







数据库高级
🌾第三章 数据库高级
🕊️3.1 数据完整性
🍵1 数据库的完整性
用来保证存放到数据库中的数据是有效的,即数据的有效性和准确性确保数据的完整性 = 在创建表时给表中添加约束
完整性的分类:
- 实体完整性(行完整性):
- 域完整性(列完整性):
- 引用完整性(关联表完整性):
主键约束:primary key
唯一约束:unique [key]
非空约束:not null
默认约束:default
自动增长:auto_increment
外键约束: foreign key
建议这些约束应该在创建表的时候设置多个约束条件之间使用空格间隔
示例:
create table student(
studentno int primary key auto_increment,
loginPwd varchar(20) not null default '123456',
studentname varchar(50) not null,
sex char(2) not null,
gradeid int not null,
phone varchar(255) not null,
address varchar(255) default '学生宿舍',
borndate datetime,
email varchar(50)
);
🍵2 实体完整性
实体:即表中的一行(一条记录)代表一个实体(entity)
实体完整性的作用:标识每一行数据不重复。
约束类型:
- 主键约束(primary key)
- 唯一约束(unique)
- 自动增长列(auto_increment)
主键约束(primary key)
特点:数据唯一,且不能为null,每个表中要有一个主键。
示例:
第一种添加方式:
CREATE TABLE student( id int primary key, name varchar(50) );
第二种添加方式:此种方式优势在于,可以创建联合主键
CREATE TABLE student( id int, name varchar(50), primary key(id) );
CREATE TABLE student( classid int, stuid int, name varchar(50), primary key(classid,stuid) );
第三种添加方式:
CREATE TABLE student( id int, name varchar(50) );
ALTER TABLE student ADD PRIMARY KEY (id);
唯一约束(unique)
特点:数据不能重复。
CREATE TABLE student( Id int primary key, Name varchar(50) unique );
自动增长列(auto_increment)
sqlserver数据库 (identity-标识列)
oracle数据库(sequence-序列)
给主键添加自动增长的数值,列只能是整数类型
CREATE TABLE student( Id int primary key auto_increment, Name varchar(50) );
INSERT INTO student(name) values(‘tom’);
🍵3 域完整性
域完整性的作用:限制此单元格的数据正确,不对照此列的其它单元格比较,域代表当前单元格
域完整性约束:数据类型 非空约束(not null) 默认值约束(default)
check约束(mysql不支持)check(sex=‘男’ or sex=‘女’)
create table student(
studentno int primary key auto_increment,
gradeid int not null,
address varchar(255) default '学生宿舍',
);
🍵4 引用完整性-关联表完整性
外键约束:foreign key
constraint 自定义外键名称 foreign key(外键列名) references 主键表名(主键列名)
示例:
第一种添加外键方式。
create table student(
id int primary key,
name varchar(50) not null, sex
varchar(10) default '男' );
create table score(
id int primary key,
score int,
sid int ,
constraint fk_score_sid foreign key(sid) references student(id) );
外键列的数据类型一定要与主键的类型一致
第二种添加外键方式。
alter table score add constraint fk_stu_score foreign key(sid) references stu(id);
🕊️3.2 多表查询
多个表之间是有关系的,那么关系靠谁来维护?
多表约束:外键列
🍵1 多表的关系
一对一关系
在实际的开发中应用不多.因为一对一可以创建成一张表.
两种建表原则:
唯一外键对应:假设一对一是一个一对多的关系,在多的一方创建一个外键指向一的一方的主键,将外
键设置为unique.
主键对应:让一对一的双方的主键进行建立关系
一对多/多对一关系
客户和订单,分类和商品,部门和员工。
一对多建表原则:在多的一方创建一个字段,字段作为外键指向一的一方的主键
多对多关系
学生和课程
多对多关系建表原则:需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键。
🍵2 多表查询分类
多表查询有如下几种:
-
合并结果集:
union、union all -
连接查询
-
内连接
[inner] join on -
外连接
outer join on- 左外连接
left [outer ] join - 右外连接
right [outer ] join - 全外连接(
MySQL不支持)full join
- 左外连接
-
自然连接
natural join
-
-
子查询
🍃1. 合并结果集
作用:合并结果集就是把两个select语句的查询结果合并到一起!
合并结果集有两种方式:
union:去除重复记录,例如:select * from t1 union select * from t2
union all:不去除重复记录,例如:select * from t1 union all select * from t2
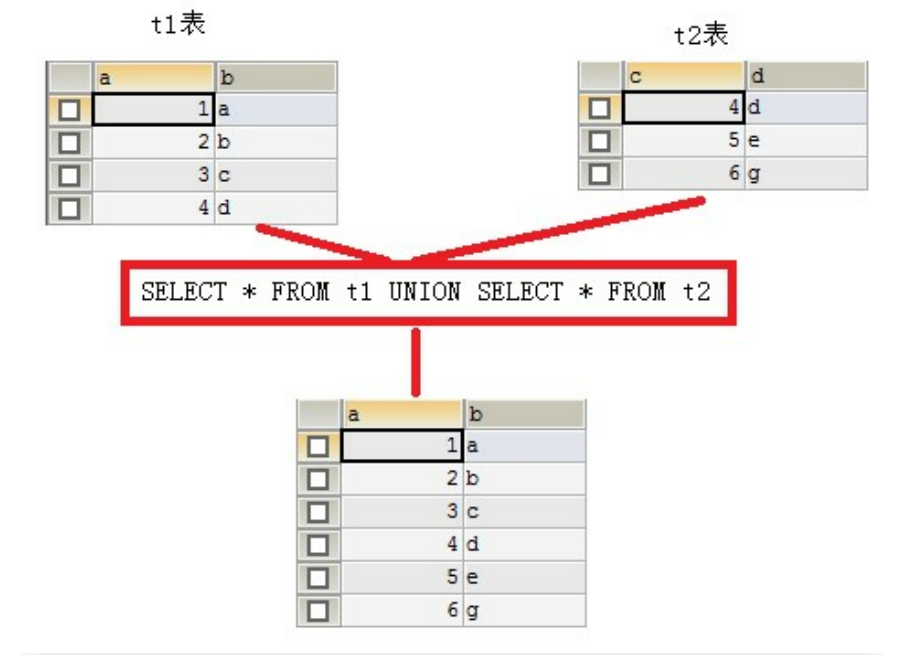
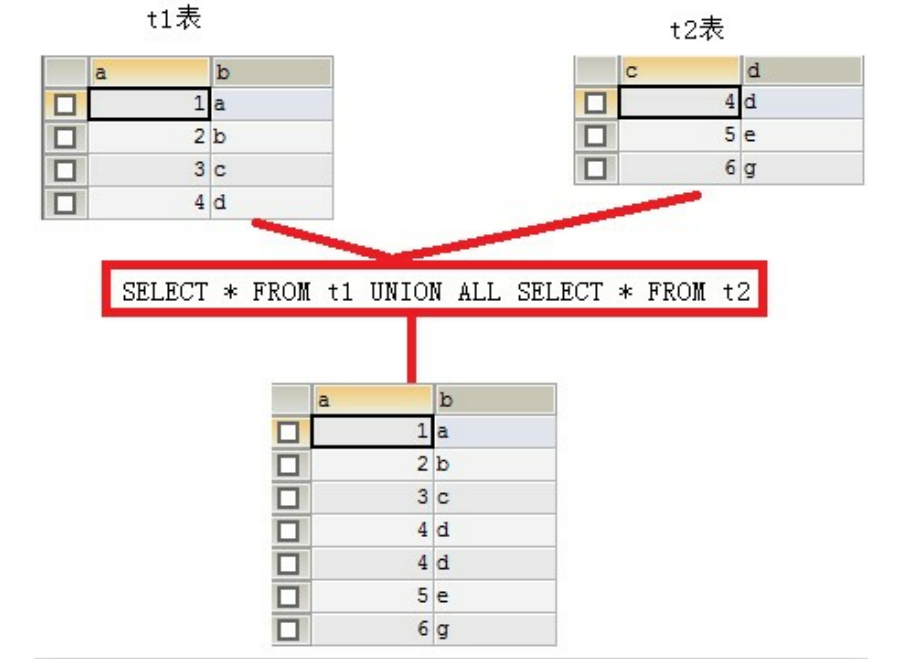
注意:被合并的两个结果:列数、列类型必须相同。
🍃2 连接查询
连接查询就是求出多个表的乘积,例如t1连接t2,那么查询出的结果就是t1*t2。
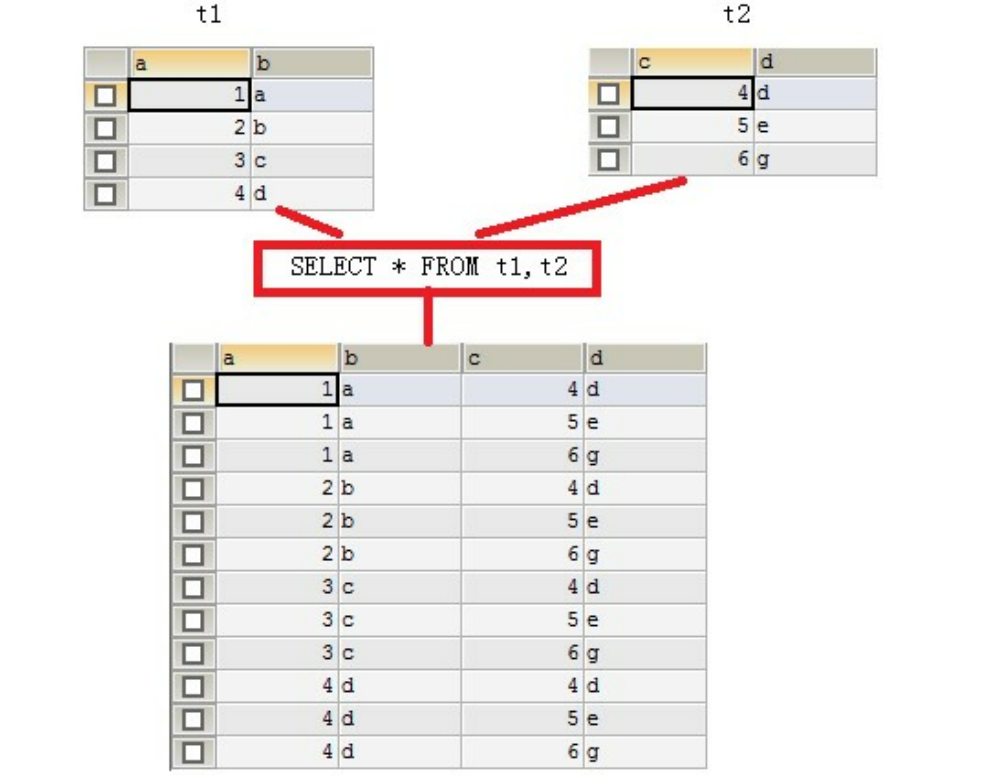
连接查询会产生笛卡尔积,假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),
(a,2),(b,0),(b,1),(b,2)}。可以扩展到多个集合的情况。
那么多表查询产生这样的结果并不是我们想要的,那么怎么去除重复的,不想要的记录呢,当然是通过
条件过滤。通常要查询的多个表之间都存在关联关系,那么就通过关联关系去除笛卡尔积。
示例 1:现有两张表
emp-员工表,dept-部门表
CREATE TABLE dept1(
deptno int primary key,
dname varchar(14),
loc varchar(13)
);
insert into dept1 values(10,'服务部','北京');
insert into dept1 values(20,'研发部','北京');
insert into dept1 values(30,'销售部','北京');
insert into dept1 values(40,'主管部','北京');
CREATE TABLE emp1(
empno int,
ename varchar(50),
job varchar(50),
mgr int,
hiredate date,
sal double,
comm double,
deptno int
);
insert into emp1 values(1001,'张三','文员',1006,'2019-1-1',1000,2010,10);
insert into emp1 values(1002,'李四','程序员',1006,'2019-2-1',1100,2000,20);
insert into emp1 values(1003,'王五','程序员',1006,'2019-3-1',1020,2011,20);
insert into emp1 values(1004,'赵六','销售',1006,'2019-4-1',1010,2002,30);
insert into emp1 values(1005,'张猛','销售',1006,'2019-5-1',1001,2003,30);
insert into emp1 values(1006,'谢娜','主管',1006,'2019-6-1',1011,2004,40);
select * from emp,dept;
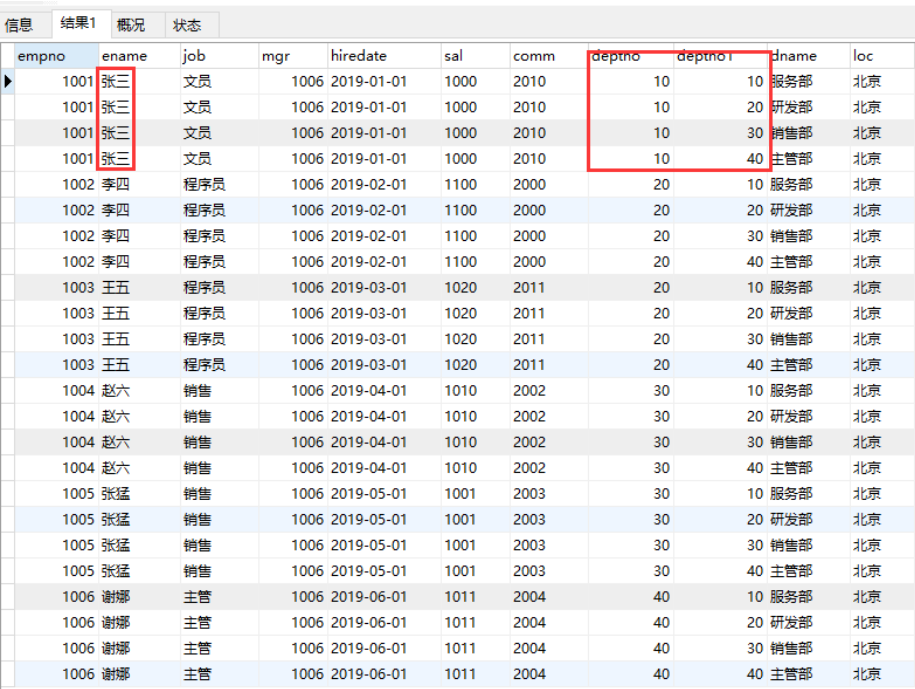
结果如上,出现笛卡尔集
解决:使用主外键关系做为条件来去除无用信息
select * from emp,dept1 where emp1.deptno=dept1.deptno;
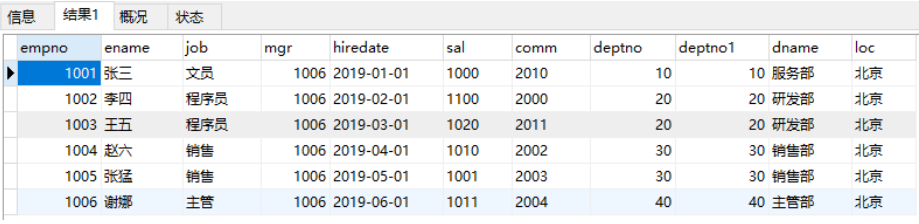
上面查询结果会把两张表的所有列都查询出来,也许你不需要那么多列,这时就可以指定要查询的列
了。
select emp1.ename,emp1.sal,emp1.comm,dept1.dname from emp1,dept1 where emp1.deptno=dept1.deptno;

内连接
上面的连接语句就是内连接,但它不是SQL标准中的查询方式,可以理解为方言!
语法:
select 列名 from
表1 inner join 表2
on 表1.列名=表2.列名
where.....
等价于:
select 列名
from 表1,表2
where 表1.列名=表2.列名 and ...(其他条件)
注:
- 表1和表2的顺序可以互换
- 找两张表的等值关系时,找表示相同含义的列作为等值关系。
- 点操作符表示“的”,格式:表名.列名
- 可以使用as,给表名起别名,注意定义别名之后,统一使用别名
示例:
//查询学生表中的学生姓名和分数表中的分数
select name,score
from student as s
inner join scores as c
on s.studentid=c.stuid
等价于:
select name,score
from student as s,scores as c
where s.studentid=c.stuid
三表联查:
语法:
select 列名 from 表1
inner join 表2 on 表1.列名=表2.列名
inner join 表3 on 表1或表2.列名=表3.列名 where
等价于:
select 列名 from 表1,表2,表3
where 表1.列名=表2.列名 and 表1/表2.列名=表3.列名
SQL标准的内连接为:
SELECT *
FROM emp e
INNER JOIN dept d
ON e.deptno=d.deptno;
内连接的特点:查询结果必须满足条件。
外连接
包括左外连接和右外连接,外连接的特点:查询出的结果存在不满足条件的可能。
左外联:
select 列名 from 主表 left join 次表 on 主表.列名=次表.列名
- 主表数据全部显示,次表数据匹配显示,能匹配到的显示数据,匹配不成功的显示null
- 主表和次表不能随意调换位置
使用场景:一般会作为子查询的语句使用,比如显示还没有员工的部门名称?
select depname,name from
(select e.*,d.depname from department d left join employee e on e.depid=d.depid
) aa where aa.name is null;
SELECT * FROM emp1 e
LEFT OUTER JOIN dept1 d
ON e.deptno=d.deptno;
左连接是先查询出左表(即以左表为主),然后查询右表,右表中满足条件的显示出来,不满足条件的显示NULL。
insert into emp values(1007,'何炅','主管',1006,'2019-6-1',1011,2004,50);
我们还是用上面的例子来说明。其中emp表中“张三”这条记录中,部门编号为50,而dept表中不存在部
门编号为50的记录,所以“张三”这条记录,不能满足e.deptno=d.deptno这条件。但在左连接中,因为
emp表是左表,所以左表中的记录都会查询出来,即“张三”这条记录也会查出,但相应的右表部分显示
NULL。
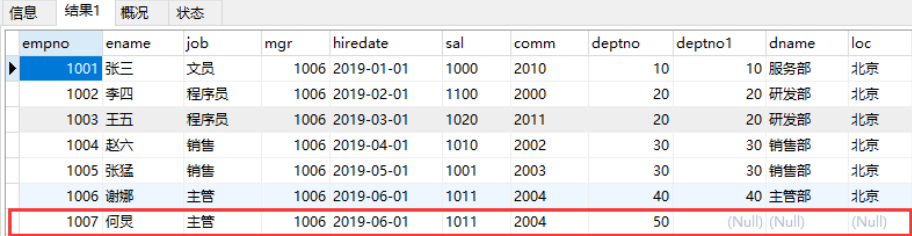
右外联:
select 列名 from 次表 right join 主表 on 主表.列名=次表.列名
右连接就是先把右表中所有记录都查询出来,然后左表满足条件的显示,不满足显示NULL。例如在dept表中的40部门并不存在员工,但在右连接中,如果dept表为右表,那么还是会查出40部门,但相应的员工信息为NULL。
insert into dept1 values(60,'颜值部','成都');
SELECT * FROM emp1 e
right outer join dept1 d
ON e.deptno=d.deptno;
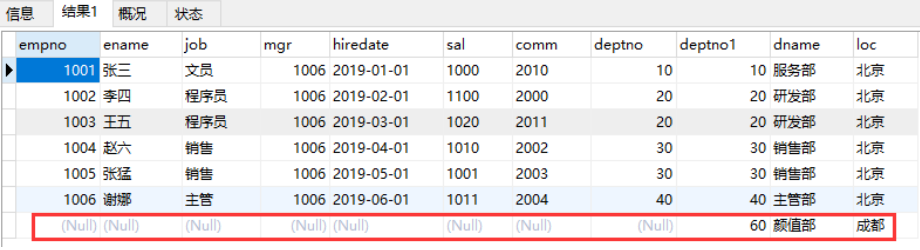
连接查询心得:
连接不限与两张表,连接查询也可以是三张、四张,甚至N张表的连接查询。通常连接查询不可能需要
整个笛卡尔积,而只是需要其中一部分,那么这时就需要使用条件来去除不需要的记录。这个条件大多
数情况下都是使用主外键关系去除。
两张表的连接查询一定有一个主外键关系,三张表的连接查询就一定有两个主外键关系,所以在大家不
是很熟悉连接查询时,首先要学会去除无用笛卡尔积,那么就是用主外键关系作为条件来处理。如果两
张表的查询,那么至少有一个主外键条件,三张表连接至少有两个主外键条件。
自然连接
自然连接(NATURAL INNER JOIN):自然连接是一种特殊的等值连接,他要求两个关系表中进行连
接的必须是相同的属性列(名字相同),无须添加连接条件,并且在结果中消除重复的属性列。.下面给
出几个例子。
语句:
select * from emp1 e natural join dept1 d;
🍃3 子查询
一个select语句中包含另一个完整的select语句。
子查询就是嵌套查询,即SELECT中包含SELECT,如果一条语句中存在两个,或两个以上SELECT,那么
就是子查询语句了。
-
子查询出现的位置:
a. where后,作为条为被查询的一条件的一部分;
b. from后,作表;
-
当子查询出现在where后作为条件时,还可以使用如下关键字:
a. any
b. all
-
子查询结果集的形式: a. 单行单列(用于条件)
b. 单行多列(用于条件)
c. 多行单列(用于条件)
d. 多行多列(用于表)
示例:
1. 工资高于JONES的员工。
分析:
查询条件:工资>JONES工资,其中JONES工资需要一条子查询。
第一步:查询JONES的工资
SELECT sal FROM emp WHERE ename='JONES';
第二步:查询高于甘宁工资的员工
SELECT * FROM emp WHERE sal > (第一步结果);
结果:
SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename='JONES');
2. 查询与谢娜同一个部门的员工。
l 子查询作为条件
l 子查询形式为单行单列
分析:
查询条件:部门=SCOTT的部门编号,其中SCOTT 的部门编号需要一条子查询。
第一步:查询SCOTT的部门编号
SELECT deptno FROM emp WHERE ename='SCOTT';
第二步:查询部门编号等于SCOTT的部门编号的员工
SELECT * FROM emp WHERE deptno = (SELECT deptno FROM emp WHERE ename='SCOTT');
3. 工资高于10号部门所有人的员工信息
分析:
SELECT * FROMemp WHERE sal>(SELECT MAX(sal) FROM emp WHERE deptno=30);
查询条件:工资高于30部门所有人工资,其中30部门所有人工资是子查询。高于所有需要使用all关键
字。
第一步:查询30部门所有人工资第二步:查询高于30部门所有人工资的员工信息
SELECT sal FROM emp WHERE deptno=30;
第二步:查询高于30部门所有人工资的员工信息
SELECT * FROM emp WHERE sal > ALL (第一步)
结果:
SELECT * FROM emp WHERE sal > ALL (SELECT sal FROM emp WHERE deptno=30)
l 子查询作为条件
l 子查询形式为多行单列(当子查询结果集形式为多行单列时可以使用ALL或ANY关键字)


















 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











