







整体架构
NodeManager(NM)是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点,包括与ResourceManger保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
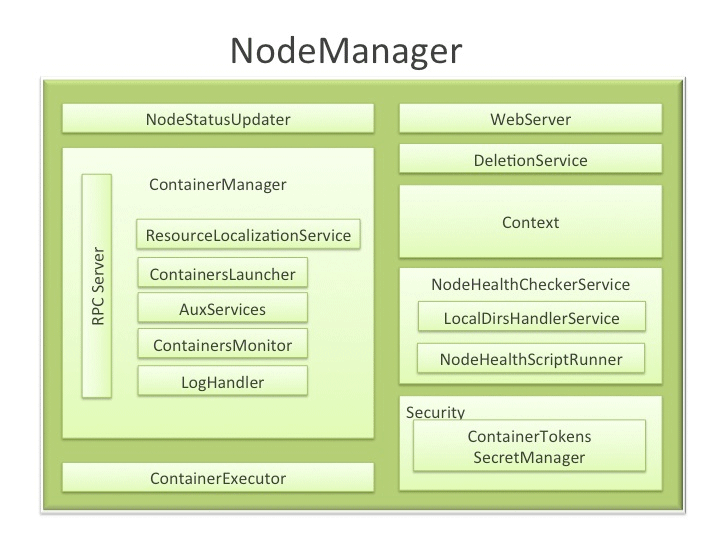
【NodeStatusUpdater】
当NM启动时,该组件向RM注册,并发送节点上可用资源。接下来,NM与RM通信,汇报各个Container的状态更新,包括节点上正运行的Container、已完成的Contaner等。
此外,RM可能向NodeStatusUpdater发信号,杀死处于运行中的Container。
注:NodeStatusUpdater是NM与RM通信的唯一通道,它实际上是RPC协议ResourceTracker的client,它周期性地调用RPC函数nodeHeartbeat()向RM汇报本节点上各种信息,包括资源使用情况,各个Container运行情况等。
【ContainerManager】
它是NodeManager中核心组件,它由以下几个子组件构成,每个子组件负责一部分功能,以管理运行在该节点上的所有Container。(注意,ContainerManager实际上是个接口,真正的实现是ContainerManagerImpl类)
(1)RPC Server ContainerManager从各个Application Master上接收RPC请求以启动Container或者停止正在运行的Container。它与ContainerTokenSecretManager(下面将介绍)合作,以对所有请求进行合法性验证。所有作用在正运行Container的操作均会被写入audit-log,以便让安全工具进行后续处理。
注:这里的“RPC Server”实际上是RPC协议ContainerManager的server,AM可通过该协议通知某个节点启动或者释放container,ContainerManager定义了三个接口供AM使用:
StartContainerResponse startContainer(StartContainerRequest request); //启动container
StopContainerResponse stopContainer(StopContainerRequest request); //释放container
GetContainerStatusResponse getContainerStatus(GetContainerStatusRequest request);//获取container列表。(2)ResourceLocalizationService 负责(从HDFS上)安全地下载和组织Container需要的各种文件资源。它尽量将文件分摊到各个磁盘上。它会为下载的文件添加访问控制限制,并为之施加合适的(磁盘空间)使用上限。
注:该服务会采用多线程方式同时从HDFS上下载文件,并按照文件类型(public或者private文件)存放到不同目录下,并为目录设置严格的访问权限,同时,每个用户可使用的磁盘空间大小也可以设置。
(3)ContainersLauncher 维护了一个线程池,随时准备并在必要时尽快启动Container,同时,当收到来自RM或者 ApplicationMaster的清理Container请求时,会清理对应的Container进程。
(4)AuxServices NM提供了一个框架以通过配置附属服务扩展自己的功能,这允许每个节点定制一些特定框架可能需要的服务,当然,这些服务是与NM其他服务隔离开的(有自己的安全验证机制)。附属服务需要在NM启动之前配置好,且由对应应用程序的运行在本节点上的第一container触发启动。
(5)ContainersMonitor 当一个Container启动之后,该组件便开始观察它在运行过程中的资源利用率。为了实现资源隔离和公平共享,RM为每个Container分配了一定量的资源。ContainersMonitor持续监控每个Container的利用率,一旦一个Container超出了它的允许使用份额,它将向Container发送信号将其杀掉,这可以避免失控的Container影响了同节点上其他正在运行的Container。(注意,ContainersMonitor实际上是个接口,真正的实现是ContainersMonitorImpl类)。
注:NM启动一个container后,ContainersMonitor会将该container进程对一个的pid添加到监控列表中,以监控以pid为根的整棵进程树的资源使用情况,它周期性地从/etc/proc中获取进程树使用的总资源,一旦发现超过了预期值,则会将其杀死。在最新版YARN中,已采用了Linux container对资源进行隔离。
(6)LogHandler 一个可插拔组件,用户通过它可选择将Container日志写到本地磁盘上还是将其打包后上传到一个文件系统中。
【ContainerExecutor】
与底层操作系统交互,安全存放Container需要的文件和目录,进而以一种安全的方式启动和清除Container对应的进程。
注:在最新版YARN中,已采用了Linux container对资源进行隔离
【NodeHealthCheckerService】
提供以下功能:通过周期性地运行一个配置好的脚本检查节点的健康状况,它也会通过周期性地在磁盘上创建临时文件以监控磁盘健康状况。任何系统健康方面的改变均会通知NodeStatusUpdater(前面已经介绍过),它会进一步将信息传递给RM。
【Security】
(1) ApplicationACLsManager NM需要为所有面向用户的API提供安全检查,如在Web-UI上只能将container日志显示给授权用户。该组件为每个应用程序维护了一个ACL列表,一旦收到类似请求后会利用该列表对其进行验证。
(2) ContainerTokenSecretManager 检查收到的各种访问请求的合法性,确保这些请求操作已被RM授权。
【WebServer】
在给定时间点,展示该节点上所有应用程序和container列表,节点健康相关的信息和container产生的日志。
【主要功能亮点】
启动Container
为了能够启动Container,NM期望收到的Container定义了关于它运行时所需的详细信息,包括运行container的命令、环境变量、所需的资源列表和安全令牌等。
一旦收到container启动请求,如果YARN启用了安全机制,则NM首先验证请求合法性以对用户和正确的资源分配进行授权。之后,NM将按照以下步骤启动一个container:
(1) 在本地拷贝一份运行Container所需的所有资源(通过Distributed Cache实现)。
(2) 为container创建经隔离的工作目录,并在这些目录中准备好所有(文件)资源。
(3) 运行命令启动container
日志聚集
处理用户日志是过去令人头痛的事情之一。与MRv1不同,NM不再截取日志并将日志留单个节点(TaskTracker)上,而是将日志上传到一个文件系统中,比如HDFS,以此来解决日志管理问题。
在某个NM上,所有属于同一个应用程序的container日志经聚集后被写到(可能经过压缩处理)一个FS上的日志文件中,用户可通过YARN命令行工具,WEB-UI或者直接通过FS访问这些日志。
MapReduce shuffle如何利用NM的附属服务
运行MapReduce程序所需的shuffle功能是通过附属服务实现的,该服务会启动一个Netty Server,它知道如何处理来自Reduce Task的MR相关的shuffle请求。MR(MapReduce) AM(ApplicationMaster)为shuffle服务定义了服务ID,和可能需要的安全令牌,而NM向AM提供shuffle服务的运行端口号,并由AM传递给各个Reduce Task。
结论
在YARN中,NodeManager主要用于管理抽象的container,它只处理container相关的事情,而不必关心每个应用程序(如MapReduce Task)自身的状态管理,它也不再有类似于map slot和reduce slot的slot概念,正是由于上述各个模块间清晰的责任分离,NM可以很容易的扩展,且它的代码也更容易维护。
节点健康状况检测
节点健康状况检测是YARN为每个NodeManager提供的机制,通过该机制,NodeManager可通过心跳机制将节点健康状况实时汇报给ResourceManager,而ResourceManager则会根据每个NodeManager的健康状况适当调整分配的任务数目。当NodeManager认为自己的健康状况“欠佳”时,可让ResourceManager不再分配任务,待健康状况好转时,再分配新任务。
实现原理
NodeManager上有专门一个服务判断所在节点的健康状况,该服务通过两种办法判断 节点健康状况,第一种是通过管理员自定义的Shell脚本,NodeManager上专门有一个周期性任务执行该脚本,一旦该脚本输出以“ERROR”开头的字符串,则认为节点处于不健康状态,另一种是判断磁盘好坏,NodeManager上专门有一个周期性任务检测磁盘的好坏,如果坏磁盘数目达到一定的比例,则认为节点处于不健康状态。
(1)编写健康状况检测脚本
管理员需编写一个shell脚本,当认为节点处于不健康状态时,输出一个以“ERROR”开头的字符串,一段伪代码如下:
#! /bin/bash
If [ free memory is lower than 1GB ];do
echo “ERROR, free memory is lower than 1GB!”
done然后管理员通过参数yarn.nodemanager.health-checker.script.path在yarn-site.xml中指定脚本所在位置。这样,当剩余内存量低于1GB时,NodeManager会将健康状况置为false,并通过心跳机制 汇报给ResourceManager,当ResourceManager收到该消息后,将该节点移到黑名单中,不再为其分配新任务,直到健康状况为true。
(2) 检测磁盘好坏
NodeManager会通过参数yarn.nodemanager.local-dirs和yarn.nodemanager.log-dirs配置一系列目录(磁盘),用于存储Application中间结果(比如MapReduce中Map Task的中间输出结果)和日志文件。NodeManager上专门有一个周期性任务检测这些目录的好坏,一旦发现正常磁盘的比例低于yarn.nodemanager.disk-health-checker.min-healthy-disks(默认是25%),则认为该节点处于“不健康”的状态。管理员可通过参数yarn.nodemanager.disk-health-checker.enable设置是否启用该功能,默认情况下是启用的。
NodeManager判断一个目录(磁盘)好坏的方法是,当它同时满足以下条件时才认为是正常目录:可读、可写、写执行。
container启动过程分析
概述
Container启动命令是由各个ApplicationMaster通过RPC函数ContainerManager.startContainer()向NodeManager发起的,Container启动过程主要经历三个阶段:资源本地化、启动并运行container、资源回收,其中,资源本地化指创建container工作目录,从HDFS下载运行container所需的各种资源(jar包、可执行文件等)等,而资源回收则是资源本地化的逆过程,它负责清理各种资源,它们均由ResourceLocalizationService服务完成的。启动container是由ContainersLauncher服务完成的,而运行container是由插拔式组件ContainerExecutor完成的,YARN提供了两种ContainerExecutor实现,一种是DefaultContainerExecutor,另一种是LinuxContainerExecutor。
资源本地化
资源本地化是指准备container运行所需的环境,包括创建container工作目录,从HDFS下载运行container所需的各种资源(jar包、可执行文件等)等。
YARN将资源分为两类,一类是public级别的资源,这类资源被放到一个公共目录下,由所有用户共享,另一类是private级别的资源,这类资源是用户私有的,只能在所属用户的各个作业间共享。资源本地化过程实际上就是准备public和private资源的过程,它由ResourceLocalizationService服务完成,其中,所有application的public资源由专门的线程PublicLocalizer下载完成,该线程内部维护了一个线程池以加快资源下载速度,每个application的private资源由一个专门的线程LocalizerRunner下载完成。
启动Container
启动Container是由ContainersLauncher完成的,该过程主要工作是将运行container对应的完整shell命令写到私有目录下的launch_container.sh中,并将token文件写到container_tokens中。之所以要将container运行命令写到launch_container.sh中,然后通过运行shell脚本的形式运行container,主要是因为直接执行命令可能会有些特殊符号不识别。
运行Container
而运行container是由插拔式组件ContainerExecutor完成的,YARN提供了两种ContainerExecutor实现,一种是DefaultContainerExecutor,另一种是LinuxContainerExecutor。DefaultContainerExecutor只是简单的以管理员身份运行launch_container.sh脚本,而LinuxContainerExecutor则是以container所属用户身份运行该脚本,它是Hadoop引入安全机制后加入的,此外,在不久的将来,container会引入cgroups隔离cpu资源,相关的代码也会存放在LinuxContainerExecutor中。
资源回收
资源回收由ResourceLocalizationService服务完成的,该过程与资源本地化正好相反,它负责撤销container运行过程中使用的各种资源。
资源隔离方案
YARN对内存资源和CPU资源采用了不同的资源隔离方案。对于内存资源,为了能够更灵活的控制内存使用量,YARN采用了进程监控的方案控制内存使用,即每个NodeManager会启动一个额外监控线程监控每个container内存资源使用量,一旦发现它超过约定的资源量,则会将其杀死。采用这种机制的另一个原因是Java中创建子进程采用了fork()+exec()的方案,子进程启动瞬间,它使用的内存量与父进程一致,从外面看来,一个进程使用内存量可能瞬间翻倍,然后又降下来,采用线程监控的方法可防止这种情况下导致swap操作。对于CPU资源,则采用了Cgroups进行资源隔离。















 9835
9835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









