClass);
//指定输出结果的key的类型
job.setOutputKeyClass(jobOutputKeyClass);
//指定输出结果的value的类型
job.setOutputValueClass(jobOutputValueClass);
//指定输入文件路径
//修改成多输入的(多个输入用逗号分割)
String[] input = inputFilePath.split(",");
for(String filePath:input){
FileInputFormat.addInputPath(job,new Path(filePath));
}
//指定输出结果文件路径
FileOutputFormat.setOutputPath(job,new Path(outputFilePath));
//指定job执行模式(等待任务执行完成后,提交任务的客户端才会退出!)
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











