







单表查询
# https://www.cnblogs.com/linhaifeng/articles/7267592.html -- #提前准备好表
#简单查询
SELECT * FROM employee;
SELECT name,salary FROM employee;
#避免重复DISTINCT
SELECT DISTINCT post FROM employee;
# as 后面跟新的名字
mysql> select id,concat(cmd,'_vip') as new from cmd;
+----+---------------------+
| id | new |
+----+---------------------+
| 1 | ls -l /etc_vip |
| 2 | cat /etc/passwd_vip |
| 3 | useradd xxx_vip |
| 4 | ps aux_vip |
+----+---------------------+
4 rows in set (0.00 sec)
# concat拼接查询
mysql> select * from cmd;
+----+------+------+-----------------+---------------------+---------+
| id | USER | priv | cmd | sub_time | success |
+----+------+------+-----------------+---------------------+---------+
| 1 | egon | 0755 | ls -l /etc | 2021-07-04 10:02:08 | yes |
| 2 | egon | 0755 | cat /etc/passwd | 2021-07-04 10:02:08 | no |
| 3 | egon | 0755 | useradd xxx | 2021-07-04 10:02:08 | no |
| 4 | egon | 0755 | ps aux | 2021-07-04 10:02:08 | yes |
+----+------+------+-----------------+---------------------+---------+
4 rows in set (0.00 sec)
mysql> select id,concat(cmd,'_vip') from cmd;
+----+---------------------+
| id | concat(cmd,'_vip') |
+----+---------------------+
| 1 | ls -l /etc_vip |
| 2 | cat /etc/passwd_vip |
| 3 | useradd xxx_vip |
| 4 | ps aux_vip |
+----+---------------------+
4 rows in set (0.00 sec)
一、重要关键字的执行顺序
# 书写顺序
select id,name from emp where id > 3;
# 执行顺序
from
where
select
虽然执行顺序和书写顺序不一致,按照书写顺序的方式写sql
select * 先用*号占位
之后去补全后面的sql语句
最后将*号替换后你想要的具体字段
select distinct 字段1,字段2 ... from
where 过滤条件 ---- group by 分组字段 ------having 过滤条件
--------order by 排序字段 ---------- limit 条数
1、where筛选条件
# 作用:是对整体数据的一个筛选操作
# 1,查询id大于等于3小于等于6的数据
select id,name,age from emp where id >= 3 and id <=6;
select id,name,from emp where id between 3 and 6; 两者等价
# 2,查询薪资是2万或者1万8或者1万7的数据
select * from emp where salary=20000 or salary=18000 or salary=17000;
select * from emp where salary in(20000,18000,17000);
# 3,查询员工姓名中包含字母o的员工的姓名和薪资
模糊查询
like --% 匹配任意多个字符 _ 匹配任意单个字符
select name,salary from emp where name like '%0%';
# 4,查询员工姓名是由4个字符组成的 姓名和薪资char_length()
select name,salary from emp where name like '____';
select name,salary from emp where char_length(name)=4;
# 5,查询id小于3或者id大于6的数据
select * from emp where id not between 3 and 6;
# 6,查询薪资不在2万,1万8,1万7范围的数据
select * from emp where salary not in (20000,18000,17000);
# 7,查询岗位描述为空的员工姓名和岗位名 针对null不用等号 用is
select name,post from emp where post_comment = NULL; 错
select name,post from emp where post_comment is NULL;
2、group by分组
# 分组实际应用场景 分组应用场景非常多
男女比例、部门平均薪资、国家之间数据统计
# 1,按照部门分组
select * from emp group by post;
分组之后,最小可操作单位应该是组,还不再是组内的单个数据
上述命令在你没有设置严格模式的时候是可正常执行的,返回的是分组之后,每个组的第一条数据,但是这不符合分组的规范;分组之后不应该考虑单个数据,而应该以组为操作单位(分组之后,没办法直接获取组内单个数据)
如果设置了严格模式,那么上述命令会直接报错
set global sel_mode = 'strict_trans_tables,only_full_group_by';
设置了严格模式之后 ,分组,默认只能拿到分组的数据
select post from emp group by post;
按照什么分组就只能拿到分组,其他字段不能直接获取,需要借助于一些方法
什么时候需要分组? 看关键字——每个、平均、最高、最低
聚合函数:max,min,sum,count,avg ,用来帮助分组的操作
# 1,获取每个部门的最高薪资
select post,max(salary) from emp group by post;
select post as '部门',max(salary) as '最高薪资' from emp group by post; # as是起别名
select post '部门',max(salary) '最高薪资' from emp group by post;
# as 可以给字段起别名,也可以直接省略不写,但是不推荐。造成语义不明确,容易错乱
as 语法不单单可以给字段起别名,还可以给表 临时 起别名
select emp.id,emp.name from emp;
select emp.id,emp.name from emp as t1; 报错
select t1.id,t1.name from emp as t1;
# 2,获取每个部门的最低薪资
select post,min(salary)from emp group by post;
# 3,获取每个部门的平均薪资
select post,avg(salary)from emp group by post;
# 4,获取每个部门的工资总和
select post,sum(salary)from emp group by post;
# 5,获取每个部门的人数
select post,count(salary)from emp group by post;# 常用,符合逻辑
select post,count(id)from emp group by post;
select post,count(age)from emp group by post;
select post,count(post_comment)from emp group by post; #不能用null
# 6,查询分组之后的部门名称和每个部门下所有的员工姓名
# group_concat 不单单可以支持你获取分组之后的其他字段,还支持拼接操作
select post,group_concat(name) from emp group by post;
select post,group_concat(name,'_dsb') from emp group by post; # 拼接'_dsb'
select post,group_concat(name,':',salary) from emp group by post; #拼接
# concat不分组的时候用,拼接
select concant('NAME:'name),concat('SAL:',salary) from emp;
# 7,查询每个人的年薪,12薪
select name,salary *12 from emp;
#补充 as语法不单单可以给字段起别名 还可以给表临时起别名
select emp.id,emp.name from emp;
select t1.id,t1.name from emp as t1; #别名
# 8、查询每个不忙20岁以上的人平均薪资
mysql> select sex,count(id) from emp where age>20 group by sex;
============================================================================
# 9、聚合函数
#强调:聚合聚合的是组的内容,若是没有分组,则默认一组
# avg min max count
示例:
SELECT COUNT(*) FROM employee;
SELECT COUNT(*) FROM employee WHERE depart_id=1;
SELECT MAX(salary) FROM employee;
SELECT MIN(salary) FROM employee;
SELECT AVG(salary) FROM employee;
SELECT SUM(salary) FROM employee;
SELECT SUM(salary) FROM employee WHERE depart_id=3;
3、分组注意事项
# 关键字where和group by 同时出现的时候,group by 必须在where的后面。
where先对整体数据进行过滤之后再分组操作
聚合函数只能在分组之后使用,where筛选条件不能使用聚合函数
select id,name,age from emp where max(salary) > 3000; # 报错,非法使用聚合函数
select max(salary) from emp; # 不分组,默认整体就是一组
# 统计各部门年龄在30岁以上的员工平均薪资
1,先求所有年龄大于30岁的员工
select * from emp where age > 30;
2,再对结果进行分组
select * from emp where age > 30 group by post;
select post,avg(salary) from emp where age >30 group by post;
4、having分组之后的筛选条件
having的语法和where是一致的,只不过having是在分组之后进行的过滤操作,即having是可以直接使用聚合函数的
# 统计各部门年龄在30岁以上的员工平均工资并保留平均薪资大于1万的部门
select post,avg(salary) from emp
where age>30
group by post
having avg(salary)>10000;
5、distinct去重
一定要注意,必须是完全一样的数据才可以去重!!!
一定不要将主键忽视了,有主键存在的情况下,是不可能去重的
[
{'id':1,'name':'jason','age':18},
{'id':2,'name':'jason','age':18},
{'id':3,'name':'egon','age':18},
]
ORM 对象关系映射,让不懂sql语句的人也会操作数据库
表 类
一条条的数据 对象
字段对应的值 对象的属性
select distinct id,age from emp; # 无法去重
select diftinct age from emp; 可以
6、order by 排序
select * from emp order by salary; 等价于 : select * from emp order by salary asc;
order by 默认是升序 asc 该asc可以省略不写
也可以修改为降序 desc
select * from emp order by salary desc;
mysql> select * from emp order by age asc,id desc;
# 先按照age降序排,如果碰到age相同 则再按照salary升序排
# 统计各部门年龄在10岁以上的员工平均工资并保留平均薪资大于1千的部门,然后对平均工资降序排序
select post,avg(salary) from emp
where age>10
group by post
having avg(salary)>1000
order by avg(salary) desc;
7、limit 限制展示条数
select * from emp;
针对数据过多的情况,我们通常都是做分页处理
select * from emp limit 3; # 只展示3条数据
select * from emp limit 0,5;
select * from emp limit 5,5;
8、正则 regexp
select * from emp where name regexp '^j.*(n/y)$';
mysql> SELECT * FROM emp WHERE name REGEXP 'on$'; #正则必须要有regexp
二、多表操作
1、前期表准备
# 建表
create table dep(
id int,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int);
# 插入数据
mysql> insert dep values(200,'技术'),(201,'人力资源'),(202,'销售'),(203,'运营');
insert emp(name,sex,age,dep_id) values
('jason','male',18,200),
('egon','female',28,201),
('kevin','male',38,201),
('nick','male',48,202),
('oven','male',18,203),
('jerry','female',18,204);
2、表查询
select * from dep,emp; # 结果是笛卡尔积
select * from emp,dep where emp.dep_id = dep.id; # 不建议用
mysql也知道,你在后面查询数据过程中,肯定会经常用到拼表操作,所以特地开设了对应的方法
inner join 内连接
left join 左连接
right join 右连接
union 全连接
# inner join # 只拼接2张表中共有的数据部分 (常用)
select * from emp inner join dep on emp.dep_id = dep.id;
# left join # 左表所有的数据都展示出来,没有对应的项就用NULL
select * from emp left join dep on emp.dep_id = dep.id;
# right join # 右表所有的数据都展示出来,没有对应的项就用NULL
select * from emp right join dep on emp.dep_id = dep.id;
# union # 左右2表所有的数据都展示出来 (不常用)
select * from emp left join dep on emp.dep_id = dep.id
union
select * from emp right join dep on emp.dep_id = dep.id;
3、子查询
子查询就是我们平时解决问题的思路
分步骤解决问题 第一步 第二步...
将一个查询语句的结果当做另外一个查询语句的条件去用
# 查询部门是技术或者人力资源的员工信息
1,先获取部门的id号
2,再去员工表里面筛选出对应的员工
select id from dep where name = '技术' or name = '人力资源';
select name from emp where dep_id in (200,201);
-- select * from emp where dep_id in (select id from dep where name = '技术' or name = '人力资源');
4、知识点补充
# 查询平均年龄在25岁以上的部门名称
----只要是多表查询,就有2种思路,联表,子查询----
# 联表操作
1,先拿到部门和员工表,拼接之后的结果
2,分析语义,得出需要进行分组
select dep.name from emp inner join dep
on emp.dep_id = dep.id
group by dep.name
having avg(age) > 25;
--涉及到多表操作的时候,一定要加上表的前缀--
# 子查询
select name from dep where id in
(select dep_id from emp group by dep_id
having avg(age) > 25);
# 关键字exists(了解)
只返回布尔值 True False
返回True 的时候外层查询语句执行
返回False的时候外层查询语句不再执行
select * from emp where exists
(select id from dep where id>3);
select * from emp where exists
(select id from dep where id>300);
5、总结
表的查询结果可以作为其他表的查询条件
也可以通过起别名的方式把它作为一张虚拟表跟其他表关联
多表查询就2种方式
先拼接表再查询
子查询一步一步来
Powered by .NET 5.0 on Kubernetes
# 查询平均年龄在25岁以上的部门名称
# 连表查询
mysql> select dep.name from emp inner join dep on emp.dep_id=dep.id group by dep.name having avg(age) >25;
# 子查询
mysql> select name from dep where id in (select dep_id from emp group by dep_id having avg(age) >25);
# 关键字exists(了解)
正确才返回ture,反之false
三、mysql数据库多表查询
1、多表查询分类
1》多表连接查询
2》复合条件连接查询
3》子查询
2、多表查询准备
#建表
create table department(
id int,
name varchar(20)
);
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#插入数据
insert into department values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营');
insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204)
;
#查看表结构和数据
mysql> desc department;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
mysql> desc employee;
+--------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | YES | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(11) | YES | | NULL | |
| dep_id | int(11) | YES | | NULL | |
+--------+-----------------------+------+-----+---------+----------------+
mysql> select * from department;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
mysql> select * from employee;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
#表department与employee
3、多表连接查询
##!!!!重点:外链接语法
SELECT 字段列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.字段 = 表2.字段;
12345
1、 交叉连接( 笛卡尔积查询 )
不适用任何匹配条件,生成笛卡尔积
1)笛卡尔积查询介绍
#select * from 表一,表二
上面这个语句的执行是想查出来两张表中所有的数据,但是发现执行结果多出来好多数据,当联表查询的时候,mysql不知道如何连接两孩子那个表的
2)笛卡尔积查询使用
select * from emp,dep; #将两张表拼在一起
select * from emp,dep where dep.id = emp.dep_id; #找到两张表中对应的关系记录
select emp.name from dep,emp where dep.id = emp.dep_id and dep.name='技术'; #拿到筛选后的技术部门数据中emp.name的数据
2、内连接(inner join on)只连接匹配的行
1)inner join on介绍
在写sql语句的时候,让我们对语句有一个清晰的区分,增强代码的可读性,联表的操作和查询的操作有个明确的区分,就用到了内连接,左链接,右链接的方式inner join on就是内连接的意思,内连接的方式就一个弊端就是,当两个表的数据中无法通过联表指定的字段对应上的时候,就无法显示这些数据,类似集合中交集的意思
2)inner join on的使用
在写sql语句的时候,让我们对语句有一个清晰的区分,增强代码的可读性,联表的操作和查询的操作有个明确的区分,就用到了内连接,左链接,右链接的方式inner join on就是内连接的意思,内连接的方式就一个弊端就是,当两个表的数据中无法通过联表指定的字段对应上的时候,就无法显示这些数据,类似集合中交集的意思
#找两张表共有的部分,相当于利用条件从笛卡尔积结果中筛选出了正确的结果
#department没有204这个部门,因而employee表中关于204这条员工信息没有匹配出来
mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee inner join department on employee.dep_id=department.id;
+----+-----------+------+--------+--------------+
| id | name | age | sex | name |
+----+-----------+------+--------+--------------+
| 1 | egon | 18 | male | 技术 |
| 2 | alex | 48 | female | 人力资源 |
| 3 | wupeiqi | 38 | male | 人力资源 |
| 4 | yuanhao | 28 | female | 销售 |
| 5 | liwenzhou | 18 | male | 技术 |
+----+-----------+------+--------+--------------+
#上述sql等同于
mysql> select employee.id,employee.name,employee.age,employee.sex,department.name from employee,department where employee.dep_id=department.id;
3、外连接(左连接 left join on )
优先显示左表全部记录
1)left join on 介绍
左连接的意思就是在内连接的基础上增加左边有,右边没有的数据,将左边的表作为主表,右边的表作为辅表,当辅表的数据没办法对应上左表的数据时,就通过null来表示(把左表的所有数据都显示)
2)left join on的使用
#实列:
select * from dep left join emp on dep.id=emp.dep_id;
#以左表为准,即找出所有员工信息,当然包括没有部门的员工
#本质就是:在内连接的基础上增加左边有右边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id;
+----+------------+--------------+
| id | name | depart_name |
+----+------------+--------------+
| 1 | egon | 技术 |
| 5 | liwenzhou | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 6 | jingliyang | NULL |
+----+------------+--------------+
4、外连接(右连接 right join on )
优先显示右表全部记录
1)right join on介绍
右连接于左连接的用法使一样的,不过右连接是将右表作为主表,左表作为辅表
2)right join on的使用
#实列:
select * from dep right join emp on dep.id=emp.dep_id;
#以右表为准,即找出所有部门信息,包括没有员工的部门
#本质就是:在内连接的基础上增加右边有左边没有的结果
mysql> select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id;
+------+-----------+--------------+
| id | name | depart_name |
+------+-----------+--------------+
| 1 | egon | 技术 |
| 2 | alex | 人力资源 |
| 3 | wupeiqi | 人力资源 |
| 4 | yuanhao | 销售 |
| 5 | liwenzhou | 技术 |
| NULL | NULL | 运营 |
+------+-----------+--------------+
5、全外连接( union )
显示左右两个表全部记录
1)union介绍
> 不管是内连接还是左连接,右连接,都会由一些数据使无法显示出来的,那么就可以用全连接的方式来链接,写法是写一个左连接,一个右链接,中间用union 来连接
2)union的使用
#实列:
select * from dep left join emp on dep.id=emp.dep_id union select * from dep right join emp on dep.id=emp.dep_id;
#全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果
#注意:mysql不支持全外连接 full JOIN
#强调:mysql可以使用此种方式间接实现全外连接
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;
#查看结果
+------+------------+--------+------+--------+------+--------------+
| id | name | sex | age | dep_id | id | name |
+------+------------+--------+------+--------+------+--------------+
| 1 | egon | male | 18 | 200 | 200 | 技术 |
| 5 | liwenzhou | male | 18 | 200 | 200 | 技术 |
| 2 | alex | female | 48 | 201 | 201 | 人力资源 |
| 3 | wupeiqi | male | 38 | 201 | 201 | 人力资源 |
| 4 | yuanhao | female | 28 | 202 | 202 | 销售 |
| 6 | jingliyang | female | 18 | 204 | NULL | NULL |
| NULL | NULL | NULL | NULL | NULL | 203 | 运营 |
+------+------------+--------+------+--------+------+--------------+
#注意 union与union all的区别:union会去掉相同的纪录
四、符合条件连接查询
#示例1:以内连接的方式查询employee和department表,并且employee表中的age字段值必须大于25,即找出年龄大于25岁的员工以及员工所在的部门
select employee.name,department.name from employee inner join department
on employee.dep_id = department.id
where age > 25;
#示例2:以内连接的方式查询employee和department表,并且以age字段的升序方式显示
select employee.id,employee.name,employee.age,department.name from employee,department
where employee.dep_id = department.id
and age > 25
order by age asc;
五、子查询
子查询是将一个查询的结果作为另一个查询的条件
1》#子查询是将一个查询语句嵌套在另一个查询语句中
2》#内层查询语句的查询结果,可以为外层查询语句提供查询条件。
3》#子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
4》#还可以包含比较运算符:= 、 !=、> 、<等
#实列:
#方式一
select name from emp where dep_id = (select id from dep where name = '技术');
#方式二
select emp.name from emp inner join dep on dep.id=emp.dep_id where dep.name='技术';
1、带in关键字的子查询
#查询平均年龄在25岁以上的部门名
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
#查看技术部员工姓名
select name from employee
where dep_id in
(select id from department where name='技术');
#查看不足1人的部门名(子查询得到的是有人的部门id)
select name from department where id not in (select distinct dep_id from employee);
##!!!!!!注意not in
not in 无法处理null的值,即子查询中如果存在null的值,not in将无法处理,如下
mysql> select * from emp;
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
| 7 | xxx | male | 19 | NULL |
+----+------------+--------+------+--------+
7 rows in set (0.00 sec)
mysql> select * from dep;
+------+--------------+
| id | name |
+------+--------------+
| 200 | 技术 |
| 201 | 人力资源 |
| 202 | 销售 |
| 203 | 运营 |
+------+--------------+
4 rows in set (0.00 sec)
# 子查询中存在null
mysql> select * from dep where id not in (select distinct dep_id from emp);
Empty set (0.00 sec)
# 解决方案如下
mysql> select * from dep where id not in (select distinct dep_id from emp where dep_id is not null);
+------+--------+
| id | name |
+------+--------+
| 203 | 运营 |
+------+--------+
1 row in set (0.00 sec)
mysql>
2、带any关键字的子查询
#在 SQL 中 ANY 和 SOME 是同义词,SOME 的用法和功能和 ANY 一模一样。
#ANY 和 IN 运算符不同之处一
ANY 必须和其他的比较运算符共同使用,而且ANY必须将比较运算符放在 ANY 关键字之前,所比较的值需要匹配子查询中的任意一个值,这也就是 ANY 在英文中所表示的意义
例如:#使用 IN 和使用 ANY运算符得到的结果是一致的
select * from employee where salary = any (
select max(salary) from employee group by depart_id);
select * from employee where salary in (
select max(salary) from employee group by depart_id);
结论:也就是说“=ANY”等价于 IN 运算符,而“<>ANY”则等价于 NOT IN 运算符
#ANY和 IN 运算符不同之处二
ANY 运算符不能与固定的集合相匹配,比如下面的 SQL 语句是错误的
SELECT
*
FROM
T_Book
WHERE
FYearPublished < ANY (2001, 2003, 2005)
3、带all关键字的子查询
#all同any类似,只不过all表示的是所有,any表示任一
1>#查询出那些薪资比所有部门的平均薪资都高的员工=》薪资在所有部门平均线以上的狗币资本家
select * from employee where salary > all (
select avg(salary) from employee group by depart_id);
2>#查询出那些薪资比所有部门的平均薪资都低的员工=》薪资在所有部门平均线以下的无产阶级劳苦大众
select * from employee where salary < all (
select avg(salary) from employee group by depart_id);
3>#查询出那些薪资比任意一个部门的平均薪资低的员工=》薪资在任一部门平均线以下的员工select * from employee where salary < any ( select avg(salary) from employee group by depart_id);
4>#查询出那些薪资比任意一个部门的平均薪资高的员工=》薪资在任一部门平均线以上的员工
select * from employee where salary > any (
select avg(salary) from employee group by depart_id);
4、带比较运算符的子查询
#比较运算符:=、!=、>、>=、<、<=、<>
#查询大于所有人平均年龄的员工名与年龄
mysql> select name,age from emp where age > (select avg(age) from emp);
+---------+------+
| name | age |
+---------+------+
| alex | 48 |
| wupeiqi | 38 |
+---------+------+
2 rows in set (0.00 sec)
#查询大于部门内平均年龄的员工名、年龄
select t1.name,t1.age from emp t1
inner join
(select dep_id,avg(age) avg_age from emp group by dep_id) t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
5、带exists关键字的子查询
EXISTS关字键字表示存在
在使用EXISTS关键字时,内层查询语句不返回查询的记录
而是返回一个真假值 : True或False
当返回True时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询
#department表中存在dept_id=203,Ture
mysql> select * from employee
-> where exists
-> (select id from department where id=200);
+----+------------+--------+------+--------+
| id | name | sex | age | dep_id |
+----+------------+--------+------+--------+
| 1 | egon | male | 18 | 200 |
| 2 | alex | female | 48 | 201 |
| 3 | wupeiqi | male | 38 | 201 |
| 4 | yuanhao | female | 28 | 202 |
| 5 | liwenzhou | male | 18 | 200 |
| 6 | jingliyang | female | 18 | 204 |
+----+------------+--------+------+--------+
#department表中存在dept_id=205,False
mysql> select * from employee
-> where exists
-> (select id from department where id=204);
Empty set (0.00 sec)
1)in与exists
!!!!!!当in和exists在查询效率上比较时,in查询的效率快于exists的查询效率!!!!!!
==============================exists==============================
# exists
exists后面一般都是子查询,后面的子查询被称做相关子查询(即与主语句相关),当子查询返回行数时,exists条件返回true,
否则返回false,exists是不返回列表的值的,exists只在乎括号里的数据能不能查找出来,是否存在这样的记录。
# 例:
查询出那些班级里有学生的班级
select * from class where exists (select * from stu where stu.cid=class.id)
# exists的执行原理为:
1》依次执行外部查询:即select * from class
2》然后为外部查询返回的每一行分别执行一次子查询:即(select * from stu where stu.cid=class.cid)
3》子查询如果返回行,则exists条件成立,条件成立则输出外部查询取出的那条记录
==============================in==============================
# in
in后跟的都是子查询,in()后面的子查询 是返回结果集的
# 例
查询和所有女生年龄相同的男生
select * from stu where sex='男' and age in(select age from stu where sex='女')
# in的执行原理为:
in()的执行次序和exists()不一样,in()的子查询会先产生结果集,
然后主查询再去结果集里去找符合要求的字段列表去.符合要求的输出,反之则不输出.
2) not in与 not exists
!!!!!!not exists查询的效率远远高与not in查询的效率。!!!!!!
==========================not in============================
not in()子查询的执行顺序是:
为了证明not in成立,即找不到,需要一条一条地查询表,符合要求才返回子查询的结果集,不符合的就继续查询下一条记录,直到把表中的记录查询完,只能查询全部记录才能证明,并没有用到索引。
=========================not exists==============================
not exists:
如果主查询表中记录少,子查询表中记录多,并有索引
#例如:查询那些班级中没有学生的班级
select * from class
where not exists
(select * from student where student.cid = class.cid)
#not exists的执行顺序是:
在表中查询,是根据索引查询的,如果存在就返回true,如果不存在就返回false,不会每条记录都去查询
3)示例:
#数据准备:
#创建库
create database db13;
use db13
#建表
create table student(
id int primary key auto_increment,
name varchar(16)
);
create table course(
id int primary key auto_increment,
name varchar(16),
comment varchar(20)
);
create table student2course(
id int primary key auto_increment,
sid int,
cid int,
foreign key(sid) references student(id),
foreign key(cid) references course(id)
);
#往表插入数据
insert into student(name) values
("egon"),
("lili"),
("jack"),
("tom");
insert into course(name,comment) values
("数据库","数据仓库"),
("数学","根本学不会"),
("英语","鸟语花香");
insert into student2course(sid,cid) values
(1,1),
(1,2),
(1,3),
(2,1),
(2,2),
(3,2);
####################### 实列测试 #########################
1》#查询选修了所有课程的学生id、name:(即该学生根本就不存在一门他没有选的课程。)
select * from student s where not exists
(select * from course c where not exists
(select * from student2course sc where sc.sid=s.id and sc.cid=c.id));
select s.name from student as s
inner join student2course as sc
on s.id=sc.sid
group by s.name
having count(sc.id) = (select count(id) from course);
2》#查询没有选择所有课程的学生,即没有全选的学生。(存在这样的一个学生,他至少有一门课没有选)
select * from student s where exists
(select * from course c where not exists
(select * from student2course sc where sc.sid=s.id and sc.cid=c.id));
3》#查询一门课也没有选的学生。(不存这样的一个学生,他至少选修一门课程)
select * from student s where not exists
(select * from course c where exists
(select * from student2course sc where sc.sid=s.id and sc.cid=c.id));
4》#查询至少选修了一门课程的学生。
select * from student s where exists
(select * from course c where exists
(select * from student2course sc where sc.sid=s.id and sc.cid=c.id));
6、案列
查询每个部门最新入职的那位员工
############ 准备表和记录 #########
company.employee
员工id id int
姓名 emp_name varchar
性别 sex enum
年龄 age int
入职日期 hire_date date
岗位 post varchar
职位描述 post_comment varchar
薪水 salary double
办公室 office int
部门编号 depart_id int
#创建表
create table employee(
id int not null unique auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
#查看表结构
mysql> desc employee;
+--------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------------+-----------------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(20) | NO | | NULL | |
| sex | enum('male','female') | NO | | male | |
| age | int(3) unsigned | NO | | 28 | |
| hire_date | date | NO | | NULL | |
| post | varchar(50) | YES | | NULL | |
| post_comment | varchar(100) | YES | | NULL | |
| salary | double(15,2) | YES | | NULL | |
| office | int(11) | YES | | NULL | |
| depart_id | int(11) | YES | | NULL | |
+--------------+-----------------------+------+-----+---------+----------------+
#插入记录
#三个部门:教学,销售,运营
insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values
('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部
('alex','male',78,'20150302','teacher',1000000.31,401,1),
('wupeiqi','male',81,'20130305','teacher',8300,401,1),
('yuanhao','male',73,'20140701','teacher',3500,401,1),
('liwenzhou','male',28,'20121101','teacher',2100,401,1),
('jingliyang','female',18,'20110211','teacher',9000,401,1),
('jinxin','male',18,'19000301','teacher',30000,401,1),
('成龙','male',48,'20101111','teacher',10000,401,1),
('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('丫丫','female',38,'20101101','sale',2000.35,402,2),
('丁丁','female',18,'20110312','sale',1000.37,402,2),
('星星','female',18,'20160513','sale',3000.29,402,2),
('格格','female',28,'20170127','sale',4000.33,402,2),
('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3)
;
#ps:如果在windows系统中,插入中文字符,select的结果为空白,可以将所有字符编码统一设置成gbk
#方式一(链表)
SELECT
*
FROM
emp AS t1
INNER JOIN (
SELECT
post,
max(hire_date) max_date
FROM
emp
GROUP BY
post
) AS t2 ON t1.post = t2.post
WHERE
t1.hire_date = t2.max_date;
#方式二(子查询)
mysql> select (select t2.name from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) from emp as t1 group by post;
mysql> select (select t2.id from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) from emp as t1 group by post;
#正确答案
mysql> select t3.name,t3.post,t3.hire_date from emp as t3 where id in (select (select id from emp as t2 where t2.post=t1.post order by hire_date desc limit 1) from emp as t1 group by post);
+--------+-----------------------------------------+------------+
| name | post | hire_date |
+--------+-----------------------------------------+------------+
| egon | 老男孩驻沙河办事处外交大使 | 2017-03-01 |
| alex | teacher | 2015-03-02 |
| 格格 | sale | 2017-01-27 |
| 张野 | operation | 2016-03-11 |
+--------+-----------------------------------------+------------+
rows in set (0.00 sec)
#方式一为正确答案,方式二中的limit 1有问题(每个部门可能有>1个为同一时间入职的新员工),我只是想用该例子来说明可以在select后使用子查询
#可以基于上述方法解决:比如某网站在全国各个市都有站点,每个站点一条数据,想取每个省下最新的那一条市的网站质量信息
六、综合练习
#init.sql文件内容
/*
数据导入:
Navicat Premium Data Transfer
Source Server : localhost
Source Server Type : MySQL
Source Server Version : 50624
Source Host : localhost
Source Database : sqlexam
Target Server Type : MySQL
Target Server Version : 50624
File Encoding : utf-8
Date: 10/21/2016 06:46:46 AM
*/
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `class`
-- ----------------------------
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`caption` varchar(32) NOT NULL,
PRIMARY KEY (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `class`
-- ----------------------------
BEGIN;
INSERT INTO `class` VALUES ('1', '三年二班'), ('2', '三年三班'), ('3', '一年二班'), ('4', '二年九班');
COMMIT;
-- ----------------------------
-- Table structure for `course`
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`cid` int(11) NOT NULL AUTO_INCREMENT,
`cname` varchar(32) NOT NULL,
`teacher_id` int(11) NOT NULL,
PRIMARY KEY (`cid`),
KEY `fk_course_teacher` (`teacher_id`),
CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `course`
-- ----------------------------
BEGIN;
INSERT INTO `course` VALUES ('1', '生物', '1'), ('2', '物理', '2'), ('3', '体育', '3'), ('4', '美术', '2');
COMMIT;
-- ----------------------------
-- Table structure for `score`
-- ----------------------------
DROP TABLE IF EXISTS `score`;
CREATE TABLE `score` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`student_id` int(11) NOT NULL,
`course_id` int(11) NOT NULL,
`num` int(11) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_score_student` (`student_id`),
KEY `fk_score_course` (`course_id`),
CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`),
CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `score`
-- ----------------------------
BEGIN;
INSERT INTO `score` VALUES ('1', '1', '1', '10'), ('2', '1', '2', '9'), ('5', '1', '4', '66'), ('6', '2', '1', '8'), ('8', '2', '3', '68'), ('9', '2', '4', '99'), ('10', '3', '1', '77'), ('11', '3', '2', '66'), ('12', '3', '3', '87'), ('13', '3', '4', '99'), ('14', '4', '1', '79'), ('15', '4', '2', '11'), ('16', '4', '3', '67'), ('17', '4', '4', '100'), ('18', '5', '1', '79'), ('19', '5', '2', '11'), ('20', '5', '3', '67'), ('21', '5', '4', '100'), ('22', '6', '1', '9'), ('23', '6', '2', '100'), ('24', '6', '3', '67'), ('25', '6', '4', '100'), ('26', '7', '1', '9'), ('27', '7', '2', '100'), ('28', '7', '3', '67'), ('29', '7', '4', '88'), ('30', '8', '1', '9'), ('31', '8', '2', '100'), ('32', '8', '3', '67'), ('33', '8', '4', '88'), ('34', '9', '1', '91'), ('35', '9', '2', '88'), ('36', '9', '3', '67'), ('37', '9', '4', '22'), ('38', '10', '1', '90'), ('39', '10', '2', '77'), ('40', '10', '3', '43'), ('41', '10', '4', '87'), ('42', '11', '1', '90'), ('43', '11', '2', '77'), ('44', '11', '3', '43'), ('45', '11', '4', '87'), ('46', '12', '1', '90'), ('47', '12', '2', '77'), ('48', '12', '3', '43'), ('49', '12', '4', '87'), ('52', '13', '3', '87');
COMMIT;
-- ----------------------------
-- Table structure for `student`
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`gender` char(1) NOT NULL,
`class_id` int(11) NOT NULL,
`sname` varchar(32) NOT NULL,
PRIMARY KEY (`sid`),
KEY `fk_class` (`class_id`),
CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`)
) ENGINE=InnoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `student`
-- ----------------------------
BEGIN;
INSERT INTO `student` VALUES ('1', '男', '1', '理解'), ('2', '女', '1', '钢蛋'), ('3', '男', '1', '张三'), ('4', '男', '1', '张一'), ('5', '女', '1', '张二'), ('6', '男', '1', '张四'), ('7', '女', '2', '铁锤'), ('8', '男', '2', '李三'), ('9', '男', '2', '李一'), ('10', '女', '2', '李二'), ('11', '男', '2', '李四'), ('12', '女', '3', '如花'), ('13', '男', '3', '刘三'), ('14', '男', '3', '刘一'), ('15', '女', '3', '刘二'), ('16', '男', '3', '刘四');
COMMIT;
-- ----------------------------
-- Table structure for `teacher`
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`tid` int(11) NOT NULL AUTO_INCREMENT,
`tname` varchar(32) NOT NULL,
PRIMARY KEY (`tid`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of `teacher`
-- ----------------------------
BEGIN;
INSERT INTO `teacher` VALUES ('1', '张磊老师'), ('2', '李平老师'), ('3', '刘海燕老师'), ('4', '朱云海老师'), ('5', '李杰老师');
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
1、实列准备
#####从init.sql文件中导入数据
#准备表、记录
mysql> create database db1;
mysql> use db1;
mysql> source /root/init.sql
2、表结构
!!!重中之重:练习之前务必搞清楚sql逻辑查询语句的执行顺序
3、sql的使用
#案列:
# 1、查询所有的课程的名称以及对应的任课老师姓名
mysql> select teacher.tname,course.cname from course inner join teacher on course.teacher_id=teacher.tid;
# 2、查询学生表中男女生各有多少人
mysql> select gender,count(gender) from student group by gender
;
gender;
#3、查询物理成绩等于100的学生的姓名
SELECT
student.sname
FROM
student
WHERE
sid IN (
SELECT
student_id
FROM
score
INNER JOIN course ON score.course_id = course.cid
WHERE
course.cname = '物理'
AND score.num = 100
);
#4、查询平均成绩大于八十分的同学的姓名和平均成绩
SELECT
student.sname,
t1.avg_num
FROM
student
INNER JOIN (
SELECT
student_id,
avg(num) AS avg_num
FROM
score
GROUP BY
student_id
HAVING
avg(num) > 80
) AS t1 ON student.sid = t1.student_id;
#5、查询所有学生的学号,姓名,选课数,总成绩(注意:对于那些没有选修任何课程的学生也算在内)
SELECT
student.sid,
student.sname,
t1.course_num,
t1.total_num
FROM
student
LEFT JOIN (
SELECT
student_id,
COUNT(course_id) course_num,
sum(num) total_num
FROM
score
GROUP BY
student_id
) AS t1 ON student.sid = t1.student_id;
#6、 查询姓李老师的个数
SELECT
count(tid)
FROM
teacher
WHERE
tname LIKE '李%';
#7、 查询没有报李平老师课的学生姓名(找出报名李平老师课程的学生,然后取反就可以)
SELECT
student.sname
FROM
student
WHERE
sid NOT IN (
SELECT DISTINCT
student_id
FROM
score
WHERE
course_id IN (
SELECT
course.cid
FROM
course
INNER JOIN teacher ON course.teacher_id = teacher.tid
WHERE
teacher.tname = '李平老师'
)
);
#8、 查询物理课程比生物课程高的学生的学号(分别得到物理成绩表与生物成绩表,然后连表即可)
SELECT
t1.student_id
FROM
(
SELECT
student_id,
num
FROM
score
WHERE
course_id = (
SELECT
cid
FROM
course
WHERE
cname = '物理'
)
) AS t1
INNER JOIN (
SELECT
student_id,
num
FROM
score
WHERE
course_id = (
SELECT
cid
FROM
course
WHERE
cname = '生物'
)
) AS t2 ON t1.student_id = t2.student_id
WHERE
t1.num > t2.num;
#9、 查询没有同时选修物理课程和体育课程的学生姓名(没有同时选修指的是选修了一门的,思路是得到物理+体育课程的学生信息表,然后基于学生分组,统计count(课程)=1)
SELECT
student.sname
FROM
student
WHERE
sid IN (
SELECT
student_id
FROM
score
WHERE
course_id IN (
SELECT
cid
FROM
course
WHERE
cname = '物理'
OR cname = '体育'
)
GROUP BY
student_id
HAVING
COUNT(course_id) = 1
);
#10、查询挂科超过两门(包括两门)的学生姓名和班级(求出<60的表,然后对学生进行分组,统计课程数目>=2)
SELECT
student.sname,
class.caption
FROM
student
INNER JOIN (
SELECT
student_id
FROM
score
WHERE
num < 60
GROUP BY
student_id
HAVING
count(course_id) >= 2
) AS t1
INNER JOIN class ON student.sid = t1.student_id
AND student.class_id = class.cid;
#11、查询选修了所有课程的学生姓名(先从course表统计课程的总数,然后基于score表按照student_id分组,统计课程数据等于课程总数即可)
SELECT
student.sname
FROM
student
WHERE
sid IN (
SELECT
student_id
FROM
score
GROUP BY
student_id
HAVING
COUNT(course_id) = (SELECT count(cid) FROM course)
);
#12、查询李平老师教的课程的所有成绩记录
SELECT
*
FROM
score
WHERE
course_id IN (
SELECT
cid
FROM
course
INNER JOIN teacher ON course.teacher_id = teacher.tid
WHERE
teacher.tname = '李平老师'
);
#13、查询全部学生都选修了的课程号和课程名(取所有学生数,然后基于score表的课程分组,找出count(student_id)等于学生数即可)
SELECT
cid,
cname
FROM
course
WHERE
cid IN (
SELECT
course_id
FROM
score
GROUP BY
course_id
HAVING
COUNT(student_id) = (
SELECT
COUNT(sid)
FROM
student
)
);
#14、查询每门课程被选修的次数
SELECT
course_id,
COUNT(student_id)
FROM
score
GROUP BY
course_id;
#15、查询之选修了一门课程的学生姓名和学号
SELECT
sid,
sname
FROM
student
WHERE
sid IN (
SELECT
student_id
FROM
score
GROUP BY
student_id
HAVING
COUNT(course_id) = 1
);
#16、查询所有学生考出的成绩并按从高到低排序(成绩去重)
SELECT DISTINCT
num
FROM
score
ORDER BY
num DESC;
#17、查询平均成绩大于85的学生姓名和平均成绩
SELECT
sname,
t1.avg_num
FROM
student
INNER JOIN (
SELECT
student_id,
avg(num) avg_num
FROM
score
GROUP BY
student_id
HAVING
AVG(num) > 85
) t1 ON student.sid = t1.student_id;
#18、查询生物成绩不及格的学生姓名和对应生物分数
SELECT
sname 姓名,
num 生物成绩
FROM
score
LEFT JOIN course ON score.course_id = course.cid
LEFT JOIN student ON score.student_id = student.sid
WHERE
course.cname = '生物'
AND score.num < 60;
#19、查询在所有选修了李平老师课程的学生中,这些课程(李平老师的课程,不是所有课程)平均成绩最高的学生姓名
SELECT
sname
FROM
student
WHERE
sid = (
SELECT
student_id
FROM
score
WHERE
course_id IN (
SELECT
course.cid
FROM
course
INNER JOIN teacher ON course.teacher_id = teacher.tid
WHERE
teacher.tname = '李平老师'
)
GROUP BY
student_id
ORDER BY
AVG(num) DESC
LIMIT 1
);
#20、查询每门课程成绩最好的前两名学生姓名
#查看每门课程按照分数排序的信息,为下列查找正确与否提供依据
SELECT
*
FROM
score
ORDER BY
course_id,
num DESC;
#表1:求出每门课程的课程course_id,与最高分数first_num
SELECT
course_id,
max(num) first_num
FROM
score
GROUP BY
course_id;
# mysql> select num from score group by num desc limit 2;
#表2:去掉最高分,再按照课程分组,取得的最高分,就是第二高的分数second_num
SELECT
score.course_id,
max(num) second_num
FROM
score
INNER JOIN (
SELECT
course_id,
max(num) first_num
FROM
score
GROUP BY
course_id
) AS t ON score.course_id = t.course_id
WHERE
score.num < t.first_num
GROUP BY
course_id;
#将表1和表2联合到一起,得到一张表t3,包含课程course_id与该们课程的first_num与second_num
SELECT
t1.course_id,
t1.first_num,
t2.second_num
FROM
(
SELECT
course_id,
max(num) first_num
FROM
score
GROUP BY
course_id
) AS t1
INNER JOIN (
SELECT
score.course_id,
max(num) second_num
FROM
score
INNER JOIN (
SELECT
course_id,
max(num) first_num
FROM
score
GROUP BY
course_id
) AS t ON score.course_id = t.course_id
WHERE
score.num < t.first_num
GROUP BY
course_id
) AS t2 ON t1.course_id = t2.course_id;
#查询前两名的学生(有可能出现并列第一或者并列第二的情况)
SELECT
score.student_id,
t3.course_id,
t3.first_num,
t3.second_num
FROM
score
INNER JOIN (
SELECT
t1.course_id,
t1.first_num,
t2.second_num
FROM
(
SELECT
course_id,
max(num) first_num
FROM
score
GROUP BY
course_id
) AS t1
INNER JOIN (
SELECT
score.course_id,
max(num) second_num
FROM
score
INNER JOIN (
SELECT
course_id,
max(num) first_num
FROM
score
GROUP BY
course_id
) AS t ON score.course_id = t.course_id
WHERE
score.num < t.first_num
GROUP BY
course_id
) AS t2 ON t1.course_id = t2.course_id
) AS t3 ON score.course_id = t3.course_id
WHERE
score.num >= t3.second_num
AND score.num <= t3.first_num;
#排序后可以看的明显点
SELECT
score.student_id,
t3.course_id,
t3.first_num,
t3.second_num
FROM
score
INNER JOIN (
SELECT
t1.course_id,
t1.first_num,
t2.second_num
FROM
(
SELECT
course_id,
max(num) first_num
FROM
score
GROUP BY
course_id
) AS t1
INNER JOIN (
SELECT
score.course_id,
max(num) second_num
FROM
score
INNER JOIN (
SELECT
course_id,
max(num) first_num
FROM
score
GROUP BY
course_id
) AS t ON score.course_id = t.course_id
WHERE
score.num < t.first_num
GROUP BY
course_id
) AS t2 ON t1.course_id = t2.course_id
) AS t3 ON score.course_id = t3.course_id
WHERE
score.num >= t3.second_num
AND score.num <= t3.first_num
ORDER BY
course_id;
#可以用以下命令验证上述查询的正确性
SELECT
*
FROM
score
ORDER BY
course_id,
num DESC;
七、连表查询复习
题目:查询平均年纪在25岁以上的部门名称
#只要是多表查询就有两种方法 连表和子查询
方法1:连表
select depart.name from depart inner join emplo on emplo.dep_id =depart.id group by depart.name having avg(age)>25;
+--------------+
| name |
+--------------+
| 人力资源 |
| 销售 |
+--------------+
方法2:子查询
select name from depart where id in (select dep_id from emplo group by dep_id having avg(age)>25);
+--------------+
| name |
+--------------+
| 人力资源 |
| 销售 |
+--------------+
八、Navicat可视化界面
1.使用技巧和注意事项
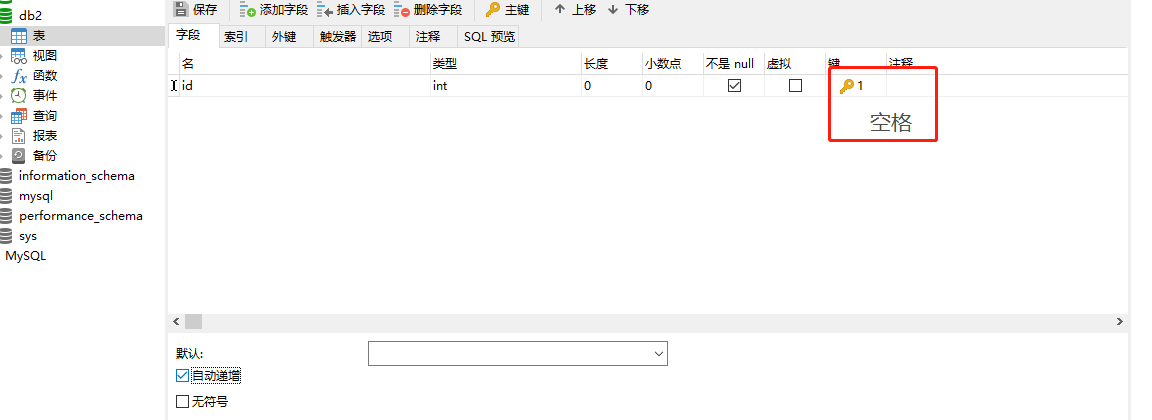
(1)外键的添加是用空格
(2)运行和转储SQL文件,逆向数据库到模型
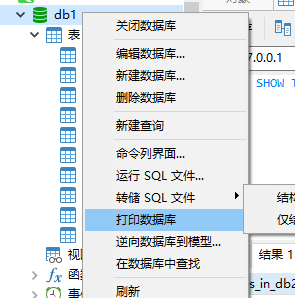
运行和转储SQL文件:是将外部的打开或者转存出去;逆向数据库到模型:呈现出表和表关系
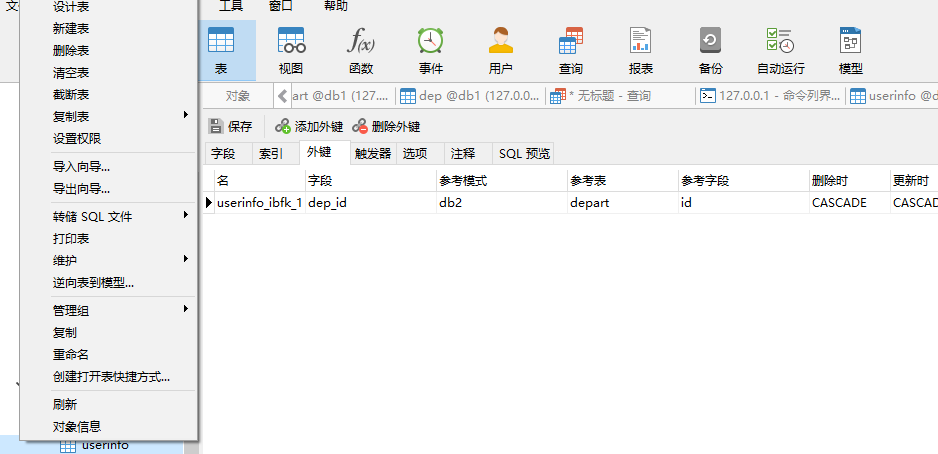
(3)添加外键
右键表名–设计表–添加外键–选择即可
(4)自己写sql语句
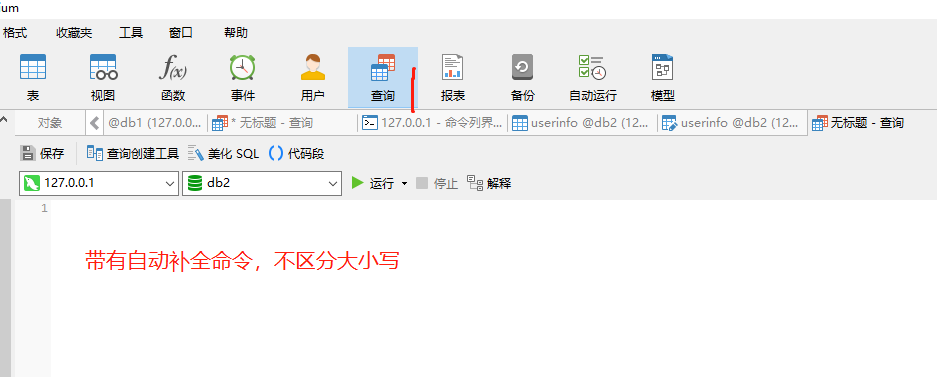
注释是ctrl+? 右键选中 命令单独运行命令
取消注释是ctrl +shift+ ?
navicat
是刷新有点慢,可以退回上一级,再次刷新就ok
# 提示
1、mysql不区分大小写
2、mysql建立所有的关键字是大写
# mysql里面的注释有两种
---
#
九:pymysql模块
(1)pymysql的安装
cmd管理员打开后--输入pip3 install pymysql 确认安装成功的话在中输入 import pymysql 就可确认
(2)pymysql 在py中的使用
import pymysql
#链接数据库
conn=pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='xxx',
charset='utf8', #不要加utf-8
database='db1'
)
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #产生一个游标对象,用来帮我们执行命令的,括号内是查询结果以字典的方式返回
sql='select *from emp;'
res=cursor.execute(sql) #此条必须输入
print(res) #返回的是你当前sql语句的行数(execute返回的数据)
print(cursor.fetchone()) #只返回一条
print(cursor.fetchall()) #返回所有的
print(cursor.fetchmany(2)) #可以指定拿几条,结果是空的,类似于文件的光标,此时文件光标在最后,所以内容是空的
(3)sql注入以及解决办法
import pymysql
#链接数据库
conn=pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='xxx',
charset='utf8',
database='db1'
)
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #产生一个游标对象,用来帮我们执行命令的,括号内是查询结果以字典的方式返回
username=input('>>>')
password=input('>>>')
sql='select *from user where name=%s and password=%s'
#不要手动的去拼接数据,先用%s进行占位,之后需要拼接数据直接交给 execute 方法即可
print(sql)
rows=cursor.execute(sql,(username,password))
if rows:
print('登录成功')
print(cursor.fetchall())
else:
print('用户名密码错误')
(4)对mysql的 增 删 改
import pymysql
#链接数据库
改:
conn=pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='xxx',
charset='utf8',
database='db1',
autocommit=True
)
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #产生一个游标对象,用来帮我们执行命令的,括号内是查询结果以字典的方式返回
sql="update emplo set name='zz' where id=1;"
print(cursor.execute(sql))增:单个的增加
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #产生一个游标对象,用来帮我们执行命令的,括号内是查询结果以字典的方式返回sql="insert emplo values(7,'mm','male',19,201)"print(cursor.execute(sql))多个的
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #产生一个游标对象,用来帮我们执行命令的,括号内是查询结果以字典的方式返回sql="insert emplo(name,password) values(%s,%s)"rows=cursor.executemany(sql,[('zz',123),('mm',456)])print(rows)
import pymysql
#链接数据库
改:
conn=pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='xxx',
charset='utf8',
database='db1',
autocommit=True
)
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #产生一个游标对象,用来帮我们执行命令的,括号内是查询结果以字典的方式返回
sql="update emplo set name='zz' where id=1;"
print(cursor.execute(sql))增:单个的增加
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #产生一个游标对象,用来帮我们执行命令的,括号内是查询结果以字典的方式返回sql="insert emplo values(7,'mm','male',19,201)"print(cursor.execute(sql))多个的
cursor=conn.cursor(cursor=pymysql.cursors.DictCursor) #产生一个游标对象,用来帮我们执行命令的,括号内是查询结果以字典的方式返回sql="insert emplo(name,password) values(%s,%s)"rows=cursor.executemany(sql,[('zz',123),('mm',456)])print(rows)















 962
962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











