







 本文通过分析新零售智能销售设备的数据,进行数据清洗、预处理、字段规约,然后使用pyecharts库进行可视化,展示了设备数量与销售额、订单数量与设备数量、各市商品销售占比、售罄率、库存成本等关系,揭示了销售趋势和用户购买行为特点。
本文通过分析新零售智能销售设备的数据,进行数据清洗、预处理、字段规约,然后使用pyecharts库进行可视化,展示了设备数量与销售额、订单数量与设备数量、各市商品销售占比、售罄率、库存成本等关系,揭示了销售趋势和用户购买行为特点。
了解项目项目背景与目标
了解项目背景
1、由新零售智能销售设备的发展趋势可知,它的出现是由劳动密集型的产业构造向技术密集型转变的产物。大量生产、大量消费以及消费模式和销售环境的变化,要求出现新的流通渠道。而超市、百货购物中心等流通渠道的人工费用不断上升,再加上场地的局限性以及购物的便利性等这些因素的制约,新零售智能销售设备作为一种必须的机器便应运而生了。
2、某公司在广东省8个市部署了376台新零售智能销售设备,为了分析新零售智能销售设备数量与销售收入的情况,获取近6个月的新零售智能销售设备数据,结合销售背景从销售、库存、用户3个方向进行分析,并利用pyecharts可视化库展现销售现状。
熟悉数据情况
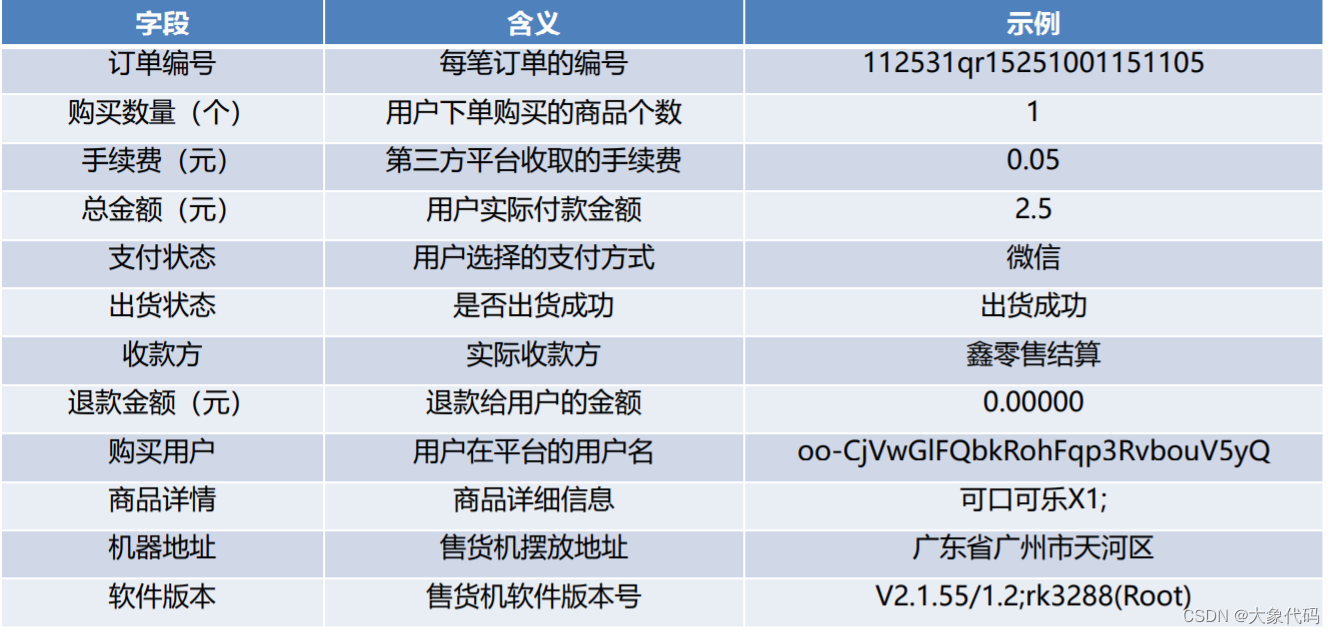
目前新零售智能销售设备后台管理系统已经积累了大量用户的购买记录,包含2018年4月至2018年9月的购买商品信息,以及所有的子类目信息。数据主要包括“商品表.xlsx”和“订单表.xlsx”,对应的数据字典分别下面两表所示。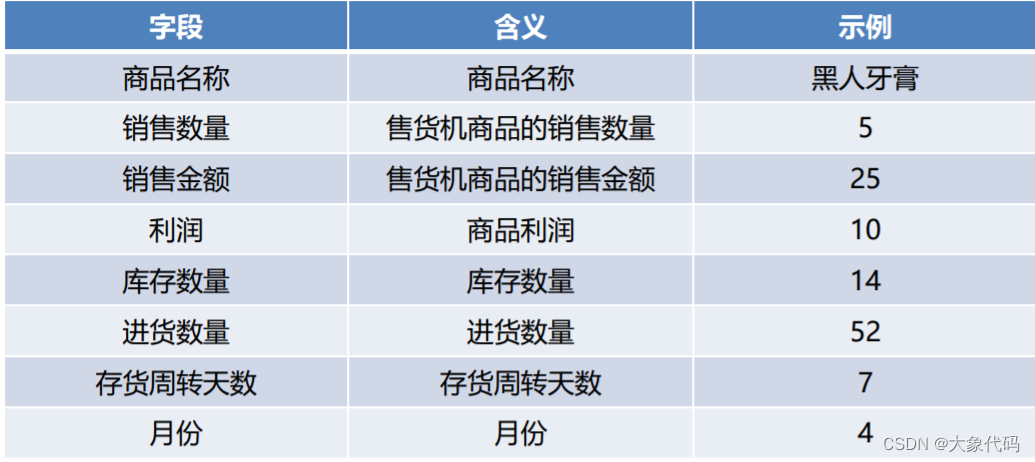
熟悉项目流程
新零售智能销售数据可视化项目的总体流程如图所示,主要步骤如下。
1、从新零售智能销售设备后台管理系统获取原始数据。

2、对原始数据进行数据预处理,包括数据清洗、降维、字段规约。
3、根据行业背景,从销售、库存和用户3个方向对处理后的新零售智能销售数据进行数据分析与可视化。
4、完成新零售智能销售项目分析报告。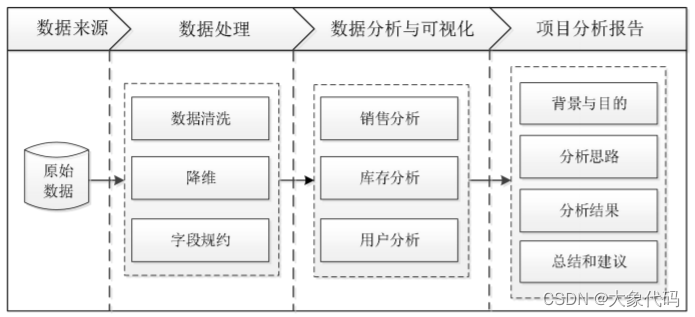
读取与处理新零售智能数据
读取与处理新零售智能数据
- 当对原始数据进行观察后,发现数据中存在一定的噪声数据,如“商品详情”字段中存“158X1;”“0401X1”"等多余的信息;
- 商品名称不一致,如“罐装芬达原味x1”“罐装芬达原味X1;”
- 部分销售记录数据项缺失等。
- 这些噪声数据将会对后续数据的统计和分析造成一定的影响,所以需要进行数据清洗和数据规约。
读取数据
- 新零售智能销售的数据文件主要有订单表2018-4.csv、订单表2018-5.csv、订单表2018-6.csv、订单表2018-7.csv、订单表2018-8.csv、订单表2018-9.csv和商品表.xlsx。在Python中导入新零售智能销售数据。
- 由结果可知,4月~9月的订单表中分别含有2081、46431、52682、79450、88670、90006条记录,商品表中有3756条记录。(数据以自己的为主)
# 代码7-1-读取数据
# encoding='gbk':告诉编译器需要使用GBK的解码方式对test.py 文件进行解码,转成相应的 Unicode 码,然后就运行代码了。
# data-读取并重命名
#print:输出
import pandas as pd
data4 = pd.read_csv('订单表2018-4.csv', encoding='gbk')
data5 = pd.read_csv('订单表2018-5.csv', encoding='gbk')
data6 = pd.read_csv('订单表2018-6.csv', encoding='gbk')
data7 = pd.read_csv('订单表2018-7.csv', encoding='gbk')
data8 = pd.read_csv('订单表2018-8.csv', encoding='gbk')
data9 = pd.read_csv('订单表2018-9.csv', encoding='gbk')
goods_info = pd.read_excel('商品表.xlsx')
print(data4.shape, data5.shape, data6.shape, data7.shape,
data8.shape, data9.shape, goods_info.shape)(2077, 14) (46068, 14) (51925, 14) (77644, 14) (86459, 14) (86723, 14) (3626, 8)
清洗数据
合并数据:由于订单表的数据是按月份分开存放的,为了方便后续对数据进行处理和可视化,所以需要对订单数据进行合并处理。
#合并数据
data = pd.concat([data4, data5, data6, data7, data8, data9], ignore_index=True)
print('订单表合并后的数据为', data.shape)订单表合并后的数据为 (350896, 14)
缺失值检测:当合并订单表的数据后,为了了解订单表的数据的基本情况,需要进行缺失值检测。
(两个表:订单表和商品表)
订单表
# 缺失值检测
print('订单表各列的缺失值数目为:\n', data.isnull().sum())
print('未做删除缺失值前订单表行列数目为:', data.shape)订单表各列的缺失值数目为:
设备编号 0
下单时间 0
订单编号 0
购买数量(个) 0
手续费(元) 0
总金额(元) 0
支付状态 0
出货状态 3
收款方 276
退款金额(元) 0
购买用户 0
商品详情 0
省市区 0
软件版本 0dtype: int64
未做删除缺失值前订单表行列数目为: (350896, 14)
商品表
# 清洗商品表
print('商品表各列的缺失值数目为:\n', goods_info.isnull().sum())
print('未做删除缺失值前商品表行列数目为:', goods_info.shape)商品表各列的缺失值数目为:
商品名称 392
销售数量 0
销售金额 0
利润 0
库存数量 0
进货数量 0
存货周转天数 0
月份 0
dtype: int64
未做删除缺失值前商品表行列数目为: (3626, 8)
缺失值处理:订单表中含有缺失值的记录总共有278条,相对较少,可直接使用删除法对其中的缺失值进行处理。
(两个表:订单表和商品表)
订单表
# 缺失值处理--删除缺失值
data = data.dropna(how='any') # 删除
print('删除完缺失值后订单表行列数目为:', data.shape)删除完缺失值后订单表行列数目为: (350617, 14)
商品表
# 删除缺失值
goods_info = goods_info.dropna(how='any')
print('删除完缺失值后商品表行列数目为:', goods_info.shape)删除完缺失值后商品表行列数目为: (3234, 8)
增加字段:为了满足后续的数据可视化需求,需要在订单表中增加“市”字段。
# 增加字段--从省市区中提取市的信息,并创建新列
data['市'] = data['省市区'].str[3: 6]
print('经过处理后前5行为:\n', data.head())
#可以在 data.head()填写任意数字、默认5经过处理后前5行为:
设备编号 下单时间 ... 软件版本 市
0 112531 2018/4/30 22:55 ... V2.1.55/1.2;rk3288 中山市
1 112673 2018/4/30 22:50 ... V3.0.37;rk3288;(900x1440) 佛山市
2 112636 2018/4/30 22:35 ... V2.1.55/1.2;rk3288 广州市
3 112636 2018/4/30 22:33 ... V2.1.55/1.2;rk3288 广州市
4 112636 2018/4/30 21:33 ... V2.1.55/1.2;rk3288 广州市[5 rows x 15 columns]
统一商品名称:通过浏览订单表数据发现,在“商品详情”字段中存在有异名同义的情况,即两个名称不同的字段所代表的实际意义是一致的,如“维他柠檬茶X1;”“维他柠檬茶x1”等。因为这种情况会对后面的可视化分析结果造成一定的影响,所以需要对订单表中的“商品详情”字段进行处理,增加“商品名称”字段
# 统一商品名称--定义一个需剔除的字符的list
error_str = [' ', '(', ')', '(', ')', '0', '1', '2', '3', '4', '5', '6',
'7', '8', '9', 'g', 'l', 'm', 'M', 'L', '听', '特', '饮', '罐',
'瓶', '只', '装', '欧', '式', '&', '%', 'X', 'x', ';']
# 使用循环剔除指定字符
for i in error_str:
data['商品详情'] = data['商品详情'].str.replace(i, '')
# 新建一列 商品名称用于新数据存放
data['商品名称'] = data['商品详情']
data['商品名称'][0: 5]
print(data['商品名称'])
print(data['商品名称'][0: 5])
D:\pycharm\复杂.py:38: FutureWarning: The default value of regex will change from True to False in a future version. In addition, single character regular expressions will *not* be treated as literal strings when regex=True.
data['商品详情'] = data['商品详情'].str.replace(i, '')
D:\pycharm\复杂.py:41: FutureWarning: The behavior of `series[i:j]` with an integer-dtype index is deprecated. In a future version, this will be treated as *label-based* indexing, consistent with e.g. `series[i]` lookups. To retain the old behavior, use `series.iloc[i:j]`. To get the future behavior, use `series.loc[i:j]`.
data['商品名称'][0: 5]
D:\pycharm\复杂.py:43: FutureWarning: The behavior of `series[i:j]` with an integer-dtype index is deprecated. In a future version, this will be treated as *label-based* indexing, consistent with e.g. `series[i]` lookups. To retain the old behavior, use `series.iloc[i:j]`. To get the future behavior, use `series.loc[i:j]`.
print(data['商品名称'][0: 5])
0 可口可乐
1 旺仔牛奶
2 雪碧
3 阿萨姆奶茶
4 王老吉
...
350891 王老吉
350892 王老吉
350893 挑战者
350894 伊利麦香味早餐奶
350895 伊利麦香味早餐奶
Name: 商品名称, Length: 350617, dtype: object
0 可口可乐
1 旺仔牛奶
2 雪碧
3 阿萨姆奶茶
4 王老吉
Name: 商品名称, dtype: object
异常值处理:通过浏览订单表数据发现,在“总金额(元)”字段中,存在极少订单的金额很小,如0、0.01等。
在现实生活中,这种记录存在情况的极少,并且这部分数据不具有分析意义。因此,在本项目中,对订单的金额小于0.5的记录进行删除处理
# 删除金额较少的订单前的数据量
print(data.shape)
# 删除金额较少的订单后的数据量
data = data[data['总金额(元)'] >= 0.5]
print(data.shape)(350617, 16)
(350450, 16)
# 将商品名称表中的部分商品进行名字统一
goods_info['商品名称'] = goods_info['商品名称'].str.replace('可口可乐', '可乐')
goods_info['商品名称'] = goods_info['商品名称'].str.replace(' ', '')
goods_info['商品名称'] = goods_info['商品名称'].str.replace('可比克薯片烧烤味',
'可比克烧烤味')
goods_info['商品名称'] = goods_info['商品名称'].str.replace('可比克薯片牛肉味',
'可比克牛肉味')
goods_info['商品名称'] = goods_info['商品名称'].str.replace('可比克薯片番茄味',
'可比克番茄味')
goods_info['商品名称'] = goods_info['商品名称'].str.replace('阿沙姆奶茶',
'阿萨姆奶茶')
goods_info['商品名称'] = goods_info['商品名称'].str.replace('罐装百威',
'罐装百威啤酒')
print(goods_info['商品名称'])
goods_info.to_csv('goods_info.csv', index=False, encoding = 'gbk')0 黑派黑水
1 黑派黑水
2 黑派黑水
3 黑派黑水
4 黑派黑水
...
3229 18g旺仔小馒头
3230 18g旺仔小馒头
3231 18g旺仔小馒头
3232 18g旺仔小馒头
3233 18g旺仔小馒头
Name: 商品名称, Length: 3234, dtype: object
规约数据
1.属性选择
因为订单表中的“手续费(元)”“收款方”“软件版本”“省市区”“商品详情”“退款金额(元)”等字段对本项目的分析没有意义,所以需要对其进行删除处理,实现数据的降维
# 属性选择--降维订单数据
data = data.drop(['手续费(元)', '收款方', '软件版本', '省市区',
'商品详情', '退款金额(元)'], axis=1)
print('降维后,数据列为:\n', data.columns.values)降维后,数据列为:
['设备编号' '下单时间' '订单编号' '购买数量(个)' '总金额(元)' '支付状态' '出货状态' '购买用户' '市' '商品名称']
2.字段规约
时间段规约:在订单表“下单时间”字段中含有的信息量多,并且存在概念分层,需要对字段进行数据规约,提取需要的信息。
提取相应的“小时”字段和“月份”字段,进一步泛化“小时”字段为“下单时间段”字段。
当小时<5时,为“凌晨”
当5<小时<8时,为“早晨”;
当8<小时≤11时,为“上午”;
当11<小时≤13时,为“中午”;
当13<小时≤16时,为“下午”;
当16<小时≤19时,为“傍晚”;
当19<小时≤24,为“晚上”。
# 归约订单数据字段
# 将时间格式的字符串转换为标准的时间
data['下单时间'] = pd.to_datetime(data['下单时间'])
data['小时'] = data['下单时间'].dt.hour # 提取时间中的小时,将其赋给新列 小时
data['月份'] = data['下单时间'].dt.month
data['下单时间段'] = 'time' # 新增一列下单时间段,并将其初始化为time
exp1 = data['小时'] <= 5 # 判断小时是否小于等于5
# 条件为真则时间段为凌晨
data.loc[exp1, '下单时间段'] = '凌晨'
# 判断小时是否大于5且小于等于8
exp2 = (5 < data['小时']) & (data['小时'] <= 8)
# 条件为真则时间段为早晨
data.loc[exp2, '下单时间段'] = '早晨'
# 判断小时是否大于8且小于等于11
exp3 = (8 < data['小时']) & (data['小时'] <= 11)
# 条件为真则时间段为上午
data.loc[exp3, '下单时间段'] = '上午'
# 判断小时是否小大于11且小于等于13
exp4 = (11 < data['小时']) & (data['小时'] <= 13)
# 条件为真则时间段为中午
data.loc[exp4, '下单时间段'] = '中午'
# 判断小时是否大于13且小于等于16
exp5 = (13 < data['小时']) & (data['小时'] <= 16)
# 条件为真则时间段为下午
data.loc[exp5, '下单时间段'] = '下午'
# 判断小时是否大于16且小于等于19
exp6 = (16 < data['小时']) & (data['小时'] <= 19)
# 条件为真则时间段为傍晚
data.loc[exp6, '下单时间段'] = '傍晚'
# 判断小时是否大于19且小于等于24
exp7 = (19 < data['小时']) & (data['小时'] <= 24)
# 条件为真则时间段为晚上
data.loc[exp7, '下单时间段'] = '晚上'
print('处理完成后的订单表前5行为:\n', data.head())
data.to_csv('order.csv', index=False, encoding = 'gbk')处理完成后的订单表前5行为:
设备编号 下单时间 订单编号 ... 小时 月份 下单时间段
0 112531 2018-04-30 22:55:00 112531qr15251001151105 ... 22 4 晚上
1 112673 2018-04-30 22:50:00 112673qr15250998551741 ... 22 4 晚上
2 112636 2018-04-30 22:35:00 112636qr15250989343846 ... 22 4 晚上
3 112636 2018-04-30 22:33:00 112636qr15250988245087 ... 22 4 晚上
4 112636 2018-04-30 21:33:00 112636qr15250952296930 ... 21 4 晚上[5 rows x 13 columns]
最后输出:
goods_info--商品表;order.csv--订单表
可视化实现
绘制销售分析图
①在销售数据中含有的数据量较多,作为企业管理人员以及决策制定者,无法直观了解目前新零售智能销售设备的销售状况。因此需要利用处理好的数据进行可视化分析,直观地展示销售走势以及各区销售情况,为决策者提供参考。
②商品销售情况在一定程度上可反映商品的销售数量、销售额等,通过对商品销售额、订单数量和各市销售额等销售情况进行分析,可以促进生产的发展,做好销售工作。从销售额与新零售智能销售设备的数量、订单数量与新零售智能销售设备数量、每个市的总销售额、畅销与滞销商品等角度,对新零售智能销售设备的销售进行分析,并进行可视化展示,从而使企业管理人员了解新零售智能销售设备的基本销售情况。
1.销售额与新零售智能销售设备数量的关系
①探索近6个月销售额和新零售智能销售设备数量之间的关系,并按时间走势进行可视化分析。
②由右图可知,在4月到7月这段时间,随着新零售智能设备数量增加,销售额也在增加,但8月相对7月而言,设备数量减少了,但销售额还保持了一定的增长。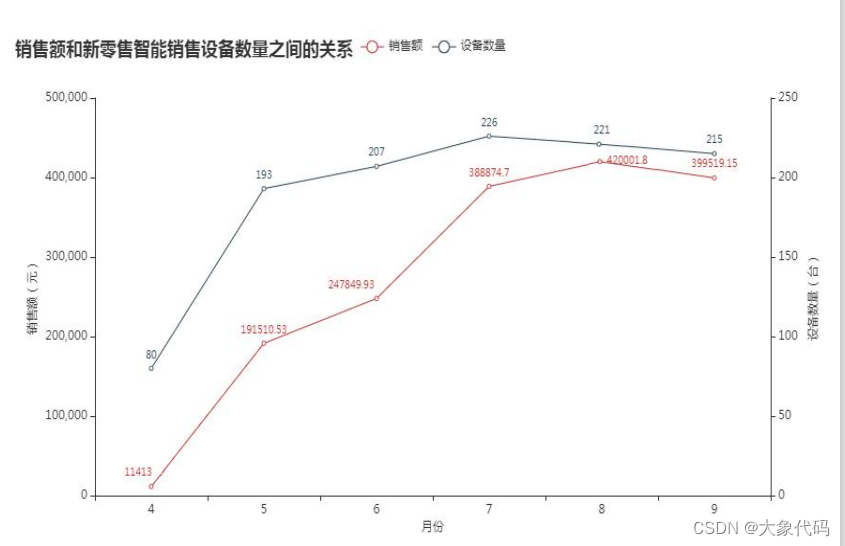
# #引入第三方库
import numpy as np
import pandas as pd
from pyecharts.charts import Line
from pyecharts import options as opts
data = pd.read_csv('order.csv',encoding='gbk')
#销售额和新零售智能销售设备数量之间的关系
def f(x):
return len(list(set((x.values))))
groupby_month = data.groupby(by='月份',as_index=False).agg({'设备编号': f,'总金额(元)':np.sum})
groupby_month.columns = ['月份','设备数量','销售额']
data_moth_x = [str (i) for i in groupby_month['月份'].values.tolist()]
line_1 = (
Line()
.add_xaxis(data_moth_x)
.add_yaxis('销售额',np.round(groupby_month['销售额'].values.tolist(),2))
.add_yaxis('设备数量',groupby_month['设备数量'].values.tolist(),yaxis_index=1)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name='月份',name_location='center',name_gap=25),
title_opts=opts.TitleOpts(title='销售额和新零售智能销售设备数量之间的关系'),
yaxis_opts=opts.AxisOpts(
name='销售额(元)',
name_location='center',
name_gap=60,
axislabel_opts=opts.LabelOpts(formatter='{value}')
)
)
.extend_axis(
yaxis=opts.AxisOpts(
name='设备数量(台)',
name_location='center',
name_gap=40,
axislabel_opts=opts.LabelOpts(formatter='{value}'),interval=50
)
)
)
line_1.render('1.html')自己:
import numpy as np
import pandas as pd
from pyecharts.charts import Line
from pyecharts import options as opts
#一、读取数据
data = pd.read_csv('order.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='月份',as_index=False).agg({'设备编号': f,'总金额(元)':np.sum})
#columns:表示列索引
groupby_month.columns = ['月份','设备数量','销售额']
data_x_yue = groupby_month['月份'].values.tolist()
data_y_xiao = groupby_month['销售额'].values.tolist()
data_y_she = groupby_month['设备数量'].values.tolist()
data_moth_x = [str (i) for i in data_x_yue]
#实例化对象
line_1 = (
Line()
.add_xaxis(data_moth_x)
#round(x,n)方法将返回x的值,该值四舍五入到小数点后的n位数字。
.add_yaxis('销售额',np.round(data_y_xiao,2))
# # 使用的 y 轴的 index,在单个图表实例中存在多个 y 轴的时候有用。
.add_yaxis('设备数量',data_y_she,yaxis_index=1)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name='月份',name_location='center',name_gap=25),
title_opts=opts.TitleOpts(title='销售额和新零售智能销售设备数量之间的关系'),
yaxis_opts=opts.AxisOpts(
name='销售额(元)',
name_location='center',
name_gap=60,
axislabel_opts=opts.LabelOpts(formatter='{value}')
)
)
#添加
.extend_axis(
yaxis=opts.AxisOpts(
name='设备数量(台)',
name_location='center',
name_gap=40,
#可以用数值表示间隔的数据
axislabel_opts=opts.LabelOpts(formatter='{value}'),interval=50
)
)
)
line_1.render('1.html')
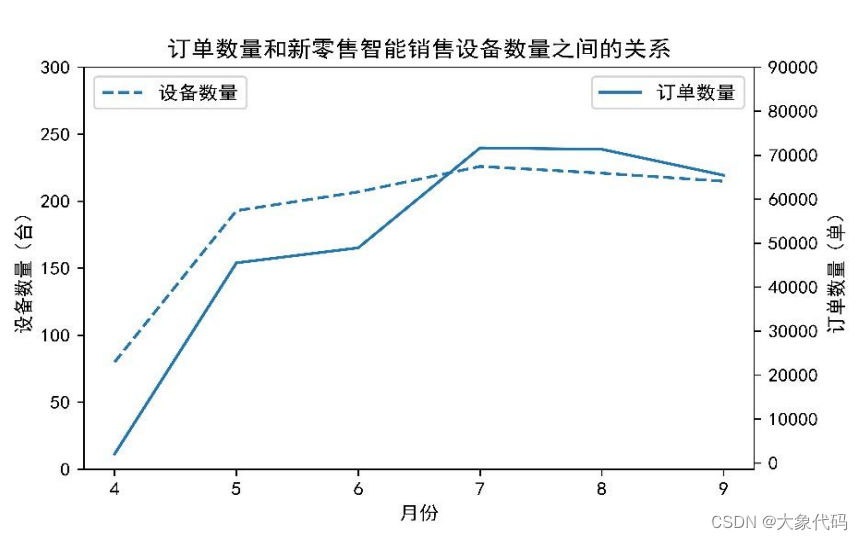
2.订单数量与新零售智能销售设备数量的关系
①探索近6个月订单数量和新零售智能销售设备数量之间的关系,并按时间走势进行可视化分析。
②由右图可知,订单数量随着新零售智能设备数量增加而增加,随着新零售智能设备数量减少而减少,存在一定的相关性。
import numpy as np
import pandas as pd
from pyecharts.charts import Line
from pyecharts import options as opts
#一、读取数据
data = pd.read_csv('order.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='月份',as_index=False).agg({'设备编号': f,'购买数量(个)':np.sum})
#columns:表示列索引
groupby_month.columns = ['月份','设备数量','订单数量']
data_x_yue = groupby_month['月份'].values.tolist()
data_y_ding = groupby_month['订单数量'].values.tolist()
data_y_she = groupby_month['设备数量'].values.tolist()
data_moth_x = [str (i) for i in data_x_yue]
#实例化对象
line_1 = (
Line()
.add_xaxis(data_moth_x)
#round(x,n)方法将返回x的值,该值四舍五入到小数点后的n位数字。
.add_yaxis('设备数量',data_y_she,
linestyle_opts=opts.LineStyleOpts(type_="dashed",color='blue',width=2),#虚线
label_opts=opts.LabelOpts(is_show=False),
)
# # 使用的 y 轴的 index,在单个图表实例中存在多个 y 轴的时候有用。
.add_yaxis('订单数量',data_y_ding,yaxis_index=1,
label_opts=opts.LabelOpts(is_show=False),
linestyle_opts=opts.LineStyleOpts(width=2,color='blue'),
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(name='月份',name_location='center',name_gap=25),
title_opts=opts.TitleOpts(title='订单数量和新零售智能销售设备数量之间的关系',
pos_left='center'
),
yaxis_opts=opts.AxisOpts(#AxisOpts:坐标轴配置项
name='设备数量(台)',
name_location='center',
name_gap=40,
max_=300,
# interval:坐标轴间隔
axislabel_opts=opts.LabelOpts(formatter='{value}'),interval=50,
),
legend_opts=opts.LegendOpts(
pos_top =56,item_gap=500,legend_icon='line'
),
)
.set_series_opts(
)
#添加
.extend_axis(
yaxis=opts.AxisOpts(
name='订单数量(单)',
name_location='center',
name_gap=60,
#max_=90000,
axislabel_opts=opts.LabelOpts(formatter='{value}'),
)
)
)
line_1.render('1.html')
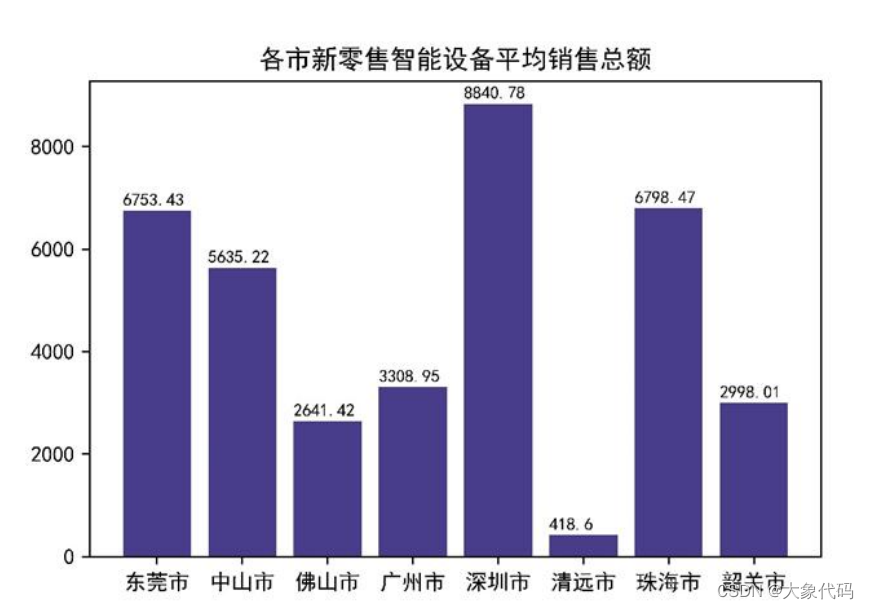
①由于各市的设备数量并不一致,所以探索各市新零售智能设备平均销售总额进行对比。
②由右图可知,深圳市的平均销售总额领先于其他城市,达到了8840.78元,清远市销售额是最少的,只有418.6元。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
data = pd.read_csv('order.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='市',as_index=False).agg({'设备编号':f,'总金额(元)':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['市','设备数量','销售总额']
data_x_shi = groupby_month['市'].values.tolist()
data_y_she = groupby_month['设备数量'].values.tolist()
data_y_xiao = groupby_month['销售总额'].values.tolist()
data_moth_x = [str (i) for i in data_x_shi]
#平均值
#for i in range ()作用:
#range()是一个函数, for i in range () 就是给i赋值
# append() 方法用于在列表末尾追加新的对象
# 1.算术运算符‘/’表示的是除法运算,和数学中的除法规则是一样的,如:5/2=2.5;
# 2.算术运算符‘//’表示的是除法取整运算,即返回结果为除法运算商的整数部分,如:5//2=2;
# 3.算术运算符‘%’表示的是除法取余运算,即返回结果为除法运算商的余数部分,如: 5%2=1;
a = []
for i in range(len(data_y_she)):
a.append(groupby_month['销售总额'][i]//groupby_month['设备数量'][i])
groupby_month['平均销售总额']=a
#实例化对象
line_1 = (
Bar()
.add_xaxis(data_moth_x)
.add_yaxis('平均销售总额',groupby_month['平均销售总额'].values.tolist(),)
.set_global_opts(
title_opts=opts.TitleOpts(title='各市新零售智能设备平均销售总额',pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)#图例
)
)
line_1.render('1.html')
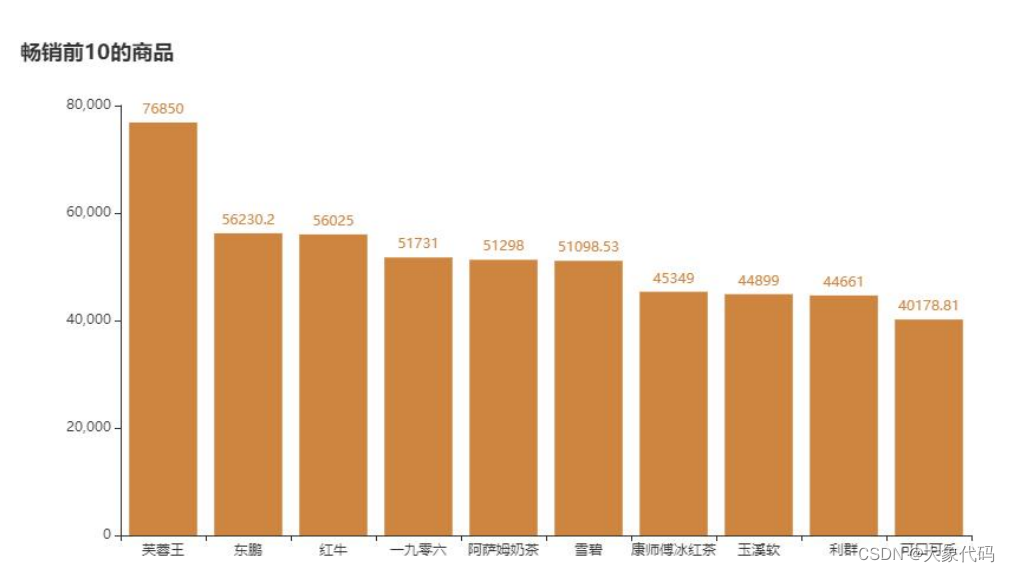
3.畅销和滞销商品
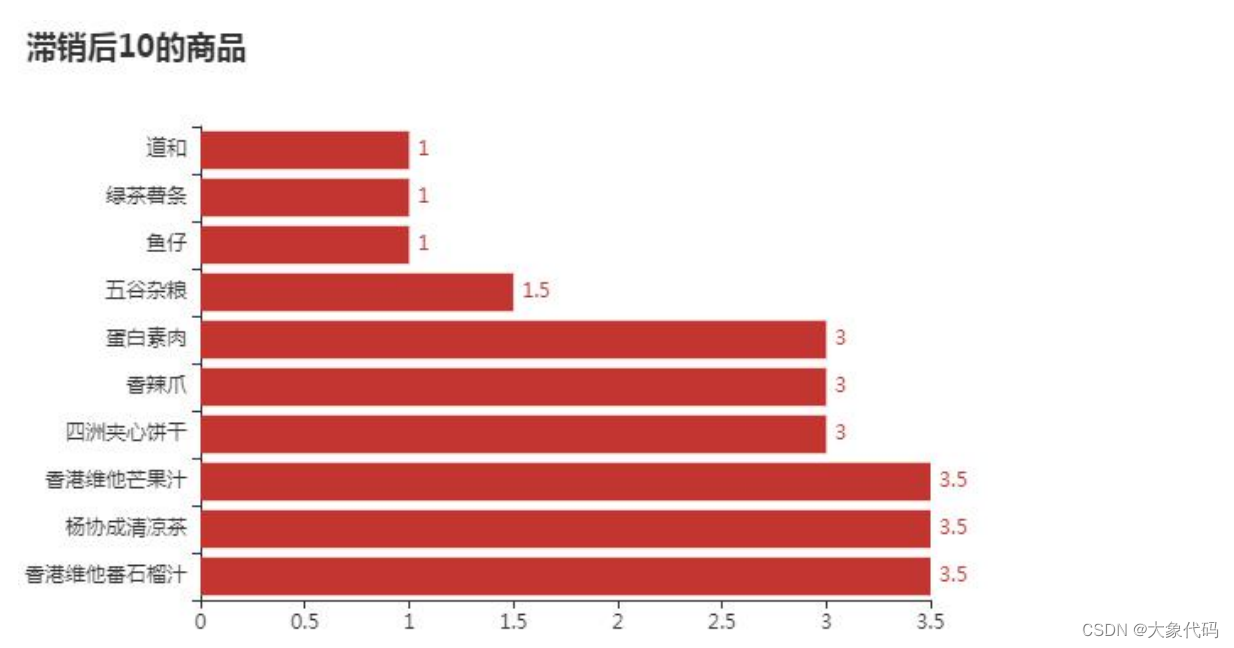
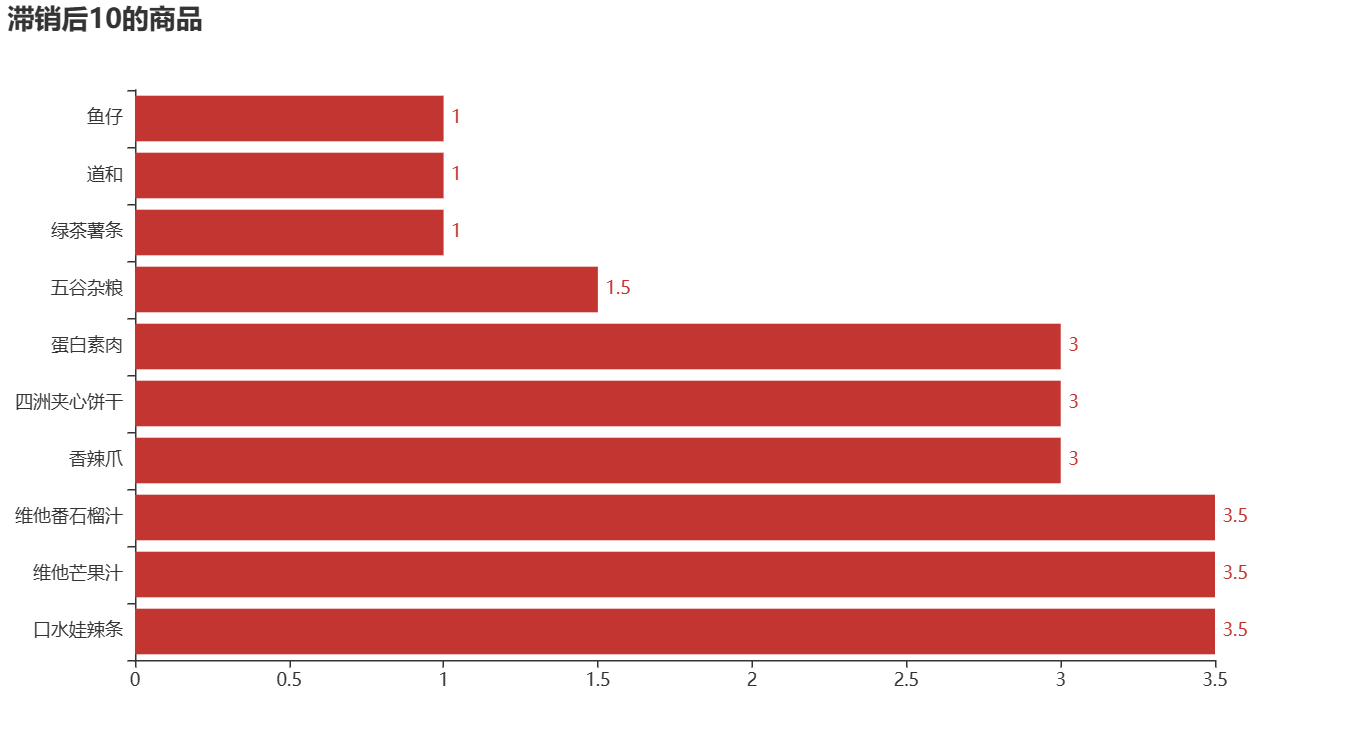
①查找近6个月销售额前10和后10的商品,从而找出畅销商品和滞销商品,并对其销售金额进行可视化分析。
②由右图可知,销售金额排在第一的是芙蓉王,销售额达到了76850元,其次是东鹏和红牛等商品。
由右图可知,销售金额排在最后的商品是道和、绿茶薯条和鱼仔,其销售金额只有1元。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
data = pd.read_csv('order.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='商品名称',as_index=False).agg({'总金额(元)':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['商品名称','销售总额']
data_x_shang = groupby_month['商品名称'].values.tolist()
data_y_xiao = groupby_month['销售总额'].values.tolist()
data_moth_x = [str (i) for i in data_x_shang]
# 最大值
product_amount = data.groupby('商品名称').agg({'总金额(元)':'sum'}).sort_values(by='总金额(元)',ascending=False).reset_index()
a = product_amount.head(10)
a_x = a['商品名称'].tolist()
a_y = a['总金额(元)'].tolist()
#print(a)
#实例化对象
line_1 = (
Bar()
.add_xaxis(a_x)
.add_yaxis('',a_y)
.set_global_opts(
title_opts=opts.TitleOpts(title='畅销前10的商品',pos_left='left'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30)
),
)
)
line_1.render('1.html')
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
data = pd.read_csv('order.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='商品名称',as_index=False).agg({'总金额(元)':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['商品名称','销售总额']
data_x_shang = groupby_month['商品名称'].values.tolist()
data_y_xiao = groupby_month['销售总额'].values.tolist()
data_moth_x = [str (i) for i in data_x_shang]
# 最小值
product_amount = data.groupby('商品名称').agg({'总金额(元)':'sum'}).sort_values(by='总金额(元)',ascending=False).reset_index()
a = product_amount.tail(10)
a_x = a['商品名称'].tolist()
a_y = a['总金额(元)'].tolist()
#print(a)
#实例化对象
line_1 = (
Bar()
.add_xaxis(a_x)
.reversal_axis()
.add_yaxis('',a_y)
.set_global_opts(
title_opts=opts.TitleOpts(title='滞销后10的商品',pos_left='left'),
#xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30)),
)
.set_series_opts(label_opts=opts.LabelOpts(position="right"))#标签数值的位
)
line_1.render('1.html')
4.各市商品销售占比情况-没有做出来
探索近6个月各城市销售金额前10的商品占比情况,并对其进行可视化分析。
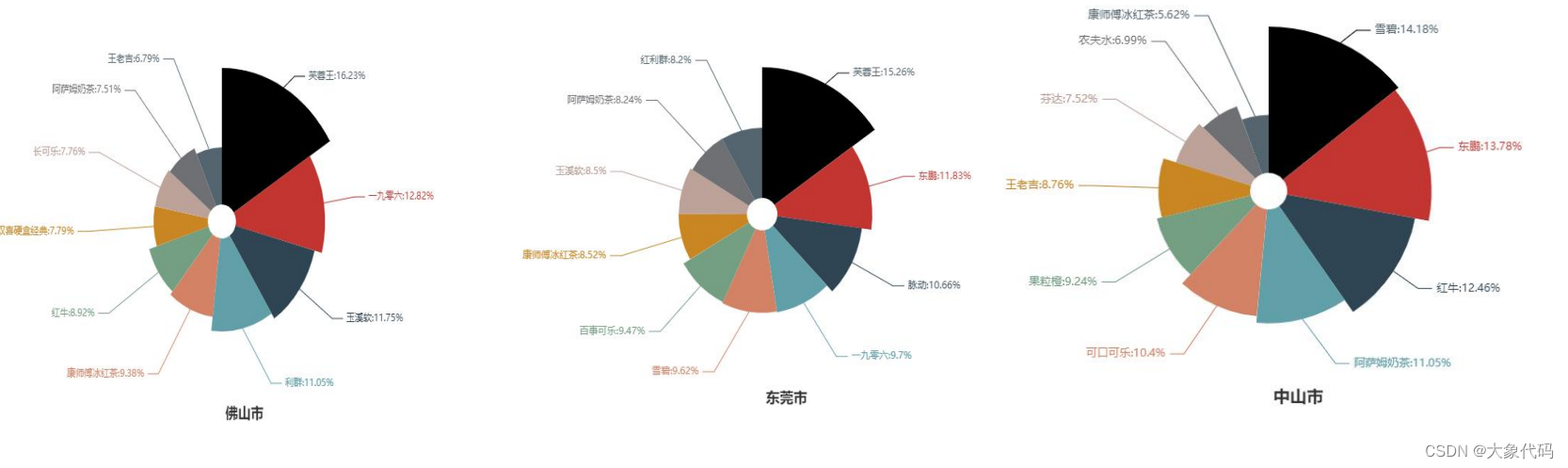
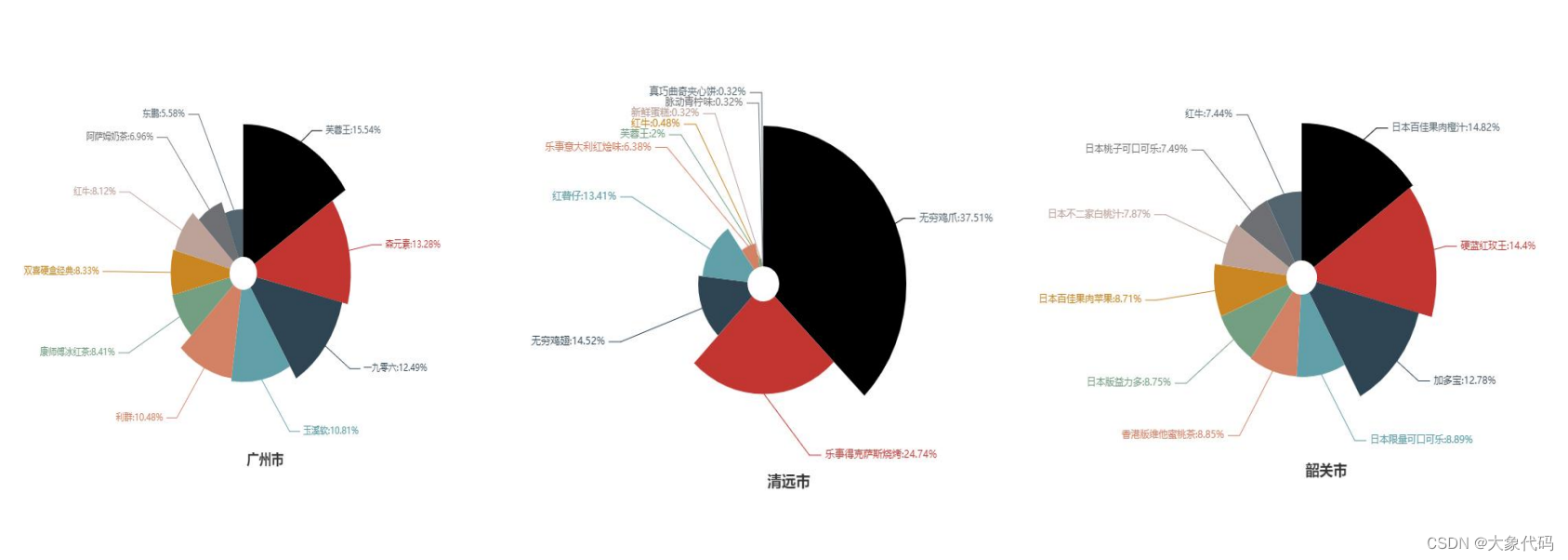
由各市图形可知,在东莞市、广州市、深圳市和佛山市销售额最高的都是芙蓉王,而中山市销售额最高的是雪碧,清远市销售额最高的是无穷鸡爪,韶关市销售额最高的是日本百佳果肉橙汁,珠海市销售额最高的是孔髻山矿泉水。
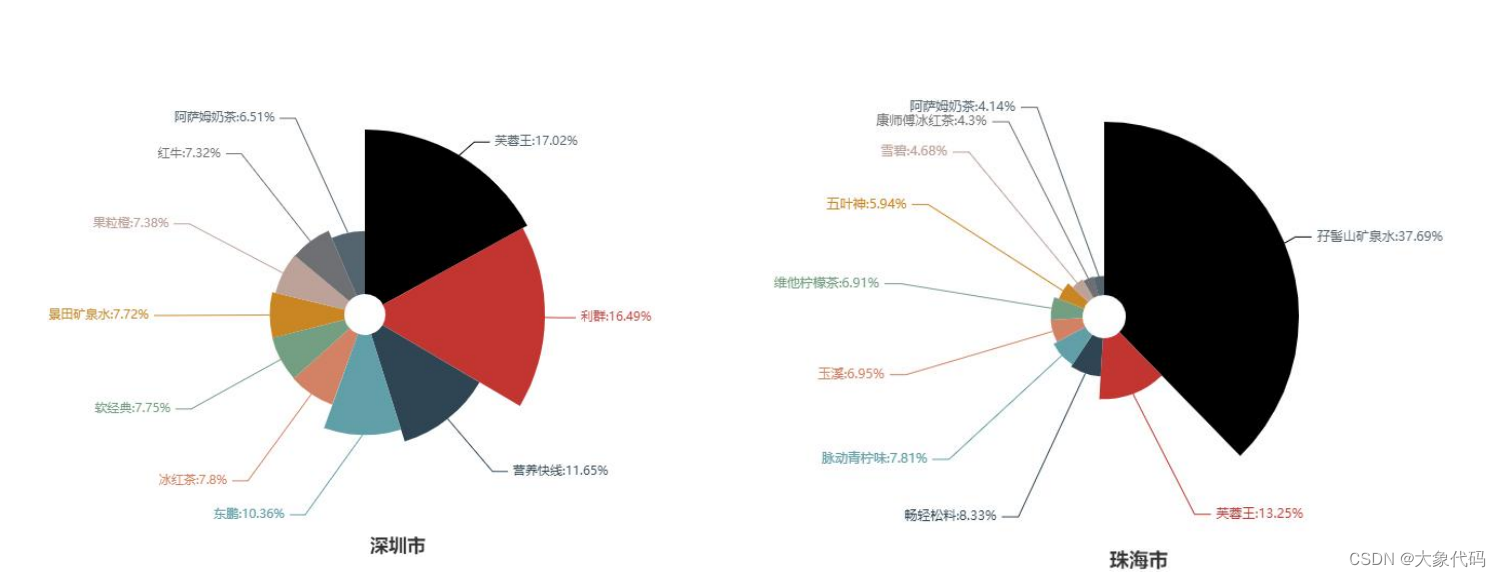
import numpy as np
import pandas as pd
from pyecharts.charts import Pie,Timeline
from pyecharts import options as opts
data=pd.read_csv('order.csv',encoding='gbk')
# 合并
groupby_data=data.groupby(by=['商品名称','市'],as_index=False).agg({'总金额(元)':np.sum})
# #取出市x轴数据
data_x1=[str(i) for i in list(groupby_data['市'].values.tolist())]
#取出市的数据并去重:set:清洗
province=[str(i) for i in list(set(groupby_data['市'].values.tolist()))]
province.sort(key=data_x1.index)#排序
t=Timeline()
for i in province:
data_x2=groupby_data[groupby_data['市']==i].sort_values('总金额(元)',ascending=False)
data_x=[str(i) for i in data_x2['商品名称'][:10].values.tolist()]
data_y=data_x2['总金额(元)'][:10].values.tolist()
p=(
Pie()
.add("",[list(z) for z in zip(data_x,data_y)],rosetype="radius",radius=['7%','55%'])
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="items",formatter="{b}:{d}%",
is_always_show_content=True
),
label_opts=opts.LabelOpts(
formatter="{b}:{d}%"
)
)
)
t.add(p,'{}'.format(i))
t.render('1.html')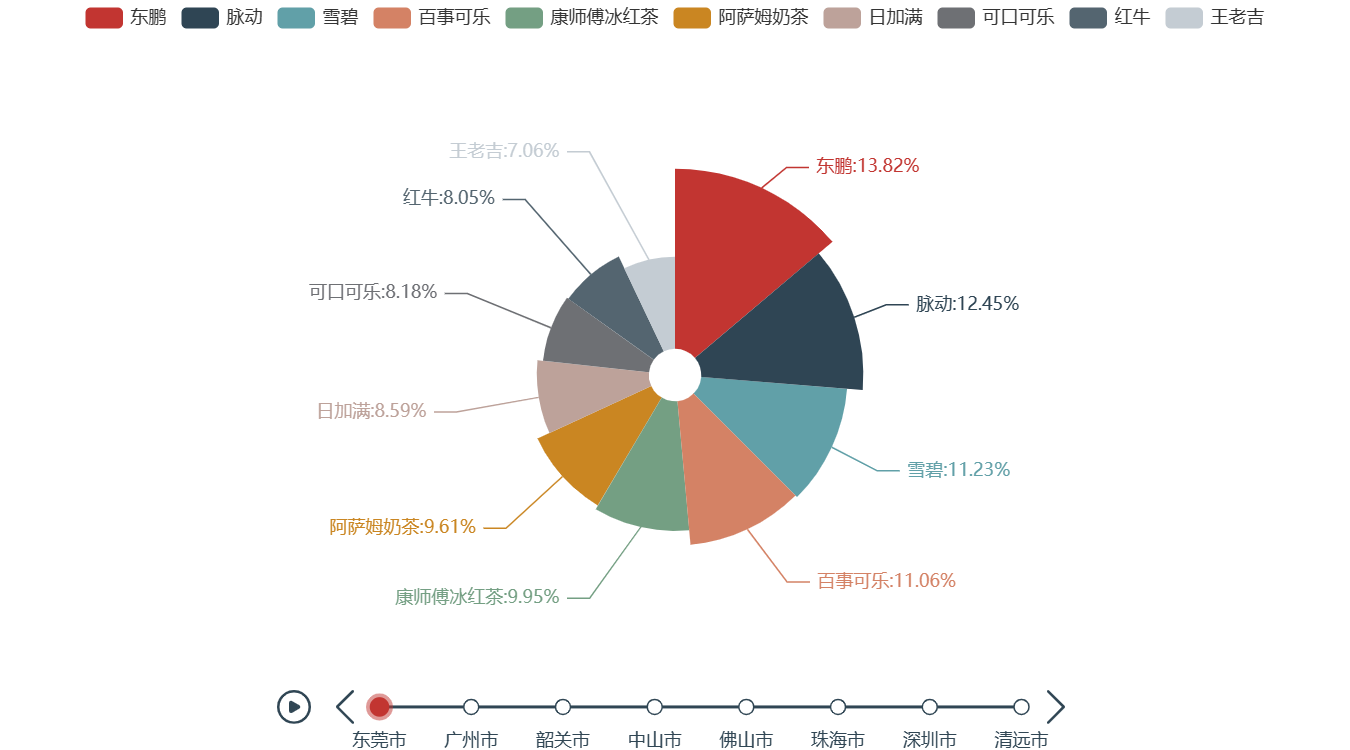
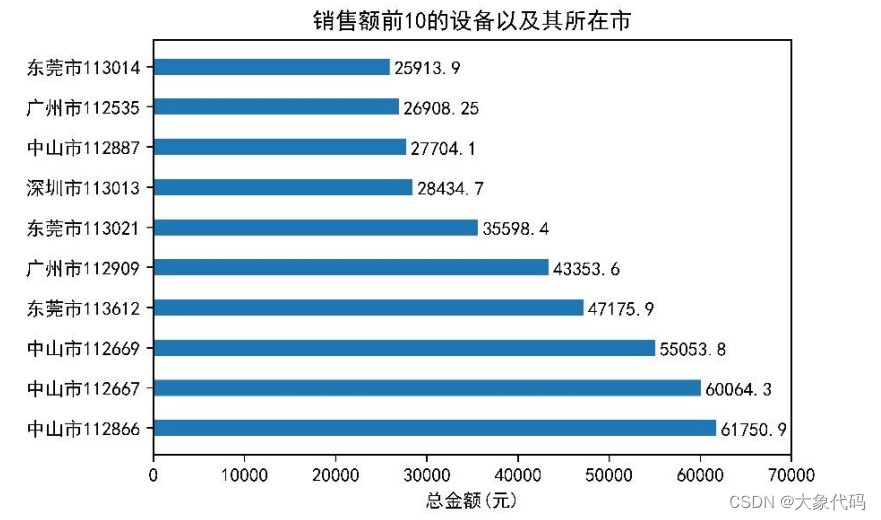
5.新零售智能销售设备的销售情况
①探索6个月销售额前10以及销售额后10的设备以及所在的城市,并进行可视化分析。
②由右图可知,销售额靠前的城市主要集中在中山市、东莞市和广州市,销售前3的设备都集中在中山市。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('order.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='设备编号',as_index=False).agg({'市':f,'总金额(元)':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['设备编号','市','销售总额']
data_x_xiao = groupby_month['设备编号'].values.tolist()
data_x_shi = groupby_month['市'].values.tolist()
data_y_shang = groupby_month['销售总额'].values.tolist()
# 最大值
#ascending 参数是一个布尔类型的参数,当它设置为 True 时,返回的结果将从小到大排序;当它设置为 False 时,返回的结果将从大到小排序。
#reset_index:会将原来的索引index作为新的一列
#sort_values()函数原理类似于SQL中的order by,可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
#groupby函数基本格式:data.groupby([‘分组字段’])
product_amount = data.groupby(['市','设备编号']).agg({'总金额(元)':'sum'}).sort_values(by='总金额(元)',ascending=False).reset_index()
#product_amount_1 = data.groupby('市').agg({'总金额(元)':'sum'}).sort_values(by='总金额(元)',ascending=False).reset_index()
a = product_amount.head(10)
#b = product_amount_1.head(10)
# print(a)
#生成市+设备编号的列名
a["市设备编号"] = a["市"]+ a["设备编号"].map(str)
# d = a["市设备编号"].columns = ["市设备编号"]
# print(a["市设备编号"])
# #print(a["市设备编号"])
a_x = a['市设备编号'].tolist()
a_y = a['总金额(元)'].tolist()
# print(a)
# 实例化对象
line_1 = (
Bar()
.add_xaxis(a_x)
.reversal_axis()
.add_yaxis('总金额(元)',a_y)
.set_global_opts(
title_opts=opts.TitleOpts(title='销售额前10的设备以及其所在市',pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)#图例
#xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30)),
)
.set_series_opts(label_opts=opts.LabelOpts(position="right"))#标签数值的位
)
line_1.render('1.html')

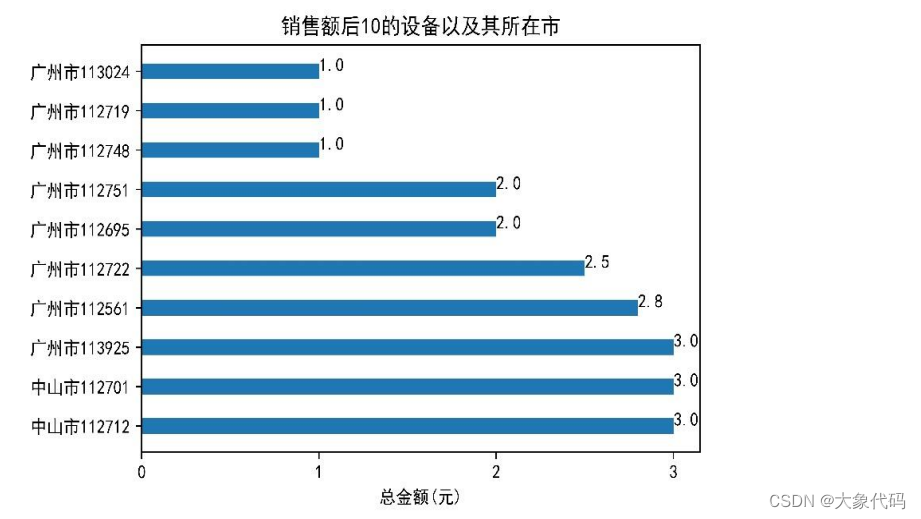
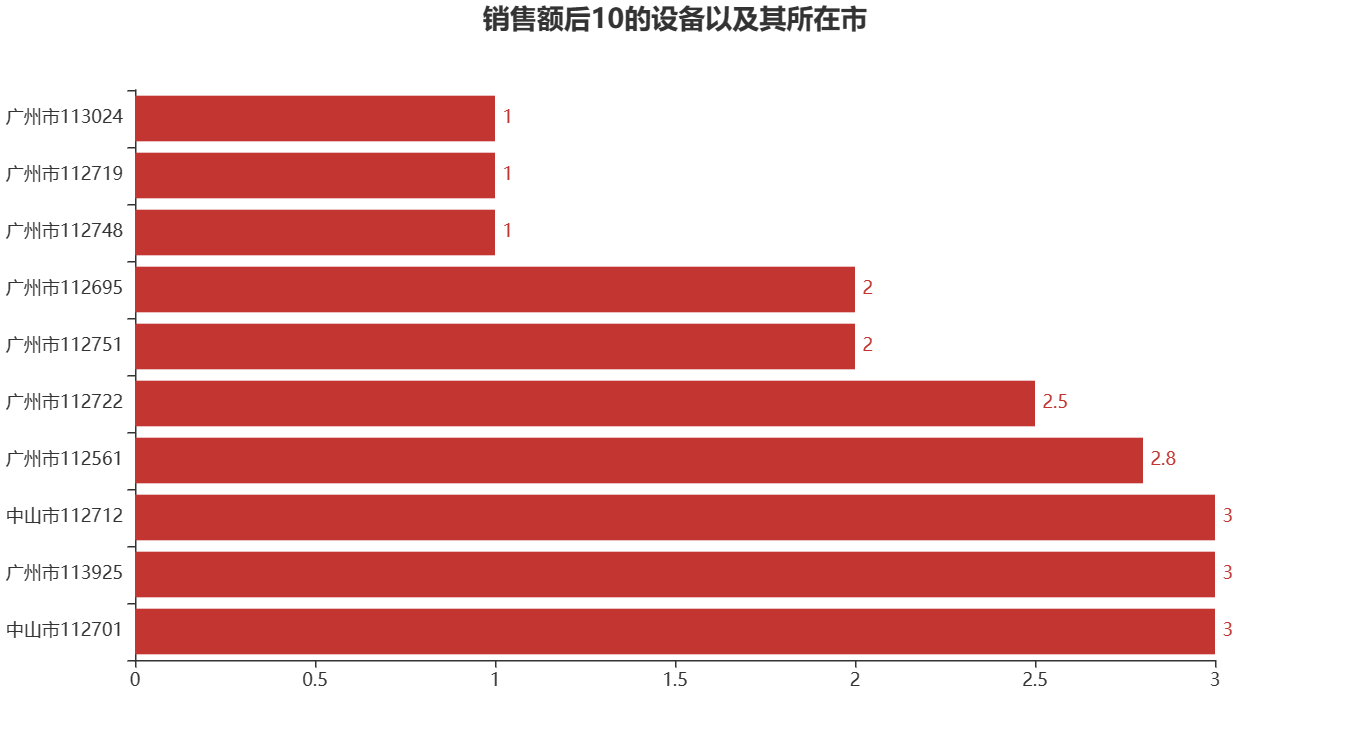
由右图可知, 广州市的设备 113024、112719、112748的销售额只有1元,而销售金额后10的
设备全部在广州市和中山市。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('order.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='设备编号',as_index=False).agg({'市':f,'总金额(元)':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['设备编号','市','销售总额']
data_x_xiao = groupby_month['设备编号'].values.tolist()
data_x_shi = groupby_month['市'].values.tolist()
data_y_shang = groupby_month['销售总额'].values.tolist()
# 最大值
#ascending 参数是一个布尔类型的参数,当它设置为 True 时,返回的结果将从小到大排序;当它设置为 False 时,返回的结果将从大到小排序。
#reset_index:会将原来的索引index作为新的一列
#sort_values()函数原理类似于SQL中的order by,可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
#groupby函数基本格式:data.groupby([‘分组字段’])
product_amount = data.groupby(['市','设备编号']).agg({'总金额(元)':'sum'}).sort_values(by='总金额(元)',ascending=False).reset_index()
#product_amount_1 = data.groupby('市').agg({'总金额(元)':'sum'}).sort_values(by='总金额(元)',ascending=False).reset_index()
a = product_amount.tail(10)
#b = product_amount_1.head(10)
# print(a)
#生成市+设备编号的列名
a["市设备编号"] = a["市"]+ a["设备编号"].map(str)
# d = a["市设备编号"].columns = ["市设备编号"]
# print(a["市设备编号"])
# #print(a["市设备编号"])
a_x = a['市设备编号'].tolist()
a_y = a['总金额(元)'].tolist()
# print(a)
# 实例化对象
line_1 = (
Bar()
.add_xaxis(a_x)
.reversal_axis()
.add_yaxis('总金额(元)',a_y)
.set_global_opts(
title_opts=opts.TitleOpts(title='销售额后10的设备以及其所在市',pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)#图例
#xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30)),
)
.set_series_opts(label_opts=opts.LabelOpts(position="right"))#标签数值的位
)
line_1.render('1.html')
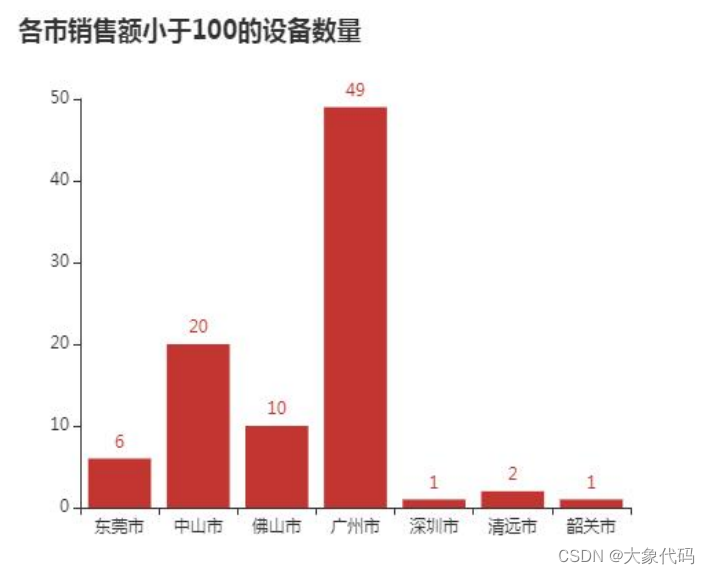
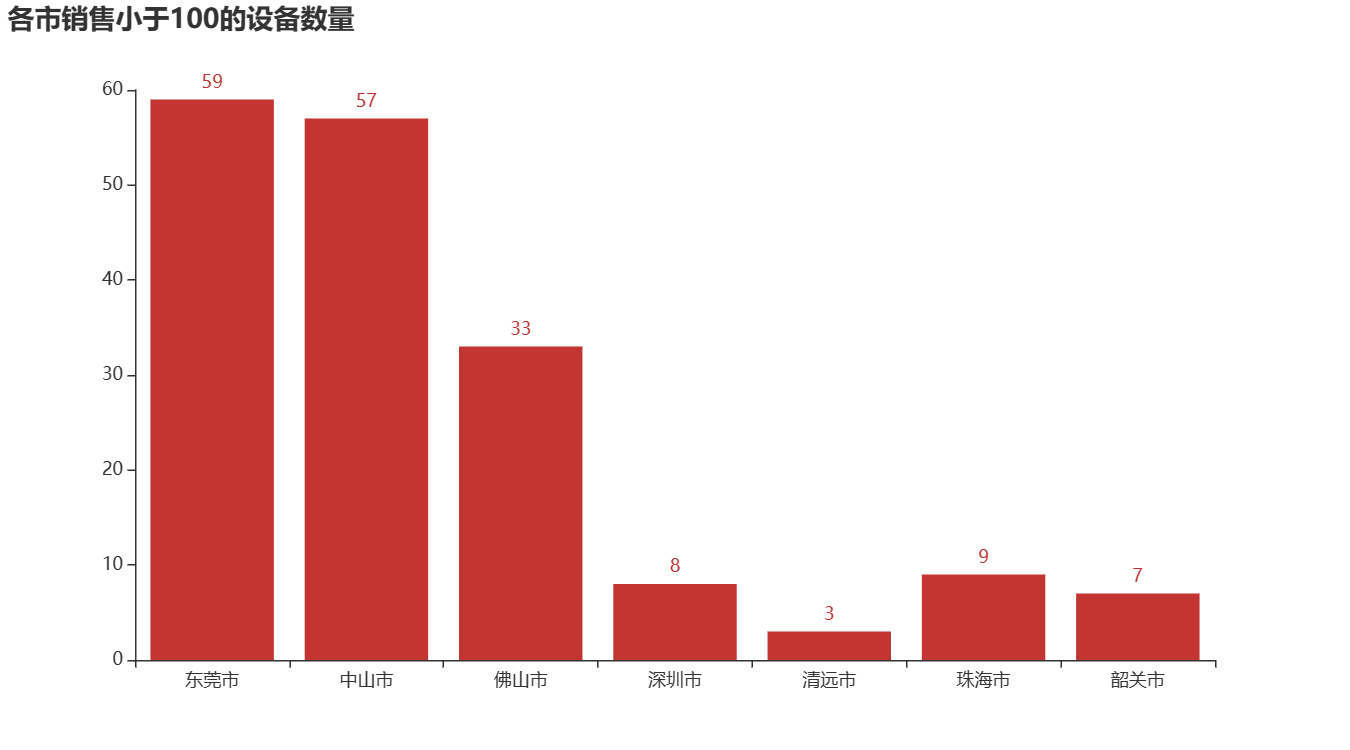
①统计各城市销售金额小于100的设备数量,并进行可视化分析。
②广州市销售金额小于100元的设备数量达到了49台,中山市有20台,深圳市和韶关市各有1台。而在图中并没有出现珠海市,这是因为珠海市中所有的新零售智能销售设备的销售金额都大于100元。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('order.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='市',as_index=False).agg({'设备编号':f})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['市','设备编号']
data_x_shi = groupby_month['市'].values.tolist()
data_y_xiao = groupby_month['设备编号'].values.tolist()
print(data_x_shi)
print(data_y_xiao)
# data_y = [list(z) for z in zip(data_y_xiao,data_y_shang)]
#小于100:销售额
a = groupby_month[groupby_month["设备编号"]< 100 ]
print(a)
a_x = a['市'].tolist()
a_y = a['设备编号'].tolist()
# 实例化对象
line_1 = (
Bar()
.add_xaxis(a_x)
.add_yaxis('',a_y)
.set_global_opts(
title_opts=opts.TitleOpts(title='各市销售小于100的设备数量',pos_left='left')
)
)
line_1.render('1.html')
绘制库存分析图
在库存管理中,需要对库存进行分析,实现库存合理配置,从而保证在正常的销售货源供应的同时,最大程度减少库存积压,提高资金的流通性。从库存角度出发,利用售罄率、库存成本、进货量、库存量和销售量等指标对库存进行分析,并进行可视化展示。
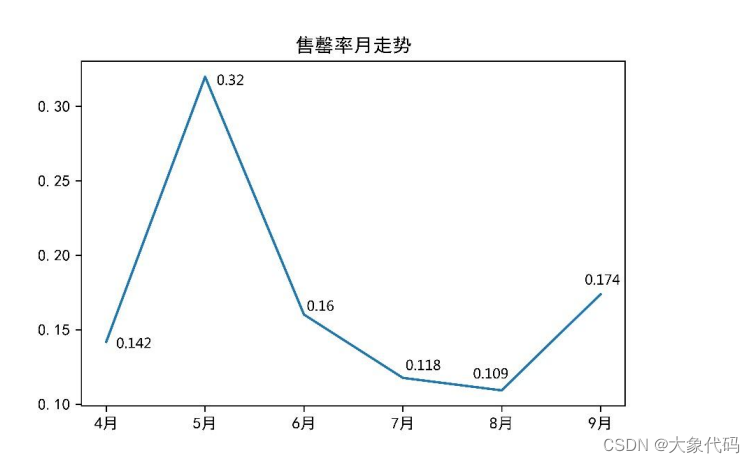
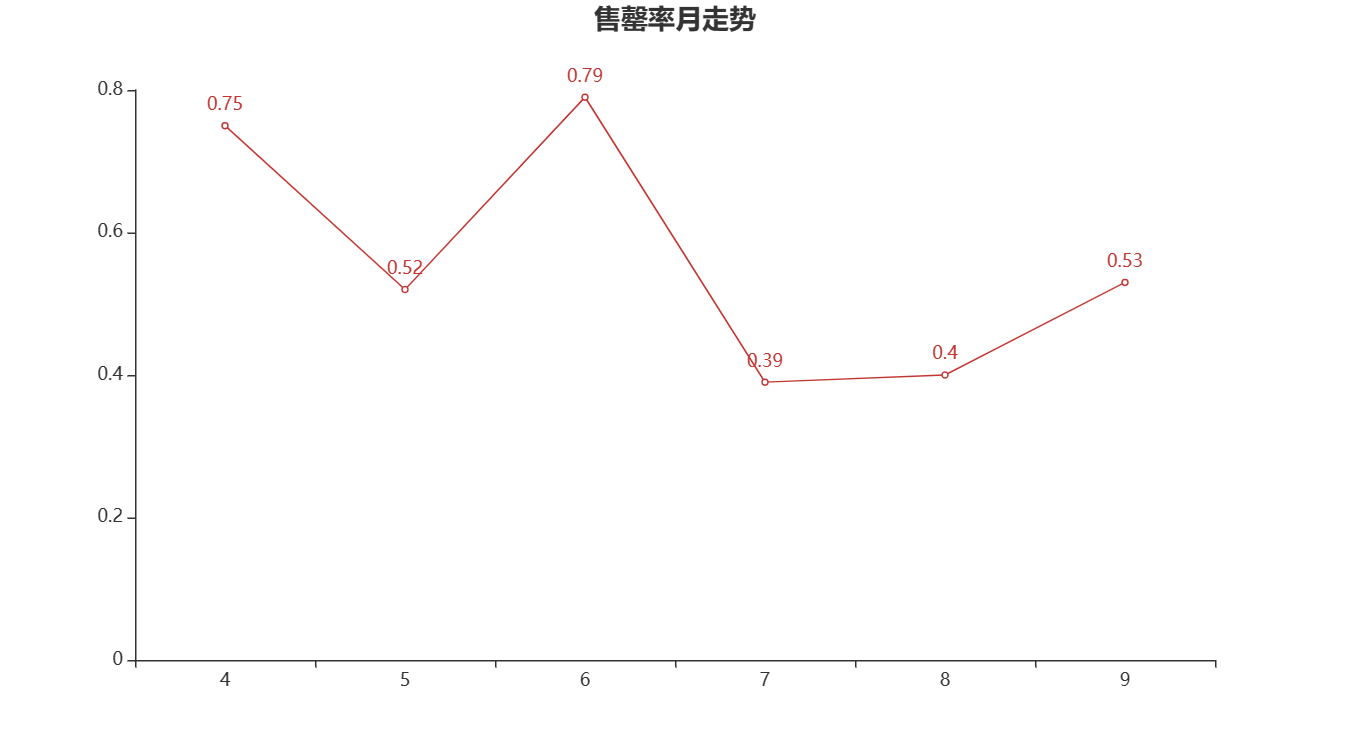
1.售罄率分析
①售罄率:是指产品的累计销售占总进货的比例,可用于反应商品的销售速度。其中销售和进货可以是数量,也可以是金额。售罄率的计算如下式所示。
售罄率=销售量/进货量
②分析近6个月商品整体的售罄率,并进行可视化分析。
③由右图可知,售罄率从5月到达0.3198后就开始一直下降,处于一个较低的水平,仍有很大的提升空间。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('goods_info.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='月份',as_index=False).agg({'销售数量':f,'进货数量':f})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['月份','销售数量','进货数量']
data_x_shi = groupby_month['月份'].values.tolist()
data_y_xiao = groupby_month['销售数量'].values.tolist()
data_y_jin = groupby_month['进货数量'].values.tolist()
data_moth_x = [str (i) for i in data_x_shi]
print(data_x_shi,data_y_xiao,data_y_jin)
#售罄率=销售量/进货量
a = []
for i in range(len(data_y_jin)):
a.append(groupby_month['销售数量'][i]/groupby_month['进货数量'][i])
groupby_month['售罄率']=a
# data_y = [list(z) for z in zip(data_y_xiao,data_y_shang)]
# #小于100:销售额
# a = groupby_month[groupby_month["设备编号"]< 100 ]
# print(a)
# a_x = a['市'].tolist()
# a_y = a['设备编号'].tolist()
# 实例化对象
line_1 = (
Line()
.add_xaxis(data_moth_x)
.add_yaxis('',np.round(groupby_month['售罄率'].values.tolist(),2))
.set_global_opts(
title_opts=opts.TitleOpts(title='售罄率月走势',pos_left='center')
)
)
line_1.render('1.html')
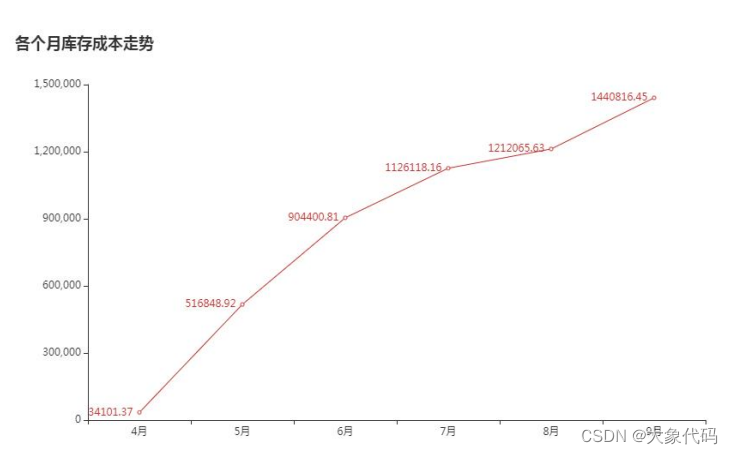
2.库存成本分析
①库存成本:是指在储存的仓库的商品所需的正本,其计算如下式所示。
库存成本=销售单价×库存量
②分析各个月库存成本走势,并进行可视化分析。
③由右图可知,4月~9月的库存成本在逐渐上升。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('goods_info.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='月份',as_index=False).agg({'库存数量':f,'销售金额':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['月份','销售金额','库存数量']
data_x_shi = groupby_month['月份'].values.tolist()
data_y_xiao = groupby_month['销售金额'].values.tolist()
data_y_jin = groupby_month['库存数量'].values.tolist()
data_moth_x = [str (i) for i in data_x_shi]
print(data_x_shi,data_y_xiao,data_y_jin)
#库存成本=销售单价×库存量
a = []
for i in range(len(data_y_jin)):
a.append(groupby_month['销售金额'][i]*groupby_month['库存数量'][i])
groupby_month['库存成本']=a
# data_y = [list(z) for z in zip(data_y_xiao,data_y_shang)]
# #小于100:销售额
# a = groupby_month[groupby_month["设备编号"]< 100 ]
# print(a)
# a_x = a['市'].tolist()
# a_y = a['设备编号'].tolist()
# 实例化对象
line_1 = (
Line()
.add_xaxis(data_moth_x)
.add_yaxis('',np.round(groupby_month['库存成本'].values.tolist(),2))
.set_global_opts(
title_opts=opts.TitleOpts(title='各个月库存成本走势',pos_left='left'),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter='{value}月')
)
)
)
line_1.render('1.html')
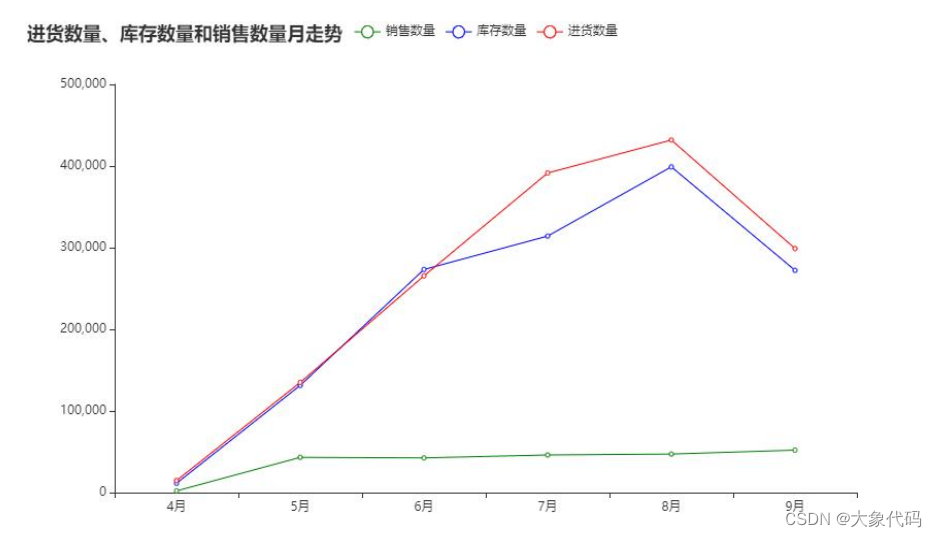
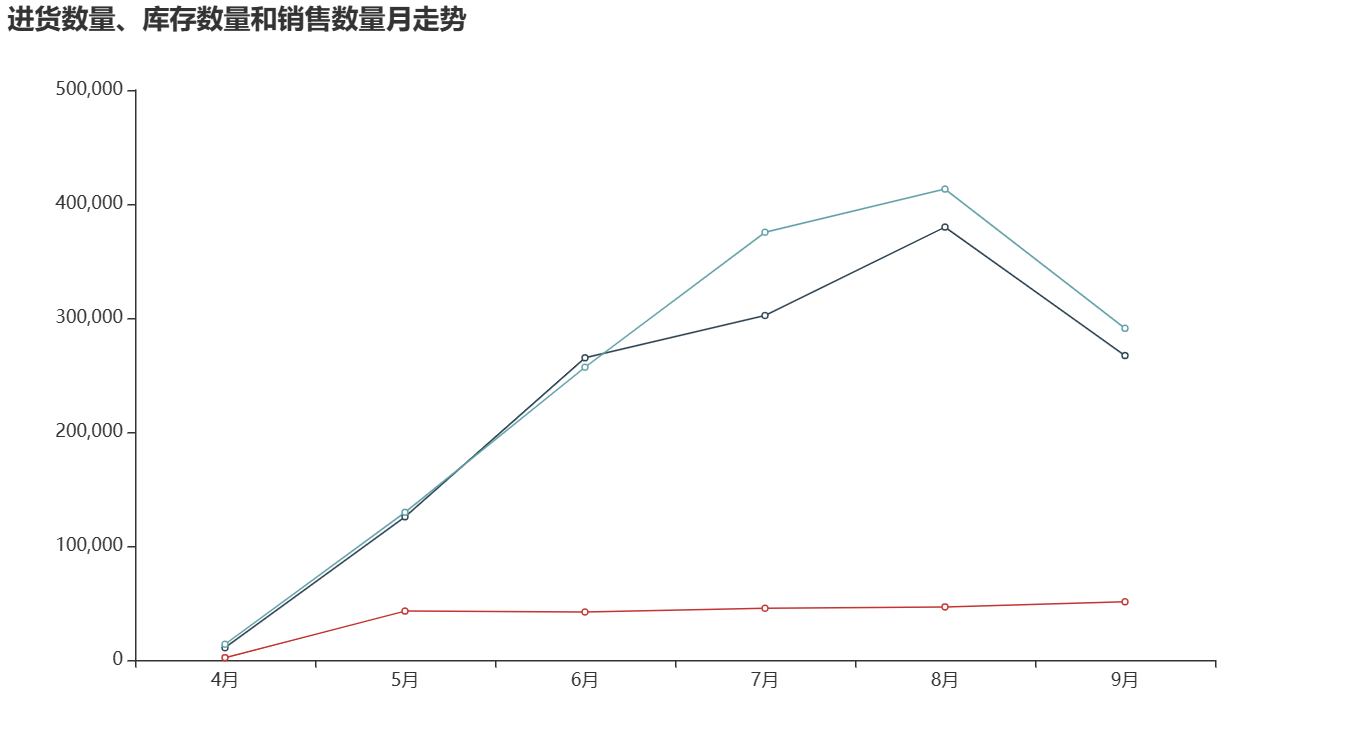
3.进货数量、库存数量和销售数量走势分析
①分析近6个月内进货量、库存量和销售量数据的走势,并进行可视化分析。
②由右图可知,库存量、进货量的走势基本保持一致,其中库存量与进货量的最高点为8月,最低点为4月。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('goods_info.csv',encoding='gbk')
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='月份',as_index=False).agg({'销售数量':np.sum,'库存数量':np.sum,'进货数量':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['月份','销售数量','库存数量','进货数量']
data_x_shi = groupby_month['月份'].values.tolist()
data_y_xiao = groupby_month['销售数量'].values.tolist()
data_y_ku = groupby_month['库存数量'].values.tolist()
data_y_jin = groupby_month['进货数量'].values.tolist()
data_moth_x = [str (i) for i in data_x_shi]
print(data_x_shi,data_y_xiao,data_y_jin,data_y_ku)
#data_y = [list(z) for z in zip(data_y_xiao,data_y_ku,data_y_jin)]
# 实例化对象
line_1 = (
Line()
.add_xaxis(data_moth_x)
.add_yaxis('',data_y_xiao,label_opts=opts.LabelOpts(is_show=False))
.add_yaxis('',data_y_ku,label_opts=opts.LabelOpts(is_show=False))
.add_yaxis('',data_y_jin,label_opts=opts.LabelOpts(is_show=False),)
.set_global_opts(
title_opts=opts.TitleOpts(title='进货数量、库存数量和销售数量月走势',pos_left='left'),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(formatter='{value}月')
),
yaxis_opts=opts.AxisOpts(
is_show=True
),
legend_opts=opts.LegendOpts(is_show=True)
)
)
line_1.render('1.html')
绘制用户分析图
对用户的购买行为进行分析,有助于了解用户的消费特点,提供个性化的服务,从而提升用户的忠诚度和商家的利润。从用户角度出发,利用支付状态、市、下单时间段等字段,对用户进行分析,并进行可视化展示。
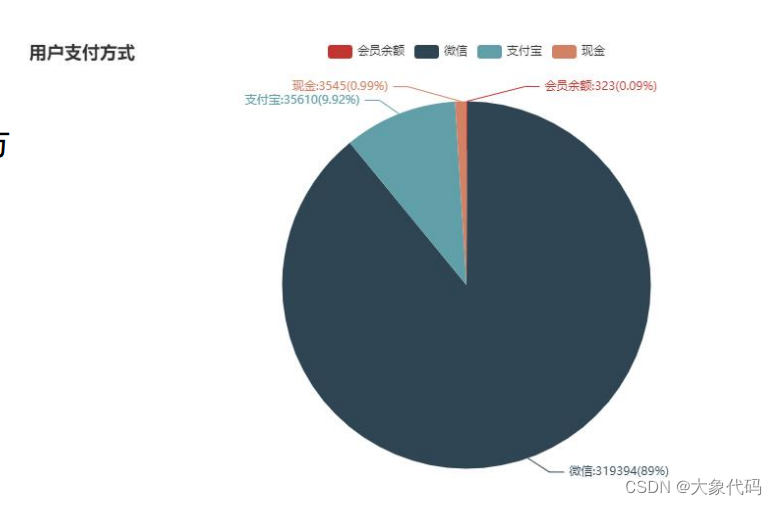
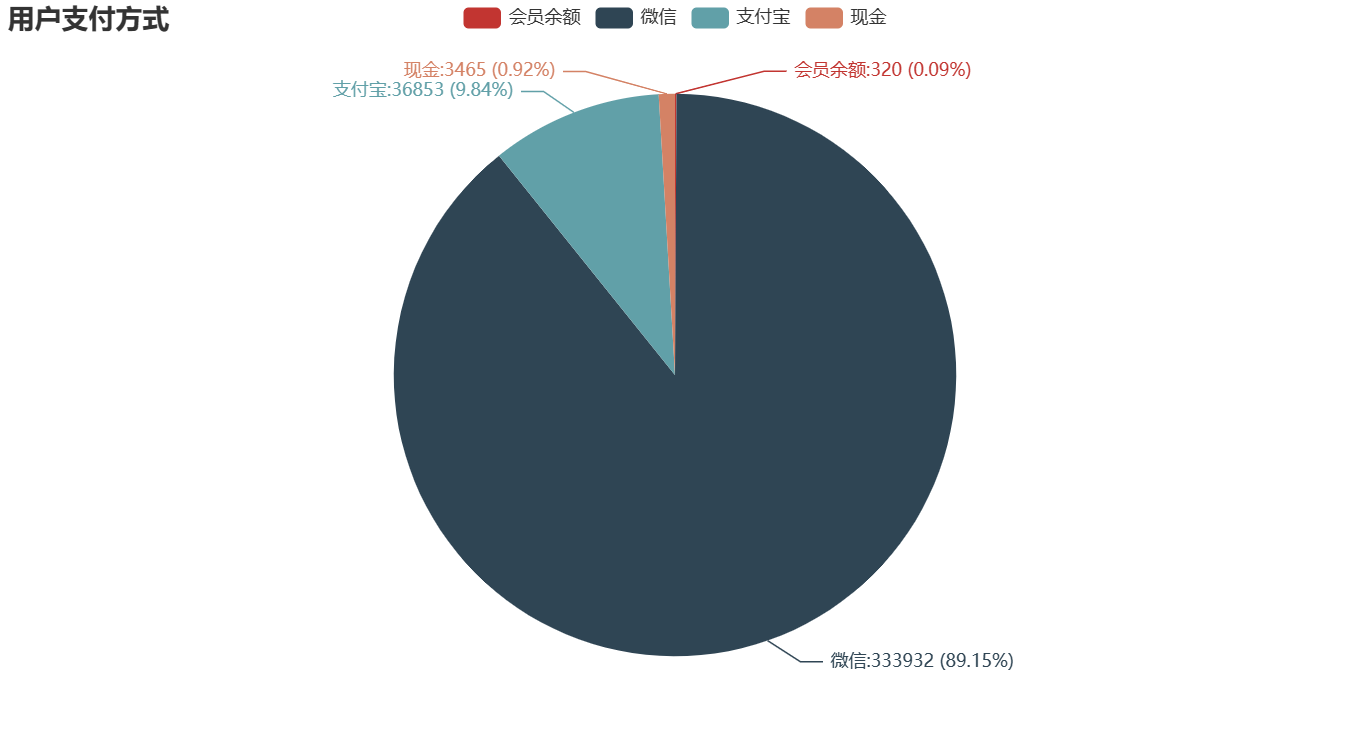
1.用户支付方式分析
①对用户在新零售智能销售设备上购买商品时使用的支付方式进行统计,并进行可视化分析。
②由右图可知,主要的支付方式有4种,即微信、支付宝、会员余额和现金,其中微信是最用户常用支付方式,占了总用户人数的89%。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar,Pie
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('order.csv',encoding='gbk')
#数据处理
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='支付状态',as_index=False).agg({'购买数量(个)':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['支付状态','购买数量']
data_x_shi = groupby_month['支付状态'].values.tolist()
data_y_xiao = groupby_month['购买数量'].values.tolist()
data_moth_x = [str (i) for i in data_x_shi]
# print(data_x_shi,data_y_xiao)
data_y = [list(z) for z in zip(data_x_shi,data_y_xiao)]
# 实例化对象
line_1 = (
Pie()
.add('',data_y)
.set_global_opts(
title_opts=opts.TitleOpts(title='用户支付方式',pos_left='left'),
legend_opts=opts.LegendOpts(is_show=True)
)
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{c} ({d}%)'))
)
line_1.render('1.html')
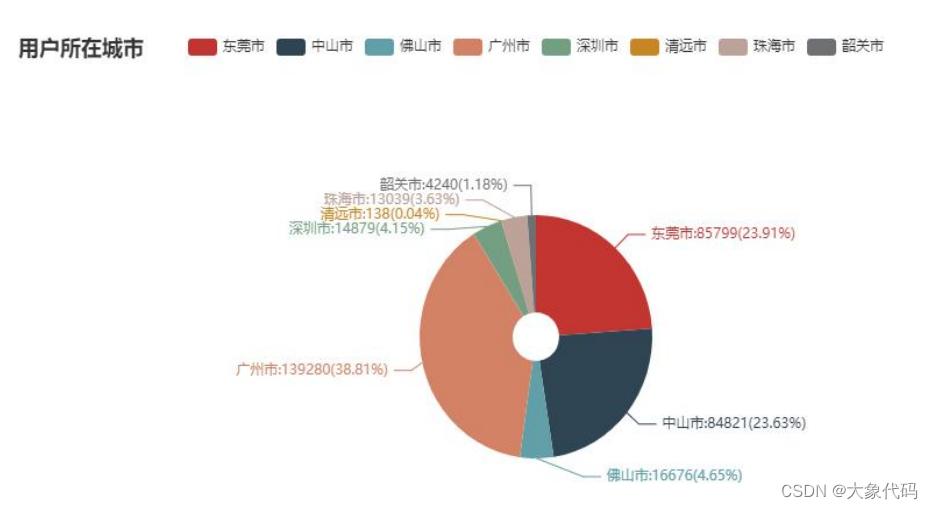
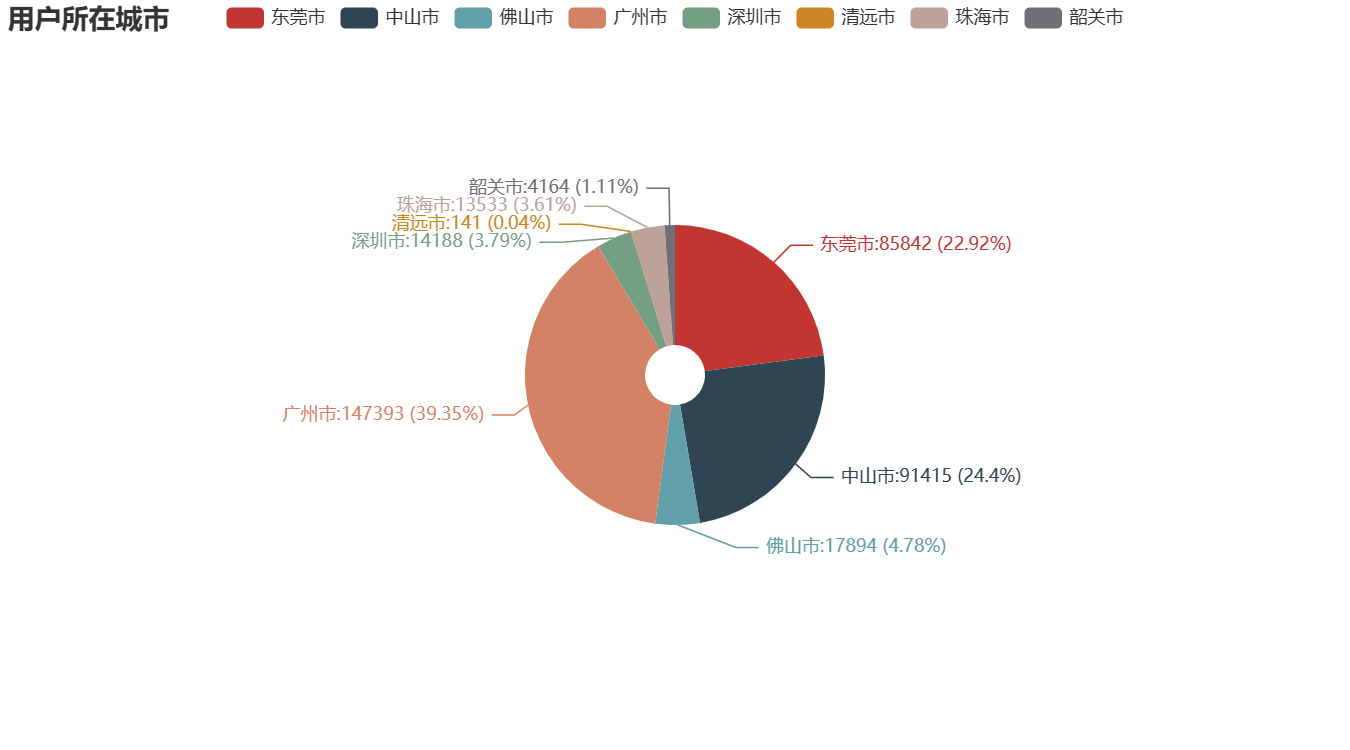
2.用户所在城市分析
①对各城市的用户数进行统计分析并进行可视化分析。
②由右图可知,使用新零售智能销售设备购买商品的用户最多的是广州市,其次是中山市和东莞市,而这3个城市的占比达到了86.35%。
import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar,Pie
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('order.csv',encoding='gbk')
#数据处理
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='市',as_index=False).agg({'购买数量(个)':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['市','购买数量']
data_x_shi = groupby_month['市'].values.tolist()
data_y_xiao = groupby_month['购买数量'].values.tolist()
data_moth_x = [str (i) for i in data_x_shi]
# print(data_x_shi,data_y_xiao)
data_y = [list(z) for z in zip(data_x_shi,data_y_xiao)]
# 实例化对象
line_1 = (
Pie()
.add('',data_y, radius=[20, 100])
.set_global_opts(
title_opts=opts.TitleOpts(title='用户所在城市',pos_left='left'),
legend_opts=opts.LegendOpts(is_show=True)
)
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{c} ({d}%)'))
)
line_1.render('1.html')
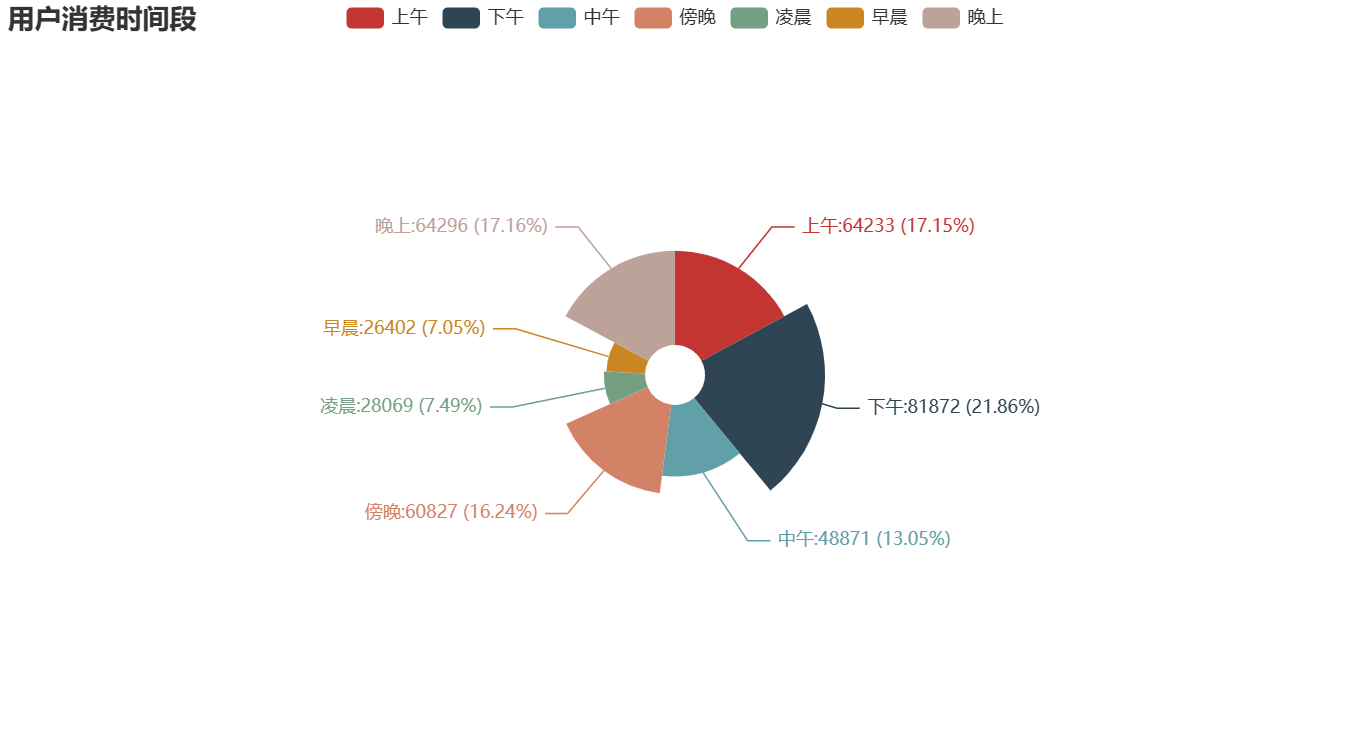
3.用户消费时段分析
①用户在新零售智能销售设备上购买的时间段进行统计分析,并进行可视化分析。
②由右图可知,近6个月,下午时间段消费的人数最多,占了21.26%,其次是晚上、上午和傍晚。早晨和凌晨的人数差不多,但是都比较少,只有7%左右。

import numpy as np# 导入 numpy库,as 即为导入的库起一个别称,别称为np
import pandas as pd
import heapq #获取数组中最大的前n个数值的位置索引
from pyecharts.charts import Line,Bar,Pie
from pyecharts import options as opts
from operator import itemgetter
data = pd.read_csv('order.csv',encoding='gbk')
#数据处理
#链式调用:调用完一个函数后还能再继续调用其它函数
def f(x):
#len()函数去计算长度;list() 构造函数创建列表;set顾名思义是集合,里面不能包含重复的元素,接收一个list作为参数
#x.values() 返回字典中的值
x = len(list(set(x.values)))
return x
#对多列进行分组:使用 groupby 方法进行多列分组
groupby_month = data.groupby(by='下单时间段',as_index=False).agg({'购买数量(个)':np.sum})
#columns:表示列索引
#顺序很重要
groupby_month.columns = ['下单时间段','购买数量']
data_x_shi = groupby_month['下单时间段'].values.tolist()
data_y_xiao = groupby_month['购买数量'].values.tolist()
data_moth_x = [str (i) for i in data_x_shi]
# print(data_x_shi,data_y_xiao)
data_y = [list(z) for z in zip(data_x_shi,data_y_xiao)]
# 实例化对象
line_1 = (
Pie()
.add('',data_y, rosetype='radius', radius=[20, 100])
.set_global_opts(
title_opts=opts.TitleOpts(title='用户消费时间段',pos_left='left'),
legend_opts=opts.LegendOpts(is_show=True)
)
.set_series_opts(label_opts=opts.LabelOpts(formatter='{b}:{c} ({d}%)'))
)
line_1.render('1.html')


















 602
602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









