









 该文章介绍了如何使用feapder框架来抓取网页数据,特别是处理需要点击加载更多才能获取的新数据。首先,通过DevTools分析请求头和请求方式,然后设置下载中间件以模拟POST请求。接着,解析页面数据,利用XPath选择器提取信息。最后,将抓取到的数据存储到MongoDB数据库中,详细展示了数据库配置和数据入库的过程。
该文章介绍了如何使用feapder框架来抓取网页数据,特别是处理需要点击加载更多才能获取的新数据。首先,通过DevTools分析请求头和请求方式,然后设置下载中间件以模拟POST请求。接着,解析页面数据,利用XPath选择器提取信息。最后,将抓取到的数据存储到MongoDB数据库中,详细展示了数据库配置和数据入库的过程。
进入网页之后,打开DevTools,刷新网页获取请求,查看请求中的信息,发现所需数据属于静态,但是需要通过点击网页中的加载更多,才会有一个新的请求, 包含新的数据。
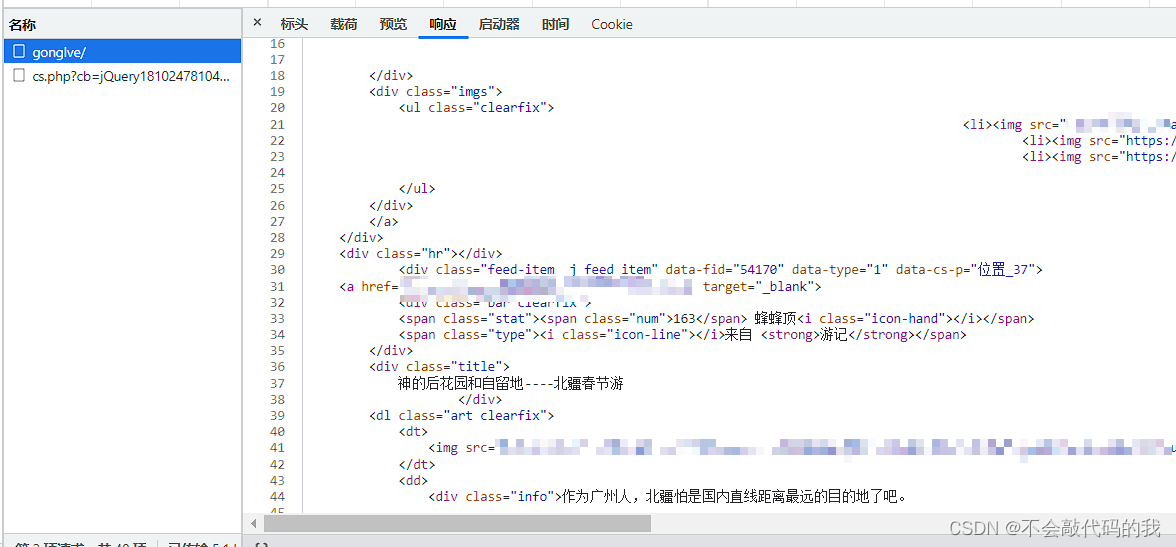
点击请求,查看请求头中信息,看是否需要带一些参数,经过测试,cookie等可以不需要带,就日常带些参数,在feapder的中间件可以设置请求头和请求方式。
def download_midware(self, request):
"""自定义的下载中间件 全局 进行一些request设置"""
request.headers = {
'accept': '*/*',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
}
request.method = "POST"
return request接着查看载荷中的数据,显示用表单数据,请求中就用data格式,不需要用JSON格式,将其在feapder的函数中定义,并将回调至parse函数
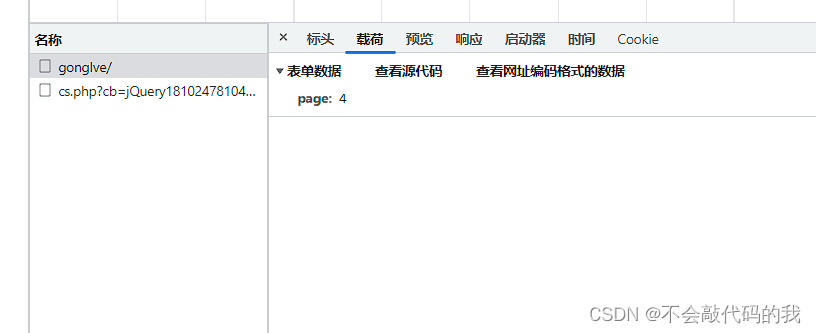
def start_requests(self):
"""发送请求"""
data = {'page': 1}
yield feapder.Request("https://www.xxx.cn/gonglve/", data=data, callback=self.parse)发送请求后,在parse函数中就可以进行数据的匹配,feapder可选用多种库进行匹配,在这里以xpath作为示例,网页元素的xpath路径可以通过点击网页元素右键进行复制路径,然后进行自己调整。
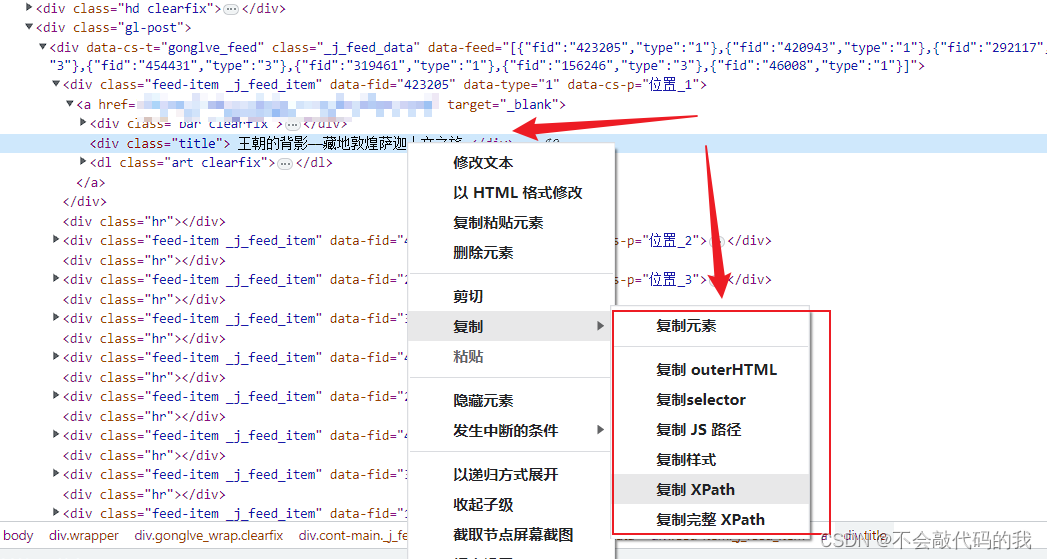
在这里选择了选取class=“feed-item _j_feed_item”结点,xpath选取含有多个名称的属性需要用到contains。然后通过遍历,从单个节点中在匹配自己所需要的数据。
data_list = response.xpath(
'//div[contains(@class,"feed-item") and contains(@class,"_j_feed_item")]')feapder中xpath使用方法与原xpath略有不同,不需要使用etree.HTML(),且提取数据时,要带上.extract_first()
data.xpath('./a/div[@class="title"]/text()').extract_first()最后将所需采集数据进行匹配后,可以开始保存数据,这里采用的是MongoDB数据库存取,先进行数据库设置。
"""进行数据库设置"""
__custom_setting__ = dict(
ITEM_PIPELINES=["feapder.pipelines.mongo_pipeline.MongoPipeline"],
# 是否连接本地
MONGO_IP="localhost",
# 端口
MONGO_PORT=27017,
# 数据库名
MONGO_DB="feapder",
MONGO_USER_NAME="",
MONGO_USER_PASS="",
)feapder存储数据需要先进行导入ITem,然后生成对象item,以item.自己所设存取列名 = 匹配的数据,最后yield item 批量入库。
item = ITem()如果使用for循环批量存取,要放入for循环内部,不能在for循环外部,在外面会导致存储的数据重复,缺失。
item = Item()
# 指定存储的表名 item.列名 = 值
item.table_name = "test_mongo1"
item.title = str(data.xpath('./a/div[@class="title"]/text()').extract_first()).replace(' ', '').replace('\n', '')
print(str(data.xpath('./a/div[@class="title"]/text()').extract_first()).replace(' ', '').replace('\n', ''))
item.picture_url = data.xpath('./a/@href').extract_first()
item.person_num = data.xpath('./a/div[4]/ul/li[4]/text()').extract_first() if data.xpath(
'./a/div[4]/ul/li[4]/text()').extract_first() else ''
item.text = data.xpath('./a/dl/dd/div[1]/text()').extract_first() if data.xpath(
'./a/dl/dd/div[1]/text()').extract_first() else ''
item.comment = str(data.xpath('./a/div[1]/span[1]/span/text()').extract_first()) + str(data.xpath('./a/div[1]/span[1]/text()').extract_first())
item.source = str(data.xpath('./a/div[1]/span[2]/text()').extract_first()) + str(data.xpath('a/div[1]/span[2]/strong/text()').extract_first())
# 一键入库
yield item完整代码如下:
import feapder
from feapder import Item
class Mafengwo(feapder.AirSpider):
"""进行数据库设置"""
__custom_setting__ = dict(
ITEM_PIPELINES=["feapder.pipelines.mongo_pipeline.MongoPipeline"],
# 是否连接本地
MONGO_IP="localhost",
# 端口
MONGO_PORT=27017,
# 数据库名
MONGO_DB="feapder",
MONGO_USER_NAME="",
MONGO_USER_PASS="",
)
def start_requests(self):
"""发送请求"""
for page in range(1, 500):
data = {'page': page}
yield feapder.Request("https://www.xxx.cn/gonglve/", data=data, callback=self.parse)
def download_midware(self, request):
"""自定义的下载中间件 全局 进行一些request设置"""
request.headers = {
'accept': '*/*',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36',
}
request.method = "POST"
return request
def parse(self, request, response):
"""抓取数据并保存"""
data_list = response.xpath(
'//div[@class="_j_feed_data"]/div[contains(@class,"feed-item") and contains(@class,"_j_feed_item")]')
for data in data_list:
# 声明一个item
item = Item()
# 指定存储的表名 item.列名 = 值
item.table_name = "test_mongo1"
item.title = str(data.xpath('./a/div[@class="title"]/text()').extract_first()).replace(' ', '').replace(
'\n', '')
print(str(data.xpath('./a/div[@class="title"]/text()').extract_first()).replace(' ', '').replace(
'\n', ''))
item.picture_url = data.xpath('./a/@href').extract_first()
item.person_num = data.xpath('./a/div[4]/ul/li[4]/text()').extract_first() if data.xpath(
'./a/div[4]/ul/li[4]/text()').extract_first() else ''
item.text = data.xpath('./a/dl/dd/div[1]/text()').extract_first() if data.xpath(
'./a/dl/dd/div[1]/text()').extract_first() else ''
item.comment = str(data.xpath('./a/div[1]/span[1]/span/text()').extract_first()) + str(data.xpath(
'./a/div[1]/span[1]/text()').extract_first())
item.source = str(data.xpath('./a/div[1]/span[2]/text()').extract_first()) + str(data.xpath(
'a/div[1]/span[2]/strong/text()').extract_first())
# 一键入库
yield item
if __name__ == "__main__":
# tread_count 设置线程数 最大32
Mafengwo(thread_count=10).start()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









