# 索引是如何加速查询的,它的原理是啥?
索引模型/结构从二叉树-》平衡二叉树-》b树最后到b+树,每种树到底有什么问题最终演变成到了b+树
=================================================================================
# 0、创建索引的两个步骤
create index xxx on user(id);
1、提取索引字段的值当作key,value就是对应的本行记录
10 -------------> 10 zs
7 --------------> 7 ls
2、以key的为基础比较大小,生成树型结构
leaf node:叶子节点
non-leaf node:根节点、树枝节点
# 1、索引到底是一种什么样的数据结构:B+树
二叉树、平衡二叉树、B树=》B+树
#二叉树:
左节点的key值小于当前节点的key,而右节点的key大于当前节点,但是不能提速 -- #三次查找
create index idx_id on use(id);
select * from user where id =100;
# 平衡二叉树:
左子树与右子树的高度差不超过1
# 一次iO就读一次节点,就相当于一辆卡车,只拉一个快递(一个节点只读一个一页到内存)
每个节点只放了一条数据,相当于innodb存储引擎共16k的数据只放了一条数据,几个字节,浪费了许多
# B树:
一次io读入内存是一页数据,或者叫一个磁盘块的数据,磁盘块里包含了n个节点
ps:根节点页常驻内存 -- #两次查找
问题:页中的节点既存放key又存放对应记录值(values --》对应的是一行的完整记录)
# B+树:
1、非叶子节点只放key(根、树枝节点放key),只有叶子节点才放key:value --》非叶子节点能存放的key个数变多,衍生出指针越多,树会变得更矮更胖
2、叶子节点也指针指向,是有序排列的,这意味着B+树在排序操作上有天然的优势(范围查询速度快)# (因为提前排好了,再次查找的时候不需要从头再找)--》叶子节点是双向连接的
select * from user where id > 18;
先找到id=19所在的叶子节点,然后只需要根据叶子节点的链表指向向右查找下一个节点(id =19、id=20...)即不需要在回根节点查找
3、叶子节点内的key值是单向链表,叶子节点和叶子节点之间是双向链表。即全都排好序了 --》排序会很快
4、一个页、一个磁盘块、一个节点固定大小16k,可以存放的数据量就很多
安装每个节点存放1000数据来算,三层的B+树可以组织多少条数据1000 *1000 * 1000
# 特点:
1、B树只擅长等值查询
2、B+树擅长等值查询、范围查询
create index idx_id on user(id);
select * from user where id = 28;
select * from user where id > 18 and id < 28;
# id=19
# 总结:
只要叶子节点才是存放的数据是真实的,其他数据都是虚拟数据的
树的层级越高,所经历的步骤就越多(树越高,查询的层级就越多)
树越低越好,查询速度越快
# 如果存1000个数据,那么三层B+树可以存放上10亿条数据 --------》 树的高度是几,那个n就是几 n的三次方
# 1.普通索引index :加速查找
create table t2(
id int ,
class_name varchar(10) unique,
name varchar(16),
age int
);
create index xxx on t1(name); # 增加索引
drop index xxx on t1; #删除索引
# 2.主键索引:primary key :加速查找+约束(不为空且唯一)
create table t1(
id int primary key auto_increment,
class_name varchar(10),
name varchar(16),
age int
);
alter table student add primary key t1(id); # 增加索引
alter table student drop primary key; #删除索引
# 3、唯一索引:unique:加速查找+约束 (唯一)
alter table country add unique key t1(class_name); # 增加索引
alter table t1 drop index t1; #删除索引
# 4、全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。
# 5、空间索引spatial :了解就好,几乎不用
# 1、innodb存储引擎索引分类:
1、hash索引:更适合等值查询,不适合范围查询 # innodb存储引擎不支持hash索引
2、B+树索引:等值查询与范围查询都快
3、全文索引:只可以用在MyISAM引擎
# 2、(主键索引)、聚集索引、聚簇索引:
以主键字段的值作为key创建的索引(B+树)
一张表中有且只有一个,通常应该是id字段,该B+树的叶子节点放的是主键值和本行完整的记录
即: 表中的数据都聚集在叶子节点,所以称为聚集索引
select * from user where id=2;
# 3、(非聚集索引)、(非聚簇索引)、(二级索引)辅助索引:
非聚集索引,非聚簇索引,辅助索引、二级索引:以非主键字段值为key构建的B+树,该B+树的叶子节点存放的是key与其对应的主键字段值
create index yyy on user(name);
select * from user where name="xxx";
ps:一张innodb存储引擎表中必须要有且只能由一个聚集索引,但是可以多个辅助索引
针对非主键字段创建的索引(一张表中可以有多个)
# 4、聚集索引与辅助索引的异同
相同点:
都是B+树结构,意味着非叶子节点只放key
而叶子节点放key:value
不同之处
聚集索引叶子节点key对应的那个value值是一整行完整的记录
辅助索引叶子节点key对应的那个value值是其所对应的主键字段值
# 优化:
尽量避免回表操作,主键索引最后在前面,辅助索引在右面
# 5、覆盖索引和回表操作
覆盖索引:在当前你命中的索引结构中就能能到你想要的所有数据,称之为覆盖了索引
主键索引-》id字段
辅助索引-》name字段
select * from t3 where id = 3; -- 覆盖了索引
select name,id from t3 where name="egon"; -- 覆盖了索引
回表操作/查询:在当前你命中的索引结构中不能拿到你想要的所有数据,那么需要根据其对应的主建字段去聚集索引里重新查一遍,直到拿到完整记录,称之为回表操作
主键索引-》id字段
辅助索引-》name字段
select name,id,age from t3 where name="egon";
# 6、联合索引->最左前缀匹配原则
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引
create index idx_xxx on s1(name,age,gender);
查询条件中出现:name、age
查询条件中出现:name、gender
查询条件中出现:name、age、gender
where age = 18 and name = "egon" and gender="male"
10,11,12
10,13,0
==================================================================================
# 7、数据库索引
1、对区分度高并且占用空间小的字段建立索引
2、针对范围查询命中了索引,如果范围很大,查询效率依然很低,如何解决
要么把范围缩小
要么就分段/分页取值,一段一段取最终把大范围给取完
缓存
3、索引下推技术(默认开启)# 就是好多种方案选择最优的那种查找出来的
4、不要把查询字段放到函数或者参与运算
select count(*) from where id*12 = 3;
select count(*) from where id = 3/12;
5、索引覆盖
在命中索引的前提下,select查找值存在于本索引树中
create index idx_name on s1(name);
select name,id from s1 where name="egon"; -- 覆盖了索引
select name,id,age from s1 where name="egon"; -- 没有覆盖索引,需要回表操作
注意:如果查询条件是用的主键字段,那么无法select查什么都会覆盖索引,都不需要回表
所以说,在查询语句中,能用主键字段作为查询依据就尽量用它
举个例子来说,比如你在为某商场做一个会员卡的系统。
这个系统有一个会员表
有下列字段:
会员编号 INT
会员姓名 VARCHAR(10)
会员身份证号码 VARCHAR(18)
会员电话 VARCHAR(11)
会员住址 VARCHAR(50)
会员备注信息 TEXT
那么这个 会员编号,作为主键,使用 PRIMARY
会员姓名 如果要建索引的话,那么就是普通的 INDEX
会员身份证号码 如果要建索引的话,那么可以选择 UNIQUE (唯一的,不允许重复)
#除此之外还有全文索引,即FULLTEXT
会员备注信息 , 如果需要建索引的话,可以选择全文搜索。
用于搜索很长一篇文章的时候,效果最好。
用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
但其实对于全文搜索,我们并不会使用MySQL自带的该索引,而是会选择第三方软件如Sphinx,专门来做全文搜索。
#其他的如空间索引SPATIAL,了解即可,几乎不用
四、创建/删除索引语法
方法一:创建表时:
create table 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[ unique | fulltext | spatial ] index | key
[索引名] (字段名[(长度)] [ASC |DESC])
);
方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
···善用帮助文档···
help create
help create index
·················
1、案例
# 1、为user表的id字段创建索引,会以每条记录的id字段值为基础生成索引结构
create index 索引名 on user(id);
使用索引
select * from user where id = xxx;
# 2、为user表的name字段创建索引,会以每条记录的name字段值为基础生成索引结构
create index 索引名 on user(id);
使用索引
select * from user where name = xxx;
==================================================================================
1.创建索引
-在创建表时就创建(需要注意的几点)
create table s1(
id int ,#可以在这加primary key
#id int index #不可以这样加索引,因为index只是索引,没有约束一说,
#不能像主键,还有唯一约束一样,在定义字段的时候加索引
name char(20),
age int,
email varchar(30),
#primary key(id) #也可以在这加
index(id) #可以这样加
);
-在创建表后在创建
create index name on s1(name); # 添加普通索引
create unique age on s1(age); # 添加唯一索引
alter table s1 add primary key(id); # 添加住建索引,也就是给id字段增加一个主键约束
create index name on s1(id,name); # 添加普通联合索引
2.删除索引
drop index id on s1;
drop index name on s1; #删除普通索引
alter table t2 drop index t2;#删除唯一索引,就和普通索引一样,不用在index前加unique来删,直接就可以删了
alter table s1 drop primary key; #删除主键(因为它添加的时候是按照alter来增加的,那么我们也用alter来删)
3.查看索引
show index from s1;
五、索引测试
1、准备测试数据
#1. 准备表
create table t1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. 创建存储过程,实现批量插入记录
delimiter $$ #声明存储过程的结束符号为$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do #300w数据
insert into t1 values(i,'mm','male',concat('mm',i,'@boy'));
set i=i+1;
end while;
END$$ #$$结束
delimiter ; #重新声明分号为结束符号
#3. 查看存储过程
show create procedure auto_insert1\G
#4. 调用存储过程
call auto_insert1(); # 过程会很慢,一分钟后可强制结束,也已将创建了一些
2、未创建索引前的查询速度缓慢
#无索引:从头到尾扫描一遍,所以查询速度很慢
mysql> select * from s1 where id=333;
+------+---------+--------+----------------+
| id | name | gender | email |
+------+---------+--------+----------------+
| 333 | mm| male | cm333@oldboy |
+------+---------+--------+----------------+
1 row in set (1.33 sec)
mysql> explain select * from s1 where id=333;
mysql> select * from s1 where email='cm333@oldboy';
+------+---------+--------+----------------+
| id | name | gender | email |
+------+---------+--------+----------------+
| 333 | cm333 | male | cm333@oldboy |
+------+---------+--------+----------------+
1 row in set (1.50 sec)
3、加上索引后查询速度极快
1. 一定是为搜索条件的字段创建索引,比如select * from s1 where id > 5;就需要为id加上索引
2. 在表中已经有大量数据的情况下,建索引会很慢,且占用硬盘空间,插入删除更新都很慢,只有查询快
比如create index idx on s1(id);会扫描表中所有的数据,然后以id为数据项,创建索引结构,存放于硬盘的表中。
建完以后,再查询就会很快了
mysql> create index idx on s1(id);
3. 需要注意的是:innodb表的索引会存放于s1.ibd文件中,而myisam表的索引则会有单独的索引文件table1.MYI
mysql> select * from s1 where id=333;
+------+---------+--------+----------------+
| id | name | gender | email |
+------+---------+--------+----------------+
| 333 | cm333 | male | cm333@oldboy |
+------+---------+--------+----------------+
1 row in set (0.01 sec)
# 建立完索引,那个数据的ibd文件是变大了,但是如果删除完索引,但是那个ibd文件却不会变小,这是一个bug
# 因为ibd里面的数据和索引里面的内容都放在ibd文件里了
六、 正确使用索引
1、索引命中也未必会加速
并不是说我们创建了索引就一定会加快查询速度,若想利用索引达到预想的提高查询速度的效果,我们在添加索引时,必须遵循以下问题
# 1、如何正确使用索引
1、以什么字段的值为基础构建索引
2、最好是不为空、唯一、占用空间小的字段
# 2、针对全表查询语句如何优化?
应用场景:用户想要浏览所有的商品信息
select count(id) from s1;
如何优化:
开发层面分页查找,用户每次看现从数据中拿
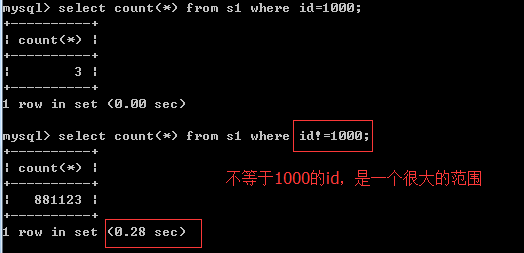
# 3、针对等值查询
以重复度低字段为基础创建索引加速效果明显
create index xxx on s1(id);
select count(id) from s1 where id = 33;
以重复度高字段为基础创建索引加速效果明显
create index yyy on s1(name);
select count(id) from s1 where name="egon"; -- 速度极慢
select count(id) from s1 where name!="egon"; -- 速度快
select count(id) from s1 where name="mm"; -- 速度快
以占用空间大字段为基础创建索引加速效果不明显
# 总结:给重复低、且占用空间小的字段值为基础构建索引
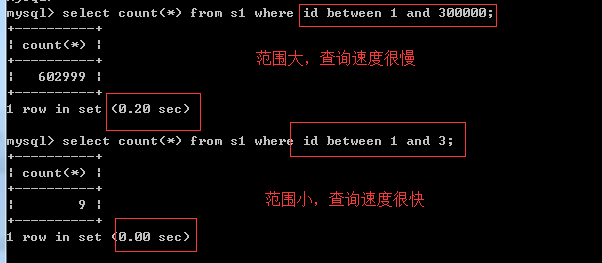
# 4、关于范围查询
select count(id) from s1 where id=33;
select count(id) from s1 where id>33;
select count(id) from s1 where id>33 and id < 36;
select count(id) from s1 where id>33 and id < 1000000;
# 总结:innodb存储能加速范围查询,但是查询范围不能特别大
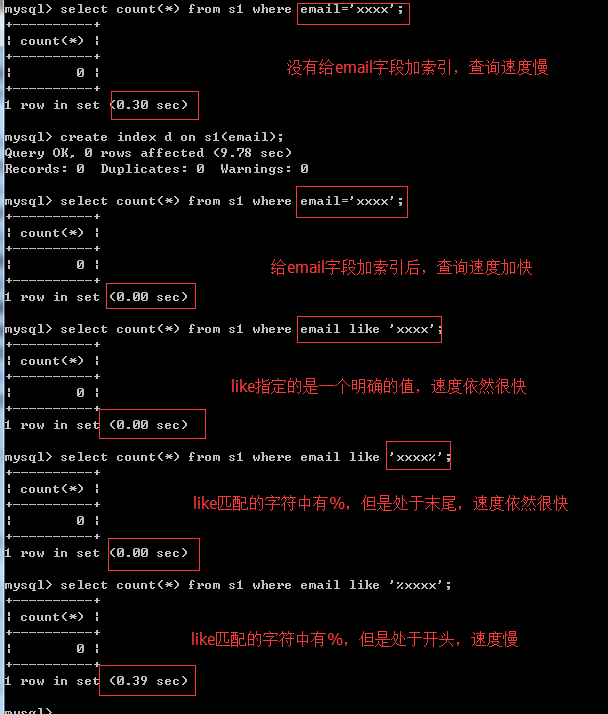
5、关于条件字段参与运算
select count(id) from s1 where id*12 = 10000;
select count(id) from s1 where id = 10000/12;
select count(id) from s1 where func(id) = 10000/12;
# 总结:不要让条件字段参与运算,或者说传递给函数








![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mh1hkYOe-1626167281861)(C:\Users\17155\Desktop\mysql img\1625390482403.png)]](https://img-blog.csdnimg.cn/20210713170902415.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21tOTcwOTE5,size_16,color_FFFFFF,t_70)
![img\67f52690982bf9e85b09c6763733a415.gif)]](https://img-blog.csdnimg.cn/20210713171008863.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21tOTcwOTE5,size_16,color_FFFFFF,t_70)
















 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











