






 本文分享如何利用Excel的PowerQuery和Python的pandas库,高效整理来自30个省份的公开授信资料,通过代码实现批量读取、数据清洗及筛选,降低人工操作的复杂度。
本文分享如何利用Excel的PowerQuery和Python的pandas库,高效整理来自30个省份的公开授信资料,通过代码实现批量读取、数据清洗及筛选,降低人工操作的复杂度。
重写博客,后续会写一些和工作相关的代码。
- 一来将有关经历保存,有事没事翻翻看,提高熟练度。
- 二来也算是做个分享,自己边查资料边提高的过程也是蛮好的。
PS.数据来自于公司公告和交易市场披露,【企业预警通下载】。
背景:最近得到了30个省份的公开授信资料(官方披露信息),由于涉及30个省,正常复制粘贴到一张汇总表,劳民伤财不讨好,而且复制粘贴的时候有序号,极有可能出错。
观察发现30个省份的字段都一样,那么采用excel或者python做自动化处理。
一、Excel
最直观的方法是用excel,3张表直接手动复制粘贴,对准表头;30张表可以用powerquery模块,操作为:
新建一个xlsx,点击最上边「数据」-「获取数据」-「自文件」,这里注意
1.如果是一个文件夹下多个excel,勾选自文件夹,然后全选导入;
2.如果是一个excel多个sheet页,勾选自excel工作簿,然后导入。

我的源文件保存形式是第二种,选择第二种操作,随后弹出导航器,
选择“选择多项”,点击第一个随后摁住shift点击最后一个进行全选
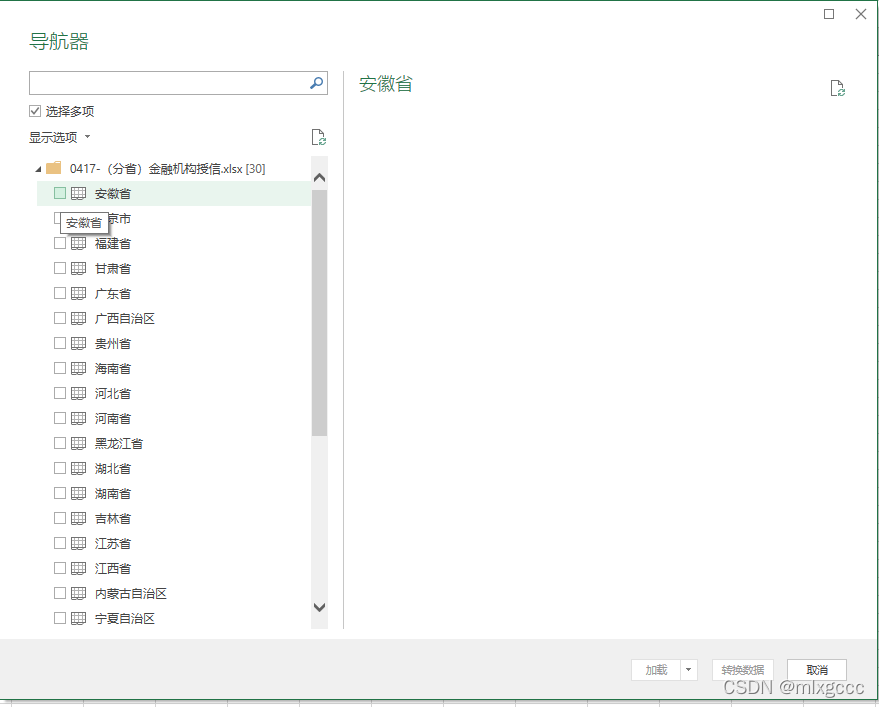
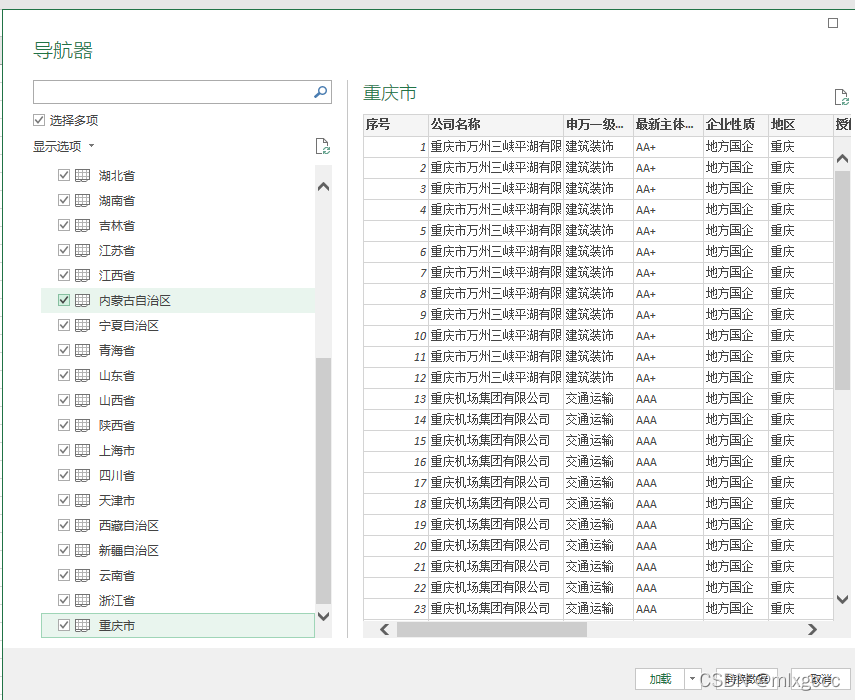
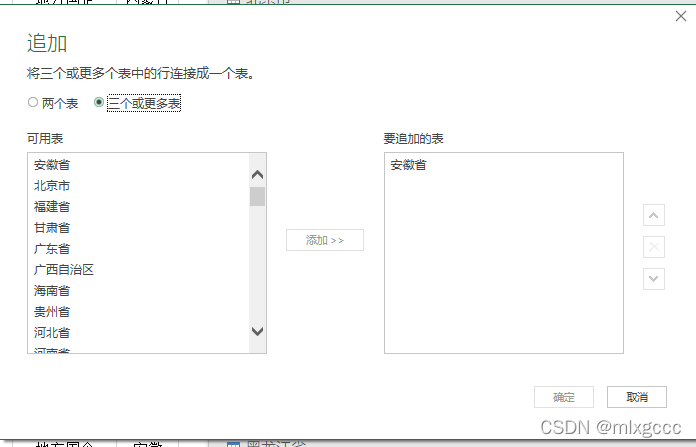
excel会自动进行加载,我的数据量较小,30个sheet页合计6万多条,excel加载了2min,加载好会在页面右侧出现“查询&连接"字样,点击任意第一个省份,然后右键:追加,随后勾选“三个或更多表”,接着老规矩,shift选中全部再确定,最后点击左上角“关闭并上载”等待数据加载好。
等待几分钟后,数据加载完成。
如果有筛选要求,可以在powerquery的界面上进行操作。
补充,遍历宏的操作:
很多个sheet页如果有冻结窗格、固定删除某一列,调整字体格式等等对单一sheet页操作,省时省力的方法是自己录制一个宏,然后用VBA包进去。
比如上述30个分省sheet页,我是需要冻结首行。具体操作为:
「开发工具」-「录制宏」-(执行冻结操作)-「结束录制」,命名为宏1
然后将宏1包在以下代码(在VBA宏操作界面输入):
Sub test()
n = Worksheets.Count
For i = 1 To n
Worksheets(i).Activate
Macro1
Next
End Sub
然后在开发工具-宏的位置点击以下“test”,一步到位。
二、python-pandas
python几行代码一步到位
- 索引读取
import pandas as pd
#依次读取前面30个工作表到DataFrame中,dfs里面是由30个DataFrame组成的数组
dfs = [pd.read_excel("data.xls",sheet_name=index) for index in range(30)]
#连接dfs里面的30个DataFrame
df = pd.concat(dfs)
倒杯水的功夫已经读取完了,并且python只保留了第一个表的表头。
- pd.read_excel的方法读取
import pandas as pd
# sheet_name = None 表示不指定某一sheet,直接看全部
dfs = pd.read_excel('0417-(分省)金融机构授信.xlsx',sheet_name=None)
df = pd.concat(dfs)
文件读取好后,需要对某列文字进行筛分;
由于原始数据比较杂,我们发现有以下几个问题:
1.标识不一致,有 “建设银行、建信、建行”等字段;
2.颗粒度不一。有的是“中国建设银行”,有的是“建设银行马栏山支行”等等;
所以对数据进行简单清洗。(注:str.contains是不能用匿名函数对一列值进行判断的,同等用法可以用in或者其他判断符)
df['授信机构'].apply(lambda x: "行内客户" if x.str.contains("建设银行|建信|建行") else "行外客户")
运行报错:
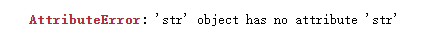
csdn上的经验是说这不是series,可df[‘授信机构’]属于series呀,然后用def+apply再写一次:
def mark(tmp):
if tmp['授信机构'].str.contains('建设银行|建行|建信'):
return '行内客户'
else:
return "行外客户"
tmp.apply(mark,axis=1)
继续报上面的错误。
再寻找解决方法的同时,先随便写写看看结果,这里以交行为例。
交行在长表里可能的字段有“交通银行、交行、交银”
- 多次拼接(笨方法)
test = tmp.loc[tmp['授信机构'].str.contains('交通银行')].append(tmp.loc[tmp['授信机构'].str.contains('交行')]).append(tmp.loc[tmp['授信机构'].str.contains('交银')])
- 管道符一步到位
test = tmp.loc[tmp['授信机构'].str.contains('交通银行|交行|交银')]
然后想到之前在np中偶尔会用的where方法:
测试一下:
tmp['mark']= np.where(tmp['授信机构'].str.contains('交通银行|交行|交银'), '行内客户', '行外客户')
根据结果看,正是我需要的。
在6w多条筛选出带我所需要的的字段的2500多条,导出即可。
补充:上面的def+apply的方法,如果是数值型或者逻辑运算符上使用时,是可以的。
留个小尾巴,现在仅仅区分一家行,但实际上国有大行在汇总表都是需要清洗的。比如
工行:工商银行、工行、工银
农行:农业银行、农行、农银国际
所以现在需要一个规则,将六大行+招商华夏浦发等等包进去。这里可以用字典传值进行判断


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









