







Java IO
字节流 InputStream FilterInputStream, BufferedInputStream, ByteArrayInputStream, DataInputStream, PrintStream
字节流 OutputStream FilterOutputStream, BufferedOutputStream, ByteArrayOutputStream, DataOutputStream,
字符流 Reader BufferedReader, LineNumberReader, CharArrayReader, InputStreamReader, FileReader, FilterReader, PushbackReader, PipedReader, StringReader
字符流 Writer BufferedWriter, CharArrayWriter, OutputStreamWriter, FileWriter,FilterWriter, PipedWriter, StringWriter, PrintWriter,
RandomAccessFile 随机访问文件流java IO 之 FilterInputStream和FilterOutputStream
java.io包中的字节流。 java.io包中的字节流中的类关系有用到GoF《设计模式》中的装饰者模式,
而这正体现在FilterInputStream和FilterOutputStream和它的子类上。
首先,这两个都分别是InputStream和OutputStream的子类。而且,FilterInputStream和FilterOutputStream 是具体的子类,
实现了InputStream和OutputStream这两个抽象类中为给出实现的方法。
但是,FilterInputStream和FilterOutputStream仅仅是“装饰者模式”封装的开始,它们在各个方法中的实现都是最基本的实现,
都是基于构造方法中传入参数封装的InputStream和OutputStream的原始对象。
比如,在FilterInputStream类中,封装了这样一个属性:
protected volatile InputStream in;
而对应的构造方法是:
protected FilterInputStream(InputStream in) {
this.in = in;
}
read()方法的实现则为:
public int read() throws IOException {
return in.read();
}
同样的输出流的构造方法是
public FilterOutputStream(OutputStream out) {
this.out = out;
}
write方法的实现:
public void write(int b) throws IOException {
out.write(b);
}
FilterInputStream 的作用是用来“封装其它的输入流,并为它们提供额外的功能”。它的常用的子类有BufferedInputStream和DataInputStream。
BufferedInputStream的作用就是为“输入流提供缓冲功能,以及mark()和reset()功能”。
DataInputStream 是用来装饰其它输入流,它“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。应用程序可以使用DataOutputStream(数据输出流)写入由DataInputStream(数据输入流)读取的数据
FilterOutputStream 的作用是用来“封装其它的输出流,并为它们提供额外的功能”。它主要包括BufferedOutputStream, DataOutputStream和PrintStream。
BufferedOutputStream的作用就是为“输出流提供缓冲功能”。
DataOutputStream 是用来装饰其它输出流,将DataOutputStream和DataInputStream输入流配合使用,“允许应用程序以与机器无关方式从底层输入流中读写基本 Java 数据类型”。
PrintStream 是用来装饰其它输出流。它能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。java IO 之 FileInputStream 和 FileOutputStream
FileInputStream 和 FileOutputStream都是直接怼到文件上的,也就是直接访问文件使用的,在这2个流上我们可以包装其他的流。
FileInputStream 是文件输入流,它继承于InputStream。通常,我们使用FileInputStream从某个文件中获得输入字节。
FileInputStream(File file) // 构造函数1:创建“File对象”对应的“文件输入流”
FileInputStream(FileDescriptor fd) // 构造函数2:创建“文件描述符”对应的“文件输入流”
FileInputStream(String path) // 构造函数3:创建“文件(路径为path)”对应的“文件输入流”
int available() // 返回“剩余的可读取的字节数”或者“skip的字节数”
void close() // 关闭“文件输入流”
FileChannel getChannel() // 返回“FileChannel”
final FileDescriptor getFD() // 返回“文件描述符”
int read() // 返回“文件输入流”的下一个字节
int read(byte[] buffer, int byteOffset, int byteCount) // 读取“文件输入流”的数据并存在到buffer,从byteOffset开始存储,存储长度是byteCount。
long skip(long byteCount) // 跳过byteCount个字节
FileOutputStream 是文件输出流,它继承于OutputStream。通常,我们使用FileOutputStream 将数据写入 File 或 FileDescriptor 的输出流。
FileOutputStream(File file) // 构造函数1:创建“File对象”对应的“文件输入流”;默认“追加模式”是false,即“写到输出的流内容”不是以追加的方式添加到文件中。
FileOutputStream(File file, boolean append) // 构造函数2:创建“File对象”对应的“文件输入流”;指定“追加模式”。
FileOutputStream(FileDescriptor fd) // 构造函数3:创建“文件描述符”对应的“文件输入流”;默认“追加模式”是false,即“写到输出的流内容”不是以追加的方式添加到文件中。
FileOutputStream(String path) // 构造函数4:创建“文件(路径为path)”对应的“文件输入流”;默认“追加模式”是false,即“写到输出的流内容”不是以追加的方式添加到文件中。
FileOutputStream(String path, boolean append) // 构造函数5:创建“文件(路径为path)”对应的“文件输入流”;指定“追加模式”。
void close() // 关闭“输出流”
FileChannel getChannel() // 返回“FileChannel”
final FileDescriptor getFD() // 返回“文件描述符”
void write(byte[] buffer, int byteOffset, int byteCount) // 将buffer写入到“文件输出流”中,从buffer的byteOffset开始写,写入长度是byteCount。
void write(int oneByte) // 写入字节oneByte到“文件输出流”中
java IO 之 BufferedInputStream 和 BufferedOutputStream
BufferedInputStream 是缓冲输入流。它继承于FilterInputStream。
BufferedInputStream 的作用是为另一个输入流添加一些功能,例如,提供“缓冲功能”以及支持“mark()标记”和“reset()重置方法”。
BufferedInputStream 本质上是通过一个内部缓冲区数组实现的( byte buf[];)。
例如,在新建某输入流对应的BufferedInputStream后,当我们通过read()读取输入流的数据时,BufferedInputStream会将该输入流的数据分批的填入到缓冲区中。
每当缓冲区中的数据被读完之后,输入流会再次填充数据缓冲区;如此反复,直到我们读完输入流数据位置。
说明:
要想读懂BufferedInputStream的源码,就要先理解它的思想。BufferedInputStream的作用是为其它输入流提供缓冲功能。
创建BufferedInputStream时,我们会通过它的构造函数指定某个输入流为参数。BufferedInputStream会将该输入流数据分批读取,每次读取一部分到缓冲中;操作完缓冲中的这部分数据之后,再从输入流中读取下一部分的数据。
为什么需要缓冲呢?原因很简单,效率问题!缓冲中的数据实际上是保存在内存中,而原始数据可能是保存在硬盘或NandFlash等存储介质中;而我们知道,从内存中读取数据的速度比从硬盘读取数据的速度至少快10倍以上。
那干嘛不干脆一次性将全部数据都读取到缓冲中呢?第一,读取全部的数据所需要的时间可能会很长。第二,内存价格很贵,容量不像硬盘那么大。
BufferedOutputStream 是缓冲输出流。它继承于FilterOutputStream。
BufferedOutputStream 的作用是为另一个输出流提供“缓冲功能”。
说明:
BufferedOutputStream的源码非常简单,这里就BufferedOutputStream的思想进行简单说明:B
ufferedOutputStream通过字节数组来缓冲数据,当缓冲区满或者用户调用flush()函数时,它就会将缓冲区的数据写入到输出流中。
当写入缓冲区小于实际的缓冲区大小,他不会执行情况缓冲区操作(即,将缓冲数据写入到输出流中),在执行close()后 它会关闭输出流;在关闭输出流之前,会将缓冲区的数据写入到输出流中。
如果手动执行了flush()操作会将缓冲区的数据写入到输出流中。
如果写入缓冲区的大于实际缓冲区大小,他会直接 写入都输出流中,而不经过缓冲区。
java IO 之 FileDescriptor
FileDescriptor 是“文件描述符”。
FileDescriptor 可以被用来表示开放文件、开放套接字等。
以FileDescriptor表示文件来说:当FileDescriptor表示某文件时,我们可以通俗的将FileDescriptor看成是该文件。
但是,我们不能直接通过FileDescriptor对该文件进行操作;若需要通过FileDescriptor对该文件进行操作,则需要新创建FileDescriptor对应的FileOutputStream,再对文件进行操作。
in, out, err介绍
(01) in -- 标准输入(键盘)的描述符
public static final FileDescriptor in = standardStream(0);
(02) out -- 标准输出(屏幕)的描述符
public static final FileDescriptor out = standardStream(1);
(03) err -- 标准错误输出(屏幕)的描述符
public static final FileDescriptor err = standardStream(2);
out 的作用和原理
out是标准输出(屏幕)的描述符。但是它有什么作用呢?
我们可以通俗理解,out就代表了标准输出(屏幕)。若我们要输出信息到屏幕上,即可通过out来进行操作;
但是,out又没有提供输出信息到屏幕的接口(因为out本质是FileDescriptor对象,而FileDescriptor没有输出接口)。怎么办呢?
很简单,我们创建out对应的“输出流对象”,然后通过“输出流”的write()等输出接口就可以将信息输出到屏幕上。如下代码:
try {
FileOutputStream out = new FileOutputStream(FileDescriptor.out);
out.write('A');
out.close();
} catch (IOException e) {
}
执行上面的程序,会在屏幕上输出字母'A'。
为了方便我们操作,java早已为我们封装好了“能方便的在屏幕上输出信息的接口”:通过System.out,我们能方便的输出信息到屏幕上。
因此,我们可以等价的将上面的程序转换为如下代码:
System.out.print('A');
java IO之 字节数组流 ByteArrayInputStream 和 ByteArrayOutputStream
ByteArrayInputStream 是字节数组输入流。它继承于InputStream。
它包含一个内部缓冲区,该缓冲区包含从流中读取的字节;通俗点说,它的内部缓冲区就是一个字节数组,而ByteArrayInputStream本质就是通过字节数组来实现的。
我们都知道,InputStream通过read()向外提供接口,供它们来读取字节数据;而ByteArrayInputStream 的内部额外的定义了一个计数器,它被用来跟踪 read() 方法要读取的下一个字节。
ByteArrayInputStream实际上是通过“字节数组”去保存数据。
(01) 通过ByteArrayInputStream(byte buf[]) 或 ByteArrayInputStream(byte buf[], int offset, int length) ,我们可以根据buf数组来创建字节流对象。
(02) read()的作用是从字节流中“读取下一个字节”。
(03) read(byte[] buffer, int offset, int length)的作用是从字节流读取字节数据,并写入到字节数组buffer中。offset是将字节写入到buffer的起始位置,length是写入的字节的长度。
(04) markSupported()是判断字节流是否支持“标记功能”。它一直返回true。
(05) mark(int readlimit)的作用是记录标记位置。记录标记位置之后,某一时刻调用reset()则将“字节流下一个被读取的位置”重置到“mark(int readlimit)所标记的位置”;也就是说,reset()之后再读取字节流时,是从mark(int readlimit)所标记的位置开始读取。
ByteArrayOutputStream 是字节数组输出流。它继承于OutputStream。
ByteArrayOutputStream 中的数据被写入一个 byte 数组。缓冲区会随着数据的不断写入而自动增长。可使用 toByteArray() 和 toString() 获取数据。
ByteArrayOutputStream实际上是将字节数据写入到“字节数组”中去。
(01) 通过ByteArrayOutputStream()创建的“字节数组输出流”对应的字节数组大小是32。
(02) 通过ByteArrayOutputStream(int size) 创建“字节数组输出流”,它对应的字节数组大小是size。
(03) write(int oneByte)的作用将int类型的oneByte换成byte类型,然后写入到输出流中。
(04) write(byte[] buffer, int offset, int len) 是将字节数组buffer写入到输出流中,offset是从buffer中读取数据的起始偏移位置,len是读取的长度。
(05) writeTo(OutputStream out) 将该“字节数组输出流”的数据全部写入到“输出流out”中。
java IO 之 管道 PipedInputStream 和 PipedOutputStream
PipedInputStream 是管道输入流,继承自InputStream。
PipedOutputStream 是管道输出流 , 继承自OutputStream。
它们的作用是让多线程可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedOutputStream和PipedInputStream配套使用。
使用管道通信时,大致的流程是:我们在线程A中向PipedOutputStream中写入数据,这些数据会自动的发送到与PipedOutputStream对应的PipedInputStream中,
进而存储在PipedInputStream的缓冲中;此时,线程B通过读取PipedInputStream中的数据。就可以实现,线程A和线程B的通信。
java IO 之 PipedReader和PipedWriter
PipedWriter 是字符管道输出流,它继承于Writer。
PipedReader 是字符管道输入流,它继承于Writer。
PipedWriter和PipedReader的作用是可以通过管道进行线程间的通讯。在使用管道通信时,必须将PipedWriter和PipedReader配套使用。
java IO 之 对象流 ObjectInputStream 和 ObjectOutputStream
ObjectInputStream 和 ObjectOutputStream 的作用是,对基本数据和对象进行序列化操作支持。
创建“文件输出流”对应的ObjectOutputStream对象,该ObjectOutputStream对象能提供对“基本数据或对象”的持久存储;
当我们需要读取这些存储的“基本数据或对象”时,可以创建“文件输入流”对应的ObjectInputStream,进而读取出这些“基本数据或对象”。
通过ObjectInputStream, ObjectOutputStream操作的对象,必须是实现了Serializable或Externalizable序列化接口的类的实例。
序列化,就是为了保存对象的状态;而与之对应的反序列化,则可以把保存的对象状态再读出来。
简言之:序列化/反序列化,是Java提供一种专门用于的保存/恢复对象状态的机制。
一般在以下几种情况下,我们可能会用到序列化:
a)当你想把的内存中的对象状态保存到一个文件中或者数据库中时候;
b)当你想用套接字在网络上传送对象的时候;
c)当你想通过RMI传输对象的时候。
(01) 序列化对static和transient变量,是不会自动进行状态保存的。
transient的作用就是,用transient声明的变量,不会被自动序列化。
(02) 对于Socket, Thread类,不支持序列化。若实现序列化的接口中,有Thread成员;在对该类进行序列化操作时,编译会出错!
这主要是基于资源分配方面的原因。如果Socket,Thread类可以被序列化,但是被反序列化之后也无法对他们进行重新的资源分配;再者,也是没有必要这样实现。
“序列化不会自动保存static和transient变量”,因此我们若要保存它们,则需要通过writeObject()和readObject()去手动读写。
事实证明,不能对Thread进行序列化。若希望程序能编译通过,我们对Thread变量添加static或transient修饰即可。
如果一个类要完全负责自己的序列化,则实现Externalizable接口,而不是Serializable接口。
Externalizable接口定义包括两个方法writeExternal()与readExternal()。需要注意的是:声明类实现Externalizable接口会有重大的安全风险。
writeExternal()与readExternal()方法声明为public,恶意类可以用这些方法读取和写入对象数据。如果对象包含敏感信息,则要格外小心。
(01) 实现Externalizable接口的类,不会像实现Serializable接口那样,会自动将数据保存。
(02) 实现Externalizable接口的类,必须实现writeExternal()和readExternal()接口! 否则,程序无法正常编译!
(03) 实现Externalizable接口的类,必须定义不带参数的构造函数! 否则,程序无法正常编译!
(04) writeExternal() 和 readExternal() 的方法都是public的,不是非常安全!
java IO 之 DataInputStream 和 DataInputStream
DataInputStream 是数据输入流。它继承于FilterInputStream。
DataInputStream 是用来装饰其它输入流,它“允许应用程序以与机器无关方式从底层输入流中读取基本 Java 数据类型”。
应用程序可以使用DataOutputStream(数据输出流)写入,由DataInputStream(数据输入流)读取的数据。
DataInputStream(InputStream in)
final int read(byte[] buffer, int offset, int length)
final int read(byte[] buffer)
final boolean readBoolean()
final byte readByte()
final char readChar()
final double readDouble()
final float readFloat()
final void readFully(byte[] dst)
final void readFully(byte[] dst, int offset, int byteCount)
final int readInt()
final String readLine()
final long readLong()
final short readShort()
final static String readUTF(DataInput in)
final String readUTF()
final int readUnsignedByte()
final int readUnsignedShort()
final int skipBytes(int count)
DataInputStream 中比较难以理解的函数就只有 readUTF(DataInput in);
说明:
readUTF()的作用,是从输入流中读取UTF-8编码的数据,并以String字符串的形式返回。
DataOutputStream 是数据输出流。它继承于FilterOutputStream。
DataOutputStream 是用来装饰其它输出流,将DataOutputStream和DataInputStream输入流配合使用,“允许应用程序以与机器无关方式从底层输入流中读写基本 Java 数据类型”。
java IO 之 PrintStream(打印输出流)
PrintStream 是打印输出流,它继承于FilterOutputStream。
PrintStream 是用来装饰其它输出流。它能为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
与其他输出流不同,PrintStream 永远不会抛出 IOException;它产生的IOException会被自身的函数所捕获并设置错误标记, 用户可以通过 checkError() 返回错误标记,从而查看PrintStream内部是否产生了IOException。
另外,PrintStream 提供了自动flush 和 字符集设置功能。所谓自动flush,就是往PrintStream写入的数据会立刻调用flush()函数。
我们先看看System.out.println的流程。先看看System.java中out的定义,源码如下:
public final static PrintStream out = null;
java IO 之 CharArrayReader 和 CharArrayWriter
CharArrayReader 是字符数组输入流。它和ByteArrayInputStream类似,只不过ByteArrayInputStream是字节数组输入流,
而CharArray是字符数组输入流。CharArrayReader 是用于读取字符数组,它继承于Reader。操作的数据是以字符为单位!
说明:
CharArrayReader实际上是通过“字符数组”去保存数据。
(01) 通过 CharArrayReader(char[] buf) 或 CharArrayReader(char[] buf, int offset, int length) ,我们可以根据buf数组来创建CharArrayReader对象。
(02) read()的作用是从CharArrayReader中“读取下一个字符”。
(03) read(char[] buffer, int offset, int len)的作用是从CharArrayReader读取字符数据,并写入到字符数组buffer中。offset是将字符写入到buffer的起始位置,len是写入的字符的长度。
(04) markSupported()是判断CharArrayReader是否支持“标记功能”。它始终返回true。
(05) mark(int readlimit)的作用是记录标记位置。记录标记位置之后,某一时刻调用reset()则将“CharArrayReader下一个被读取的位置”重置到“mark(int readlimit)所标记的位置”;也就是说,reset()之后再读取CharArrayReader时,是从mark(int readlimit)所标记的位置开始读取。
CharArrayWriter 用于写入数据符,它继承于Writer。操作的数据是以字符为单位!
说明:
CharArrayWriter实际上是将数据写入到“字符数组”中去。
(01) 通过CharArrayWriter()创建的CharArrayWriter对应的字符数组大小是32。
(02) 通过CharArrayWriter(int size) 创建的CharArrayWriter对应的字符数组大小是size。
(03) write(int oneChar)的作用将int类型的oneChar换成char类型,然后写入到CharArrayWriter中。
(04) write(char[] buffer, int offset, int len) 是将字符数组buffer写入到输出流中,offset是从buffer中读取数据的起始偏移位置,len是读取的长度。
(05) write(String str, int offset, int count) 是将字符串str写入到输出流中,offset是从str中读取数据的起始位置,count是读取的长度。
(06) append(char c)的作用将char类型的c写入到CharArrayWriter中,然后返回CharArrayWriter对象。
注意:append(char c)与write(int c)都是将单个字符写入到CharArrayWriter中。它们的区别是,append(char c)会返回CharArrayWriter对象,但是write(int c)返回void。
(07) append(CharSequence csq, int start, int end)的作用将csq从start开始(包括)到end结束(不包括)的数据,写入到CharArrayWriter中。
注意:该函数返回CharArrayWriter对象!
(08) append(CharSequence csq)的作用将csq写入到CharArrayWriter中。
注意:该函数返回CharArrayWriter对象!
(09) writeTo(OutputStream out) 将该“字符数组输出流”的数据全部写入到“输出流out”中。
java IO 之 InputStreamReader 和 OutputStreamWriter
InputStreamReader和OutputStreamWriter 是字节流通向字符流的桥梁:它使用指定的 charset 读写字节并将其解码为字符。
InputStreamReader 的作用是将“字节输入流”转换成“字符输入流”。它继承于Reader。
OutputStreamWriter 的作用是将“字节输出流”转换成“字符输出流”。它继承于Writer。
java IO 之 FileReader和FileWriter
FileReader 是用于读取字符流的类,它继承于InputStreamReader。要读取原始字节流,请考虑使用 FileInputStream。
FileWriter 是用于写入字符流的类,它继承于OutputStreamWriter。要写入原始字节流,请考虑使用 FileOutputStream。
java IO 之 BufferedReader(字符缓冲输入流) 和 BufferedWriter(字符缓冲输出流)
BufferedReader 是缓冲字符输入流。它继承于Reader。
BufferedReader 的作用是为其他字符输入流添加一些缓冲功能。
// 构造函数
BufferedReader(Reader in)
BufferedReader(Reader in, int size)
void close()
void mark(int markLimit)
boolean markSupported()
int read()
int read(char[] buffer, int offset, int length)
String readLine()
boolean ready()
void reset()
long skip(long charCount)
BufferedWriter 是缓冲字符输出流。它继承于Writer。
BufferedWriter 的作用是为其他字符输出流添加一些缓冲功能。
// 构造函数
BufferedWriter(Writer out)
BufferedWriter(Writer out, int sz)
void close() // 关闭此流,但要先刷新它。
void flush() // 刷新该流的缓冲。
void newLine() // 写入一个行分隔符。
void write(char[] cbuf, int off, int len) // 写入字符数组的某一部分。
void write(int c) // 写入单个字符。
void write(String s, int off, int len) // 写入字符串的某一部分。
java IO 之 PrintWriter (字符打印输出流)
PrintWriter 是字符类型的打印输出流,它继承于Writer。
PrintStream 用于向文本输出流打印对象的格式化表示形式。它实现在 PrintStream 中的所有 print 方法。
它不包含用于写入原始字节的方法,对于这些字节,程序应该使用未编码的字节流进行写入。
java IO 之 RandomAccessFile
RandomAccessFile 是随机访问文件(包括读/写)的类。它支持对文件随机访问的读取和写入,即我们可以从指定的位置读取/写入文件数据。
需要注意的是,RandomAccessFile 虽然属于java.io包,但它不是InputStream或者OutputStream的子类;
它也不同于FileInputStream和FileOutputStream。 FileInputStream 只能对文件进行读操作,而FileOutputStream 只能对文件进行写操作;
但是,RandomAccessFile 同时支持文件的读和写,并且它支持随机访问。
RandomAccessFile共有4种模式:"r", "rw", "rws"和"rwd"。
"r" 以只读方式打开。调用结果对象的任何 write 方法都将导致抛出 IOException。
"rw" 打开以便读取和写入。
"rws" 打开以便读取和写入。相对于 "rw","rws" 还要求对“文件的内容”或“元数据”的每个更新都同步写入到基础存储设备。
"rwd" 打开以便读取和写入,相对于 "rw","rwd" 还要求对“文件的内容”的每个更新都同步写入到基础存储设备。
java NIO
NIO即New IO,这个库是在JDK1.4中才引入的。NIO和IO有相同的作用和目的,但实现方式不同,
NIO主要用到的是块,所以NIO的效率要比IO高很多。在Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。
Java IO和NIO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。
Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。
Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。 线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。非阻塞是对于网络io的。
NIO缓冲区,buffer,负责存取数据的,顶层是数组。
allocate() 分配非直接缓冲区,建立在jvm的内存中。
allocateDirect()分配直接缓冲区。
put()存入数据到缓冲区
get()获取缓冲区中的数据
flip() 切换读写模式 先设置limit为当前的position。 然后重置position为0
rewind()可重复读取数据 重置position为0
clear()重置position为0,limit为capacity。
capacity 容量,缓冲区最大存储容量,一旦声明不能改变。
limit 界限,缓冲区中可以操作数据的大小,limit后面的数据是不能进行读写操作的。
position 位置,缓冲区中正在操作的数据的位置。
mark 记录当前position的位置的,可以通过mark()和reset()来设置和恢复
0 <= mark <= position <= limit <= capacity
通道直接的数据传输
inChannel.transferTo(0, inChannel.size(), outChannel);
outChannel.transferFrom(inChannel, 0, inChannel.size());
分散读取,聚集写入
ByteBuffer[] bufs = {byteBuffer1, byteBuffer2};
channel.read(bufs);
ByteBuffer[] bufs = {byteBuffer1, byteBuffer2};
channel.write(bufs); //GatheringByteChannel
字符编码和解码
编码是 字符串 转换为 字节数组
解码是 字节数组 转换为 字符串
字符编码
1. ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
2、非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的Unicode和UTF-8是毫无关系的。
3.Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字"严"。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
4. Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字"严"的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了Unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示Unicode。2)Unicode在很长一段时间内无法推广,直到互联网的出现。
5.UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读UTF-8编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字"严"为例,演示如何实现UTF-8编码。
已知"严"的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100 10111000 10100101",转换成十六进制就是E4B8A5。
big endian(大端法)是指低地址存放最高有效字节(MSB),大端模式,是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
little endian(小端法)则是低地址存放最低有效字节(LSB)小端模式,是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
。
java 多线程
多线程是Java中不可避免的一个重要主体。从本章开始,我们将展开对多线程的学习。接下来的内容,
是对“JDK中新增JUC包”之前的Java多线程内容的讲解,涉及到的内容包括,Object类中的wait(), notify()等接口;Thread类中的接口;synchronized关键字。
注:JUC包是指,Java.util.concurrent包,它是由Java大师Doug Lea完成并在JDK1.5版本添加到Java中的。
线程状态图
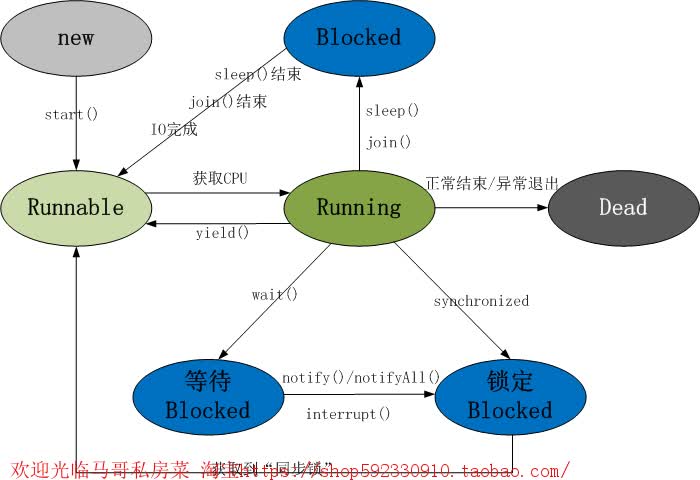
线程共包括以下5种状态。
1. 新建状态(New) : 线程对象被创建后,就进入了新建状态。例如,Thread thread = new Thread()。
2. 就绪状态(Runnable): 也被称为“可执行状态”。线程对象被创建后,其它线程调用了该对象的start()方法,
从而来启动该线程。例如,thread.start()。处于就绪状态的线程,随时可能被CPU调度执行。
3. 运行状态(Running) : 线程获取CPU权限进行执行。需要注意的是,线程只能从就绪状态进入到运行状态。
4. 阻塞状态(Blocked) : 阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
(01) 等待阻塞 -- 通过调用线程的wait()方法,让线程等待某工作的完成。
(02) 同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态。
(03) 其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。
当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
5. 死亡状态(Dead) : 线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
这5种状态涉及到的内容包括Object类, Thread和synchronized关键字。这些内容我们会在后面的章节中逐个进行学习。
Object类,定义了wait(), notify(), notifyAll()等休眠/唤醒函数。
Thread类,定义了一些列的线程操作函数。例如,sleep()休眠函数, interrupt()中断函数, getName()获取线程名称等。
synchronized,是关键字;它区分为synchronized代码块和synchronized方法。synchronized的作用是让线程获取对象的同步锁。
在后面详细介绍wait(),notify()等方法时,我们会分析为什么“wait(), notify()等方法要定义在Object类,而不是Thread类中”。
常用的实现多线程的2种方式:Thread 和 Runnable。
Runnable 是一个接口,该接口中只包含了一个run()方法。它的定义如下:
public interface Runnable {
public abstract void run();
}
Runnable的作用,实现多线程。我们可以定义一个类A实现Runnable接口;然后,通过new Thread(new A())等方式新建线程。
Thread 是一个类。Thread本身就实现了Runnable接口。它的声明如下:
public class Thread implements Runnable {}
Thread的作用,实现多线程。
Thread 和 Runnable 的相同点:都是“多线程的实现方式”。
Thread 和 Runnable 的不同点:
Thread 是类,而Runnable是接口;Thread本身是实现了Runnable接口的类。我们知道“一个类只能有一个父类,但是却能实现多个接口”,因此Runnable具有更好的扩展性。
此外,Runnable还可以用于“资源的共享”。即,多个线程都是基于某一个Runnable对象建立的,它们会共享Runnable对象上的资源。
通常,建议通过“Runnable”实现多线程!
start() 和 run()的区别说明
start() : 它的作用是启动一个新线程,新线程会执行相应的run()方法。start()不能被重复调用。
run() : run()就和普通的成员方法一样,可以被重复调用。单独调用run()的话,会在当前线程中执行run(),而并不会启动新线程!synchronized介绍
synchronized原理
在java中,每一个对象有且仅有一个同步锁。这也意味着,同步锁是依赖于对象而存在。
当我们调用某对象的synchronized方法时,就获取了该对象的同步锁。例如,synchronized(obj)就获取了“obj这个对象”的同步锁。
不同线程对同步锁的访问是互斥的。也就是说,某时间点,对象的同步锁只能被一个线程获取到!通过同步锁,我们就能在多线程中,
实现对“对象/方法”的互斥访问。 例如,现在有两个线程A和线程B,它们都会访问“对象obj的同步锁”。
假设,在某一时刻,线程A获取到“obj的同步锁”并在执行一些操作;而此时,线程B也企图获取“obj的同步锁” —— 线程B会获取失败,
它必须等待,直到线程A释放了“该对象的同步锁”之后线程B才能获取到“obj的同步锁”从而才可以运行。
我们将synchronized的基本规则总结为下面3条,并通过实例对它们进行说明。
第一条: 当一个线程访问“某对象”的“synchronized方法”或者“synchronized代码块”时,其他线程对“该对象”的该“synchronized方法”或者“synchronized代码块”的访问将被阻塞。
第二条: 当一个线程访问“某对象”的“synchronized方法”或者“synchronized代码块”时,其他线程仍然可以访问“该对象”的非同步代码块。
第三条: 当一个线程访问“某对象”的“synchronized方法”或者“synchronized代码块”时,其他线程对“该对象”的其他的“synchronized方法”或者“synchronized代码块”的访问将被阻塞。
实例锁 -- 锁在某一个实例对象上。如果该类是单例,那么该锁也具有全局锁的概念。
实例锁对应的就是synchronized关键字。
全局锁 -- 该锁针对的是类,无论实例多少个对象,那么线程都共享该锁。
全局锁对应的就是static synchronized(或者是锁在该类的class或者classloader对象上)。
关于“实例锁”和“全局锁”有一个很形象的例子:
pulbic class Something {
public synchronized void isSyncA(){}
public synchronized void isSyncB(){}
public static synchronized void cSyncA(){}
public static synchronized void cSyncB(){}
}
假设,Something有两个实例x和y。分析下面4组表达式获取的锁的情况。
(01) x.isSyncA()与x.isSyncB()
(01) 不能被同时访问。因为isSyncA()和isSyncB()都是访问同一个对象(对象x)的同步锁!
(02) x.isSyncA()与y.isSyncA()
(02) 可以同时被访问。因为访问的不是同一个对象的同步锁,x.isSyncA()访问的是x的同步锁,而y.isSyncA()访问的是y的同步锁。
(03) x.cSyncA()与y.cSyncB()
(03) 不能被同时访问。因为cSyncA()和cSyncB()都是static类型,
x.cSyncA()相当于Something.isSyncA(),y.cSyncB()相当于Something.isSyncB(),因此它们共用一个同步锁,不能被同时反问。
(04) x.isSyncA()与Something.cSyncA()
可以被同时访问。因为isSyncA()是实例方法,x.isSyncA()使用的是对象x的锁;
而cSyncA()是静态方法,Something.cSyncA()可以理解对使用的是“类的锁”。因此,它们是可以被同时访问的。wait(), notify(), notifyAll()等方法介绍
在Object.java中,定义了wait(), notify()和notifyAll()等接口。wait()的作用是让当前线程进入等待状态,同时,wait()也会让当前线程释放它所持有的锁。而notify()和notifyAll()的作用,则是唤醒当前对象上的等待线程;notify()是唤醒单个线程,而notifyAll()是唤醒所有的线程。
Object类中关于等待/唤醒的API详细信息如下:
notify() -- 唤醒在此对象监视器上等待的单个线程。
notifyAll() -- 唤醒在此对象监视器上等待的所有线程。
wait() -- 让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法”,当前线程被唤醒(进入“就绪状态”)。
wait(long timeout) -- 让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过指定的时间量”,当前线程被唤醒(进入“就绪状态”)。
wait(long timeout, int nanos) -- 让当前线程处于“等待(阻塞)状态”,“直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量”,当前线程被唤醒(进入“就绪状态”)。
为什么notify(), wait()等函数定义在Object中,而不是Thread中
Object中的wait(), notify()等函数,和synchronized一样,会对“对象的同步锁”进行操作。
wait()会使“当前线程”等待,因为线程进入等待状态,所以线程应该释放它锁持有的“同步锁”,否则其它线程获取不到该“同步锁”而无法运行!
OK,线程调用wait()之后,会释放它锁持有的“同步锁”;而且,根据前面的介绍,我们知道:等待线程可以被notify()或notifyAll()唤醒。现在,请思考一个问题:notify()是依据什么唤醒等待线程的?或者说,wait()等待线程和notify()之间是通过什么关联起来的?答案是:依据“对象的同步锁”。
负责唤醒等待线程的那个线程(我们称为“唤醒线程”),它只有在获取“该对象的同步锁”(这里的同步锁必须和等待线程的同步锁是同一个),并且调用notify()或notifyAll()方法之后,才能唤醒等待线程。虽然,等待线程被唤醒;但是,它不能立刻执行,因为唤醒线程还持有“该对象的同步锁”。必须等到唤醒线程释放了“对象的同步锁”之后,等待线程才能获取到“对象的同步锁”进而继续运行。
总之,notify(), wait()依赖于“同步锁”,而“同步锁”是对象锁持有,并且每个对象有且仅有一个!这就是为什么notify(), wait()等函数定义在Object类,而不是Thread类中的原因。
线程让步 yield
yield()的作用是让步。它能让当前线程由“运行状态”进入到“就绪状态”,从而让其它具有相同优先级的等待线程获取执行权;
但是,并不能保证在当前线程调用yield()之后,其它具有相同优先级的线程就一定能获得执行权;也有可能是当前线程又进入到“运行状态”继续运行!
wait()是会线程释放它所持有对象的同步锁,而yield()方法不会释放锁。线程休眠
sleep() 定义在Thread.java中。
sleep() 的作用是让当前线程休眠,即当前线程会从“运行状态”进入到“休眠(阻塞)状态”。
sleep()会指定休眠时间,线程休眠的时间会大于/等于该休眠时间;在线程重新被唤醒时,它会由“阻塞状态”变成“就绪状态”,从而等待cpu的调度执行。
我们知道,wait()的作用是让当前线程由“运行状态”进入“等待(阻塞)状态”的同时,也会释放同步锁。而sleep()的作用是也是让当前线程由“运行状态”进入到“休眠(阻塞)状态”。
但是,wait()会释放对象的同步锁,而sleep()则不会释放锁。线程join
join() 的作用:让“主线程”等待“子线程”结束之后才能继续运行。
它可以使得线程之间的并行执行变为串行执行,join方法必须在线程start方法调用之后调用才有意义
线程 interrupt()和线程终止方式
interrupt()的作用是中断本线程。
本线程中断自己是被允许的;其它线程调用本线程的interrupt()方法时,会通过checkAccess()检查权限。这有可能抛出SecurityException异常。
如果本线程是处于阻塞状态:调用线程的wait(), wait(long)或wait(long, int)会让它进入等待(阻塞)状态,或者调用线程的join(), join(long), join(long, int), sleep(long), sleep(long, int)也会让它进入阻塞状态。若线程在阻塞状态时,调用了它的interrupt()方法,那么它的“中断状态”会被清除并且会收到一个InterruptedException异常。例如,线程通过wait()进入阻塞状态,此时通过interrupt()中断该线程;调用interrupt()会立即将线程的中断标记设为“true”,但是由于线程处于阻塞状态,所以该“中断标记”会立即被清除为“false”,同时,会产生一个InterruptedException的异常。
如果线程被阻塞在一个Selector选择器中,那么通过interrupt()中断它时;线程的中断标记会被设置为true,并且它会立即从选择操作中返回。
如果不属于前面所说的情况,那么通过interrupt()中断线程时,它的中断标记会被设置为“true”。
中断一个“已终止的线程”不会产生任何操作。
interrupted() 和 isInterrupted()都能够用于检测对象的“中断标记”。
区别是,interrupted()除了返回中断标记之外,它还会清除中断标记(即将中断标记设为false);而isInterrupted()仅仅返回中断标记。
线程优先级
java 中的线程优先级的范围是1~10,默认的优先级是5。“高优先级线程”会优先于“低优先级线程”执行。
java 中有两种线程:用户线程和守护线程。可以通过isDaemon()方法来区别它们:如果返回false,则说明该线程是“用户线程”;否则就是“守护线程”。
用户线程一般用户执行用户级任务,而守护线程也就是“后台线程”,一般用来执行后台任务。需要注意的是:Java虚拟机在“用户线程”都结束后会后退出。
每个线程都有一个优先级。“高优先级线程”会优先于“低优先级线程”执行。每个线程都可以被标记为一个守护进程或非守护进程。在一些运行的主线程中创建新的子线程时,子线程的优先级被设置为等于“创建它的主线程的优先级”,当且仅当“创建它的主线程是守护线程”时“子线程才会是守护线程”。
当Java虚拟机启动时,通常有一个单一的非守护线程(该线程通过是通过main()方法启动)。JVM会一直运行直到下面的任意一个条件发生,JVM就会终止运行:
(01) 调用了exit()方法,并且exit()有权限被正常执行。
(02) 所有的“非守护线程”都死了(即JVM中仅仅只有“守护线程”)。
每一个线程都被标记为“守护线程”或“用户线程”。当只有守护线程运行时,JVM会自动退出。多线程,线程同步,并发操作怎么控制
1)现在有T1、T2、T3三个线程,你怎样保证T2在T1执行完后执行,T3在T2执行完后执行?
这个线程问题通常会在第一轮或电话面试阶段被问到,目的是检测你对”join”方法是否熟悉。这个多线程问题比较简单,可以用join方法实现。
Java中可在方法名前加关键字syschronized来处理当有多个线程同时访问共享资源时候的问题。syschronized相当于一把锁,当有申请者申请该
资源时,如果该资源没有被占用,那么将资源交付给这个申请者使用,在此期间,其他申请者只能申请而不能使用该资源,当该资源被使用完成后将释放该资源上的锁,其他申请者可申请使用。
并发控制主要是为了多线程操作时带来的资源读写问题。如果不加以控制可能会出现死锁,读脏数据、不可重复读、丢失更新等异常。
并发操作可以通过加锁的方式进行控制,锁又可分为乐观锁和悲观锁。
悲观锁:
悲观锁并发模式假定系统中存在足够多的数据修改操作,以致于任何确定的读操作都可能会受到由个别的用户所制造的数据修改的影响。
也就是说悲观锁假定冲突总会发生,通过独占正在被读取的数据来避免冲突。但是独占数据会导致其他进程无法修改该数据,进而产生阻塞,读数据和写数据会相互阻塞。
乐观锁:
乐观锁假定系统的数据修改只会产生非常少的冲突,也就是说任何进程都不大可能修改别的进程正在访问的数据。
乐观并发模式下,读数据和写数据之间不会发生冲突,只有写数据与写数据之间会发生冲突。即读数据不会产生阻塞,只有写数据才会产生阻塞
java 线程池
<interface>Executor
^
|
<interface>ExecutorService
^
|
AbstractExecutorService
^
|
ThreadPoolExecutor
1. Executor
它是"执行者"接口,它是来执行任务的。准确的说,Executor提供了execute()接口来执行已提交的 Runnable 任务的对象。Executor存在的目的是提供一种将"任务提交"与"任务如何运行"分离开来的机制。
它只包含一个函数接口:
2. ExecutorService
ExecutorService继承于Executor。它是"执行者服务"接口,它是为"执行者接口Executor"服务而存在的;准确的话,ExecutorService提供了"将任务提交给执行者的接口(submit方法)","让执行者执行任务(invokeAll, invokeAny方法)"的接口等等。
3. AbstractExecutorService
AbstractExecutorService是一个抽象类,它实现了ExecutorService接口。
AbstractExecutorService存在的目的是为ExecutorService中的函数接口提供了默认实现。
4. ThreadPoolExecutor
ThreadPoolExecutor就是大名鼎鼎的"线程池"。它继承于AbstractExecutorService抽象类
5. ScheduledExecutorService
ScheduledExecutorService是一个接口,它继承于于ExecutorService。它相当于提供了"延时"和"周期执行"功能的ExecutorService。
ScheduledExecutorService提供了相应的函数接口,可以安排任务在给定的延迟后执行,也可以让任务周期的执行。
6. ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承于ThreadPoolExecutor,并且实现了ScheduledExecutorService接口。它相当于提供了"延时"和"周期执行"功能的ScheduledExecutorService。
ScheduledThreadPoolExecutor类似于Timer,但是在高并发程序中,ScheduledThreadPoolExecutor的性能要优于Timer。
7. Executors
Executors是个静态工厂类。它通过静态工厂方法返回ExecutorService、ScheduledExecutorService、ThreadFactory 和 Callable 等类的对象。
// 返回 Callable 对象,调用它时可运行给定特权的操作并返回其结果。
static Callable<Object> callable(PrivilegedAction<?> action)
// 返回 Callable 对象,调用它时可运行给定特权的异常操作并返回其结果。
static Callable<Object> callable(PrivilegedExceptionAction<?> action)
// 返回 Callable 对象,调用它时可运行给定的任务并返回 null。
static Callable<Object> callable(Runnable task)
// 返回 Callable 对象,调用它时可运行给定的任务并返回给定的结果。
static <T> Callable<T> callable(Runnable task, T result)
// 返回用于创建新线程的默认线程工厂。
static ThreadFactory defaultThreadFactory()
// 创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们。
static ExecutorService newCachedThreadPool()
// 创建一个可根据需要创建新线程的线程池,但是在以前构造的线程可用时将重用它们,并在需要时使用提供的 ThreadFactory 创建新线程。
static ExecutorService newCachedThreadPool(ThreadFactory threadFactory)
// 创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。
static ExecutorService newFixedThreadPool(int nThreads)
// 创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程,在需要时使用提供的 ThreadFactory 创建新线程。
static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory)
// 创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
// 创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
static ScheduledExecutorService newScheduledThreadPool(int corePoolSize, ThreadFactory threadFactory)
// 创建一个使用单个 worker 线程的 Executor,以无界队列方式来运行该线程。
static ExecutorService newSingleThreadExecutor()
// 创建一个使用单个 worker 线程的 Executor,以无界队列方式来运行该线程,并在需要时使用提供的 ThreadFactory 创建新线程。
static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory)
// 创建一个单线程执行程序,它可安排在给定延迟后运行命令或者定期地执行。
static ScheduledExecutorService newSingleThreadScheduledExecutor()
// 创建一个单线程执行程序,它可安排在给定延迟后运行命令或者定期地执行。
static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory)
// 返回 Callable 对象,调用它时可在当前的访问控制上下文中执行给定的 callable 对象。
static <T> Callable<T> privilegedCallable(Callable<T> callable)
// 返回 Callable 对象,调用它时可在当前的访问控制上下文中,使用当前上下文类加载器作为上下文类加载器来执行给定的 callable 对象。
static <T> Callable<T> privilegedCallableUsingCurrentClassLoader(Callable<T> callable)
// 返回用于创建新线程的线程工厂,这些新线程与当前线程具有相同的权限。
static ThreadFactory privilegedThreadFactory()
// 返回一个将所有已定义的 ExecutorService 方法委托给指定执行程序的对象,但是使用强制转换可能无法访问其他方法。
static ExecutorService unconfigurableExecutorService(ExecutorService executor)
// 返回一个将所有已定义的 ExecutorService 方法委托给指定执行程序的对象,但是使用强制转换可能无法访问其他方法。
static ScheduledExecutorService unconfigurableScheduledExecutorService(ScheduledExecutorService executor)
String, StringBuffer, StringBuilder 的区别是什么?String为什么是不可变的?
答:
1、String是字符串常量,StringBuffer和StringBuilder都是字符串变量。后两者的字符内容可变,而前者创建后内容不可变。
2、String不可变是因为在JDK中String类被声明为一个final类。
3、StringBuffer是线程安全的,而StringBuilder是非线程安全的。
ps:线程安全会带来额外的系统开销,所以StringBuilder的效率比StringBuffer高。
如果对系统中的线程是否安全很掌握,可用StringBuffer,在线程不安全处加上关键字Synchronize。
集合相关面试分析
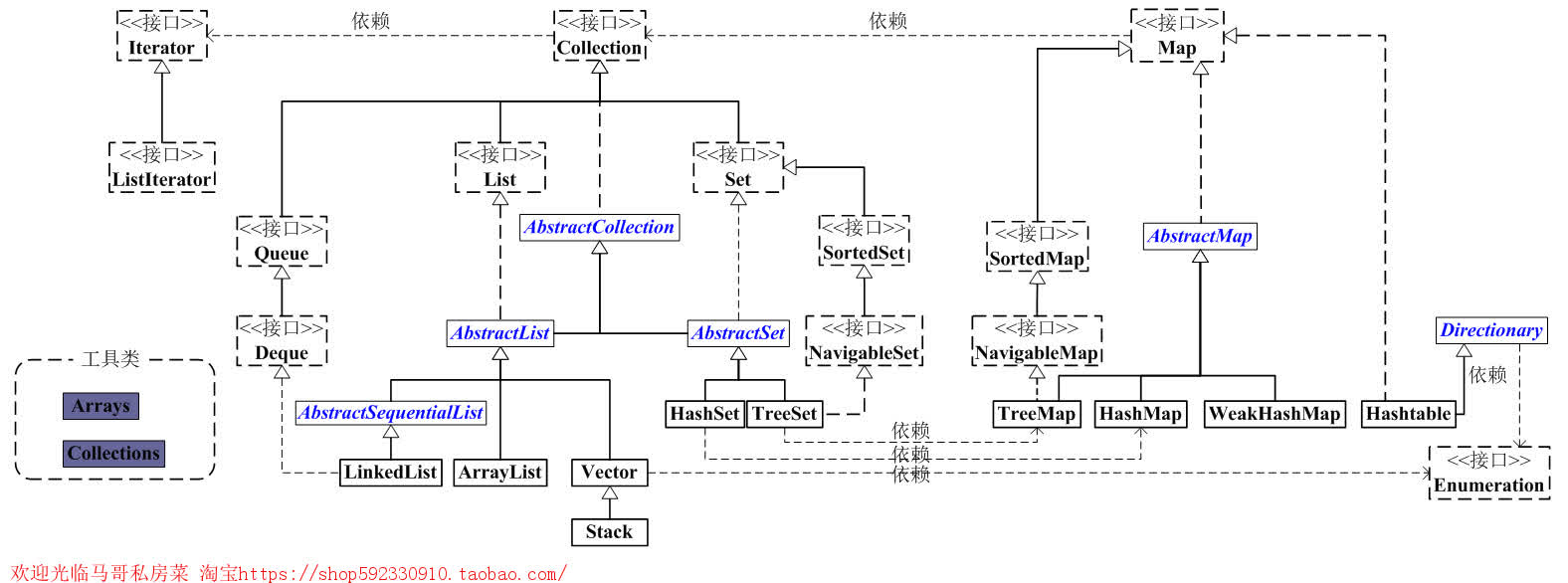
Java集合是java提供的工具包,包含了常用的数据结构:集合、链表、队列、栈、数组、映射等。Java集合工具包位置是java.util.*
Java集合主要可以划分为4个部分:List列表、Set集合、Map映射、工具类(Iterator迭代器、Enumeration枚举类、Arrays和Collections)、。
java集合分为两类,collection 和 map 两种,两种是并列的。
collection 存的值。
set 存储无序的不可重复的数据
HashSet 里面其实是用的HashMap来实现的 (添加的自定义类的对象需要这个类重写equals和hashCode方法)
LinkedHashSet 存储是按照哈希值无序存放的,遍历的时候可以按照顺序依次遍历。
TreeSet (自然排序Comparable接口和定制排序)
list 存储有序的,可以重复的数据,动态数组(ArrayList, LinkedList, Vector)
ArrayList 线程不安全的
LinkedList 对于频繁的插入,和删除操作建议使用这个
Vector 线程安全的
map存 键和值。
HashMap
LinkedHashMap
HashTable
Arrays和Collections。它们是操作数组、集合的两个工具类。ArrayList遍历方式
(01) 第一种,通过迭代器遍历。即通过Iterator去遍历。
Integer value = null;
Iterator iter = list.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}
(02) 第二种,随机访问,通过索引值去遍历。
Integer value = null;
int size = list.size();
for (int i=0; i<size; i++) {
value = (Integer)list.get(i);
}
(03) 第三种,for循环遍历。如下:
Integer value = null;
for (Integer integ:list) {
value = integ;
}
遍历ArrayList时,使用随机访问(即,通过索引序号访问)效率最高,而使用迭代器的效率最低!
LinkedList遍历方式
(01) 第一种,通过迭代器遍历。即通过Iterator去遍历。
for(Iterator iter = list.iterator(); iter.hasNext();)
iter.next();
(02) 通过快速随机访问遍历LinkedList
int size = list.size();
for (int i=0; i<size; i++) {
list.get(i);
}
(03) 通过另外一种for循环来遍历LinkedList
for (Integer integ:list)
;
(04) 通过pollFirst()来遍历LinkedList
while(list.pollFirst() != null)
;
(05) 通过pollLast()来遍历LinkedList
while(list.pollLast() != null)
;
(06) 通过removeFirst()来遍历LinkedList
try {
while(list.removeFirst() != null)
;
} catch (NoSuchElementException e) {
}
(07) 通过removeLast()来遍历LinkedList
try {
while(list.removeLast() != null)
;
} catch (NoSuchElementException e) {
}
由此可见,遍历LinkedList时,使用removeFist()或removeLast()效率最高。但用它们遍历时,会删除原始数据;若单纯只读取,而不删除,应该使用第3种遍历方式。
无论如何,千万不要通过随机访问去遍历LinkedList!
Vector遍历方式
(01) 第一种,通过迭代器遍历。即通过Iterator去遍历。
Integer value = null;
int size = vec.size();
for (int i=0; i<size; i++) {
value = (Integer)vec.get(i);
}
(02) 第二种,随机访问,通过索引值去遍历。
Integer value = null;
int size = vec.size();
for (int i=0; i<size; i++) {
value = (Integer)vec.get(i);
}
(03) 第三种,另一种for循环。如下:
Integer value = null;
for (Integer integ:vec) {
value = integ;
}
(04) 第四种,Enumeration遍历。如下:
Integer value = null;
Enumeration enu = vec.elements();
while (enu.hasMoreElements()) {
value = (Integer)enu.nextElement();
}
总结:遍历Vector,使用索引的随机访问方式最快,使用迭代器最慢。
索引变量 > 增强for循环 > Enumeration遍历 > 迭代器遍历
Comparable可以认为是一个内比较器,实现了Comparable接口的类有一个特点,就是这些类是可以和自己比较的,
至于具体和另一个实现了Comparable接口的类如何比较,则依赖compareTo方法的实现,compareTo方法也被称为自然比较方法。
如果开发者add进入一个Collection的对象想要Collections的sort方法帮你自动进行排序的话,那么这个对象必须实现Comparable接口。
compareTo方法的返回值是int,有三种情况:
1、比较者大于被比较者(也就是compareTo方法里面的对象),那么返回正整数
2、比较者等于被比较者,那么返回0
3、比较者小于被比较者,那么返回负整数
接口所在包 java.lang.Comparable
排序方法 int compareTo(T o);
触发排序 Collections.sort(List)
Comparator可以认为是是一个外比较器,个人认为有两种情况可以使用实现Comparator接口的方式:
1、一个对象不支持自己和自己比较(没有实现Comparable接口),但是又想对两个对象进行比较
2、一个对象实现了Comparable接口,但是开发者认为compareTo方法中的比较方式并不是自己想要的那种比较方式
Comparator接口里面有一个compare方法,方法有两个参数T o1和T o2,是泛型的表示方式,分别表示待比较的两个对象,方法返回值和Comparable接口一样是int,
有三种情况:
1、o1大于o2,返回正整数
2、o1等于o2,返回0
3、o1小于o3,返回负整数
接口所在包 java.util.Comparator
排序方法 int compare(T o1, T o2);
触发排序 Collections.sort(List, Comparator)Vector, ArrayList, LinkedList 的区别是什么?
1、Vector、ArrayList都是以类似数组的形式存储在内存中,LinkedList则以双向链表的形式进行存储。
Vector、ArrayList都是list接口的实现类,也都继承了AbstractList类。
2、List中的元素有序、允许有重复的元素,Set中的元素无序、不允许有重复元素。
3、Vector线程同步,其中有些方法是带synchronized关键字的,ArrayList、LinkedList线程不同步。
4、LinkedList适合指定位置插入、删除操作,不适合查找;ArrayList、Vector适合查找,不适合指定位置的插入、删除操作。
5、ArrayList在元素填满容器时会自动扩充容器大小的50%,而Vector则是100%,因此ArrayList更节省空间。
List l = new ArrayList();
jdk8当中在添加第一个元素的时候才去创建底层的那个数组,jdk7一开始就创建一个默认长度10的数组。
(01) List 是一个接口,它继承于Collection的接口。它代表着有序的队列。
(02) AbstractList 是一个抽象类,它继承于AbstractCollection。AbstractList实现List接口中除size()、get(int location)之外的函数。
(03) AbstractSequentialList 是一个抽象类,它继承于AbstractList。AbstractSequentialList 实现了“链表中,根据index索引值操作链表的全部函数”。
(04) ArrayList, LinkedList, Vector, Stack是List的4个实现类。
ArrayList 是一个数组队列,相当于动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低。
LinkedList 是一个双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率低。
Vector 是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
Stack 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。
HashTable, HashMap,TreeMap 区别?
HashTable存储数据是用的的这个:transient Entry<?,?>[] table
HashMap存储数据是用的的这个:transient Node<K,V>[] table;
1、HashTable线程同步,HashMap非线程同步。
2、HashTable不允许<键,值>有空值,HashMap允许<键,值>有空值。
3、HashTable使用Enumeration,HashMap使用Iterator。
4、HashTable中hash数组的默认大小是11,增加方式的old*2+1,HashMap中hash数组的默认大小是16,增长方式一定是2的指数倍。
5、TreeMap能够把它保存的记录根据键排序,默认是按升序排序。适用于按自然顺序或自定义顺序遍历键(key)
Map主要用于存储健值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允许值重复。
Hashmap 是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。
HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。
如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
Hashtable与 HashMap类似,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空;它支持线程的同步,
即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.
也可以在构造时用带参数,按照应用次数排序。
在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢,
因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
一般情况下,我们用的最多的是HashMap,在Map 中插入、删除和定位元素,HashMap 是最好的选择。
但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现,它还可以按读取顺序来排列.
hashMap使用array和list俩表示,根据键的hashcode来计算在数组中哪个位置存放数据,然后在数据存放到list中。
当数据量很大的时候,会把list转为红黑树来存放的(此数组i位置上的链表元素个数大于8且整个数组长度大于64才使用红黑树)。HashMap遍历方式
遍历HashMap的键值对
第一步:根据entrySet()获取HashMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
Integer integ = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
key = (String)entry.getKey();// 获取key
integ = (Integer)entry.getValue();// 获取value
}
遍历HashMap的键
第一步:根据keySet()获取HashMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
String key = null;
Integer integ = null;
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
key = (String)iter.next(); // 获取key
integ = (Integer)map.get(key);// 根据key,获取value
}
遍历HashMap的值
第一步:根据value()获取HashMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
// 假设map是HashMap对象
// map中的key是String类型,value是Integer类型
Integer value = null;
Collection c = map.values();
Iterator iter= c.iterator();
while (iter.hasNext()) {
value = (Integer)iter.next();
}
Hashtable遍历方式
通过Enumeration遍历Hashtable的键
第一步:根据keys()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
Enumeration enu = table.keys();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
通过Enumeration遍历Hashtable的值
第一步:根据elements()获取Hashtable的集合。
第二步:通过Enumeration遍历“第一步”得到的集合。
Enumeration enu = table.elements();
while(enu.hasMoreElements()) {
System.out.println(enu.nextElement());
}
java异常简介及其架构
Java异常机制可以使程序中异常处理代码和正常业务代码分离,保证程序代码更加优雅,并提高程序健壮性。
在有效使用异常的情况下,异常能清晰的回答what, where, why这3个问题:异常类型回答了“什么”被抛出,
异常堆栈跟踪回答了“在哪“抛出,异常信息回答了“为什么“会抛出。
Java异常机制用到的几个关键字:try、catch、finally、throw、throws。
• try -- 用于监听。将要被监听的代码(可能抛出异常的代码)放在try语句块之内,当try语句块内发生异常时,异常就被抛出。
• catch -- 用于捕获异常。catch用来捕获try语句块中发生的异常。
• finally -- finally语句块总是会被执行。它主要用于回收在try块里打开的物力资源(如数据库连接、网络连接和磁盘文件)。
只有finally块,执行完成之后,才会回来执行try或者catch块中的return或者throw语句,如果finally中使用了return或者throw等终止方法的语句,则就不会跳回执行,直接停止。
• throw -- 用于抛出异常。
• throws -- 用在方法签名中,用于声明该方法可能抛出的异常。
1. Throwable
Throwable是 Java 语言中所有错误或异常的超类。
Throwable包含两个子类: Error 和 Exception。它们通常用于指示发生了异常情况。
Throwable包含了其线程创建时线程执行堆栈的快照,它提供了printStackTrace()等接口用于获取堆栈跟踪数据等信息。
2. Exception
Exception及其子类是 Throwable 的一种形式,它指出了合理的应用程序想要捕获的条件。
3. RuntimeException
RuntimeException是那些可能在 Java 虚拟机正常运行期间抛出的异常的超类。
编译器不会检查RuntimeException异常。例如,除数为零时,抛出ArithmeticException异常。RuntimeException是ArithmeticException的超类。当代码发生除数为零的情况时,倘若既"没有通过throws声明抛出ArithmeticException异常",也"没有通过try...catch...处理该异常",也能通过编译。这就是我们所说的"编译器不会检查RuntimeException异常"!
如果代码会产生RuntimeException异常,则需要通过修改代码进行避免。例如,若会发生除数为零的情况,则需要通过代码避免该情况的发生!
4. Error
和Exception一样,Error也是Throwable的子类。它用于指示合理的应用程序不应该试图捕获的严重问题,大多数这样的错误都是异常条件。
和RuntimeException一样,编译器也不会检查Error。
Java将可抛出(Throwable)的结构分为三种类型:被检查的异常(Checked Exception),运行时异常(RuntimeException)和错误(Error)。
(01) 运行时异常
定义: RuntimeException及其子类都被称为运行时异常。
特点: Java编译器不会检查它。也就是说,当程序中可能出现这类异常时,倘若既"没有通过throws声明抛出它",也"没有用try-catch语句捕获它",还是会编译通过。例如,除数为零时产生的ArithmeticException异常,数组越界时产生的IndexOutOfBoundsException异常,fail-fail机制产生的ConcurrentModificationException异常等,都属于运行时异常。
虽然Java编译器不会检查运行时异常,但是我们也可以通过throws进行声明抛出,也可以通过try-catch对它进行捕获处理。
如果产生运行时异常,则需要通过修改代码来进行避免。例如,若会发生除数为零的情况,则需要通过代码避免该情况的发生!
(02) 被检查的异常
定义: Exception类本身,以及Exception的子类中除了"运行时异常"之外的其它子类都属于被检查异常。
特点: Java编译器会检查它。此类异常,要么通过throws进行声明抛出,要么通过try-catch进行捕获处理,否则不能通过编译。例如,CloneNotSupportedException就属于被检查异常。当通过clone()接口去克隆一个对象,而该对象对应的类没有实现Cloneable接口,就会抛出CloneNotSupportedException异常。
被检查异常通常都是可以恢复的。
(03) 错误
定义: Error类及其子类。
特点: 和运行时异常一样,编译器也不会对错误进行检查。
当资源不足、约束失败、或是其它程序无法继续运行的条件发生时,就产生错误。程序本身无法修复这些错误的。例如,VirtualMachineError就属于错误。
按照Java惯例,我们是不应该是实现任何新的Error子类的!
对于上面的3种结构,我们在抛出异常或错误时,到底该哪一种?《Effective Java》中给出的建议是:对于可以恢复的条件使用被检查异常,对于程序错误使用运行时异常。
JUC原子类
根据修改的数据类型,可以将JUC包中的原子操作类可以分为4类。
1. 基本类型: AtomicInteger, AtomicLong, AtomicBoolean ;
2. 数组类型: AtomicIntegerArray, AtomicLongArray, AtomicReferenceArray ;
3. 引用类型: AtomicReference, AtomicStampedRerence, AtomicMarkableReference ;
4. 对象的属性修改类型: AtomicIntegerFieldUpdater, AtomicLongFieldUpdater, AtomicReferenceFieldUpdater 。
这些类存在的目的是对相应的数据进行原子操作。所谓原子操作,是指操作过程不会被中断,保证数据操作是以原子方式进行的。
AtomicLong 是作用是对长整形进行原子操作。
在32位操作系统中,64位的long 和 double 变量由于会被JVM当作两个分离的32位来进行操作,所以不具有原子性。而使用AtomicLong能让long的操作保持原子型。
同步锁
即通过synchronized关键字来进行同步,实现对竞争资源的互斥访问的锁。Java 1.0版本中就已经支持同步锁了。
同步锁的原理是,对于每一个对象,有且仅有一个同步锁;不同的线程能共同访问该同步锁。但是,在同一个时间点,该同步锁能且只能被一个线程获取到。
这样,获取到同步锁的线程就能进行CPU调度,从而在CPU上执行;而没有获取到同步锁的线程,必须进行等待,直到获取到同步锁之后才能继续运行。
这就是,多线程通过同步锁进行同步的原理!
JUC包中的锁
相比同步锁,JUC包中的锁的功能更加强大,它为锁提供了一个框架,该框架允许更灵活地使用锁,只是它的用法更难罢了。
JUC包中的锁,包括:Lock接口,ReadWriteLock接口,LockSupport阻塞原语,Condition条件,
AbstractOwnableSynchronizer/AbstractQueuedSynchronizer/AbstractQueuedLongSynchronizer三个抽象类,
ReentrantLock独占锁,ReentrantReadWriteLock读写锁。
由于CountDownLatch,CyclicBarrier和Semaphore也是通过AQS来实现的
01. Lock接口
JUC包中的 Lock 接口支持那些语义不同(重入、公平等)的锁规则。所谓语义不同,是指锁可是有"公平机制的锁"、"非公平机制的锁"、"可重入的锁"等等。
"公平机制"是指"不同线程获取锁的机制是公平的",而"非公平机制"则是指"不同线程获取锁的机制是非公平的","可重入的锁"是指同一个锁能够被一个线程多次获取。
02. ReadWriteLock
ReadWriteLock 接口以和Lock类似的方式定义了一些读取者可以共享而写入者独占的锁。JUC包只有一个类实现了该接口,
即 ReentrantReadWriteLock,因为它适用于大部分的标准用法上下文。但程序员可以创建自己的、适用于非标准要求的实现。
03. AbstractOwnableSynchronizer/AbstractQueuedSynchronizer/AbstractQueuedLongSynchronizer
AbstractQueuedSynchronizer就是被称之为AQS的类,它是一个非常有用的超类,可用来定义锁以及依赖于排队阻塞线程的其他同步器;
ReentrantLock,ReentrantReadWriteLock,CountDownLatch,CyclicBarrier和Semaphore等这些类都是基于AQS类实现的。
AbstractQueuedLongSynchronizer 类提供相同的功能但扩展了对同步状态的 64 位的支持。
两者都扩展了类 AbstractOwnableSynchronizer(一个帮助记录当前保持独占同步的线程的简单类)。
04. LockSupport
LockSupport提供“创建锁”和“其他同步类的基本线程阻塞原语”。
LockSupport的功能和"Thread中的Thread.suspend()和Thread.resume()有点类似",LockSupport中的park()
和 unpark() 的作用分别是阻塞线程和解除阻塞线程。但是park()和unpark()不会遇到“Thread.suspend 和 Thread.resume所可能引发的死锁”问题。
05. Condition
Condition需要和Lock联合使用,它的作用是代替Object监视器方法,可以通过await(),signal()来休眠/唤醒线程。
Condition 接口描述了可能会与锁有关联的条件变量。这些变量在用法上与使用 Object.wait 访问的隐式监视器类似,
但提供了更强大的功能。需要特别指出的是,单个 Lock 可能与多个 Condition 对象关联。为了避免兼容性问题,Condition 方法的名称与对应的 Object 版本中的不同。
06. ReentrantLock
ReentrantLock是独占锁。所谓独占锁,是指只能被独自占领,即同一个时间点只能被一个线程锁获取到的锁。
ReentrantLock锁包括"公平的ReentrantLock"和"非公平的ReentrantLock"。"公平的ReentrantLock"是指
"不同线程获取锁的机制是公平的",而"非公平的ReentrantLock"则是指"不同线程获取锁的机制是非公平的",ReentrantLock是"可重入的锁"。
(01) ReentrantLock实现了Lock接口。
(02) ReentrantLock中有一个成员变量sync,sync是Sync类型;Sync是一个抽象类,而且它继承于AQS。
(03) ReentrantLock中有"公平锁类"FairSync和"非公平锁类"NonfairSync,它们都是Sync的子类。
ReentrantReadWriteLock中sync对象,是FairSync与NonfairSync中的一种,这也意味着ReentrantLock是"公平锁"或"非公平锁"中的一种,ReentrantLock默认是非公平锁。
07. ReentrantReadWriteLock
ReentrantReadWriteLock是读写锁接口ReadWriteLock的实现类,它包括子类ReadLock和WriteLock。ReentrantLock是共享锁,而WriteLock是独占锁。
(01) ReentrantReadWriteLock实现了ReadWriteLock接口。
(02) ReentrantReadWriteLock中包含sync对象,读锁readerLock和写锁writerLock。读锁ReadLock和写锁WriteLock都实现了Lock接口。
(03) 和"ReentrantLock"一样,sync是Sync类型;而且,Sync也是一个继承于AQS的抽象类。Sync也包括"公平锁"FairSync和"非公平锁"NonfairSync。
08. CountDownLatch
CountDownLatch是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它允许一个或多个线程一直等待。
CountDownLatch包含了sync对象,sync是Sync类型。CountDownLatch的Sync是实例类,它继承于AQS。
09. CyclicBarrier
CyclicBarrier是一个同步辅助类,允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。
因为该 barrier 在释放等待线程后可以重用,所以称它为循环 的 barrier。
CyclicBarrier是包含了"ReentrantLock对象lock"和"Condition对象trip",它是通过独占锁实现的。
CyclicBarrier和CountDownLatch的区别是:
(01) CountDownLatch的作用是允许1或N个线程等待其他线程完成执行;而CyclicBarrier则是允许N个线程相互等待。
(02) CountDownLatch的计数器无法被重置;CyclicBarrier的计数器可以被重置后使用,因此它被称为是循环的barrier。
10. Semaphore
Semaphore是一个计数信号量,它的本质是一个"共享锁"。
信号量维护了一个信号量许可集。线程可以通过调用acquire()来获取信号量的许可;当信号量中有可用的许可时,线程能获取该许可;否则线程必须等待,直到有可用的许可为止。 线程可以通过release()来释放它所持有的信号量许可。
和"ReentrantLock"一样,Semaphore包含了sync对象,sync是Sync类型;而且,Sync也是一个继承于AQS的抽象类。Sync也包括"公平信号量"FairSync和"非公平信号量"NonfairSync。
JUC中的集合类
1. List和Set
JUC集合包中的List和Set实现类包括: CopyOnWriteArrayList, CopyOnWriteArraySet和ConcurrentSkipListSet。
(01) CopyOnWriteArrayList相当于线程安全的ArrayList,它实现了List接口。CopyOnWriteArrayList是支持高并发的。
(02) CopyOnWriteArraySet相当于线程安全的HashSet,它继承于AbstractSet类。CopyOnWriteArraySet内部包含一个CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。
2. Map
JUC集合包中Map的实现类包括: ConcurrentHashMap和ConcurrentSkipListMap。
(01) ConcurrentHashMap是线程安全的哈希表(相当于线程安全的HashMap);它继承于AbstractMap类,
并且实现ConcurrentMap接口。ConcurrentHashMap是通过“锁分段”来实现的,它支持并发。
(02) ConcurrentSkipListMap是线程安全的有序的哈希表(相当于线程安全的TreeMap); 它继承于AbstractMap类,并且实现ConcurrentNavigableMap接口。
ConcurrentSkipListMap是通过“跳表”来实现的,它支持并发。
(03) ConcurrentSkipListSet是线程安全的有序的集合(相当于线程安全的TreeSet);它继承于AbstractSet,
并实现了NavigableSet接口。ConcurrentSkipListSet是通过ConcurrentSkipListMap实现的,它也支持并发。
3. Queue
JUC集合包中Queue的实现类包括: ArrayBlockingQueue, LinkedBlockingQueue, LinkedBlockingDeque, ConcurrentLinkedQueue和ConcurrentLinkedDeque。
(01) ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列。
(02) LinkedBlockingQueue是单向链表实现的(指定大小)阻塞队列,该队列按 FIFO(先进先出)排序元素。
(03) LinkedBlockingDeque是双向链表实现的(指定大小)双向并发阻塞队列,该阻塞队列同时支持FIFO和FILO两种操作方式。
(04) ConcurrentLinkedQueue是单向链表实现的无界队列,该队列按 FIFO(先进先出)排序元素。
(05) ConcurrentLinkedDeque是双向链表实现的无界队列,该队列同时支持FIFO和FILO两种操作方式。
CopyOnWriteArrayList介绍
它相当于线程安全的ArrayList。和ArrayList一样,它是个可变数组;但是和ArrayList不同的时,它具有以下特性:
1. 它最适合于具有以下特征的应用程序:List 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
说明:
1. CopyOnWriteArrayList实现了List接口,因此它是一个队列。
2. CopyOnWriteArrayList包含了成员lock。每一个CopyOnWriteArrayList都和一个互斥锁lock绑定,通过lock,实现了对CopyOnWriteArrayList的互斥访问。
3. CopyOnWriteArrayList包含了成员array数组,这说明CopyOnWriteArrayList本质上通过数组实现的。
下面从“动态数组”和“线程安全”两个方面进一步对CopyOnWriteArrayList的原理进行说明。
1. CopyOnWriteArrayList的“动态数组”机制 -- 它内部有个“volatile数组”(array)来保持数据。在“添加/修改/删除”数据时,都会新建一个数组,并将更新后的数据拷贝到新建的数组中,最后再将该数组赋值给“volatile数组”。这就是它叫做CopyOnWriteArrayList的原因!CopyOnWriteArrayList就是通过这种方式实现的动态数组;不过正由于它在“添加/修改/删除”数据时,都会新建数组,所以涉及到修改数据的操作,CopyOnWriteArrayList效率很
低;但是单单只是进行遍历查找的话,效率比较高。
2. CopyOnWriteArrayList的“线程安全”机制 -- 是通过volatile和互斥锁来实现的。
(01) CopyOnWriteArrayList是通过“volatile数组”来保存数据的。一个线程读取volatile数组时,总能看到其它线程对该volatile变量最后的写入;
就这样,通过volatile提供了“读取到的数据总是最新的”这个机制的保证。
(02) CopyOnWriteArrayList通过互斥锁来保护数据。在“添加/修改/删除”数据时,会先“获取互斥锁”,再修改完毕之后,先将数据更新到“volatile数组”中,
然后再“释放互斥锁”;这样,就达到了保护数据的目的。
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
public CopyOnWriteArrayList(Collection<? extends E> c) {
Object[] elements = c.toArray();
if (elements.getClass() != Object[].class)
elements = Arrays.copyOf(elements, elements.length, Object[].class);
setArray(elements);
}
public CopyOnWriteArrayList(E[] toCopyIn) {
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
说明:这3个构造函数都调用了setArray(),setArray()的源码如下:
private volatile transient Object[] array;
final Object[] getArray() {
return array;
}
final void setArray(Object[] a) {
array = a;
}
说明:setArray()的作用是给array赋值;其中,array是volatile transient Object[]类型,即array是“volatile数组”。
关于volatile关键字,我们知道“volatile能让变量变得可见”,即对一个volatile变量的读,总是能看到(任意线程)对这个volatile变量最后的写入。
正在由于这种特性,每次更新了“volatile数组”之后,其它线程都能看到对它所做的更新。
关于transient关键字,它是在序列化中才起作用,transient变量不会被自动序列化。transient不是本文关注的重点,了解即可。
2. 添加
以add(E e)为例,来对“CopyOnWriteArrayList的添加操作”进行说明。下面是add(E e)的代码:
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 获取“锁”
lock.lock();
try {
// 获取原始”volatile数组“中的数据和数据长度。
Object[] elements = getArray();
int len = elements.length;
// 新建一个数组newElements,并将原始数据拷贝到newElements中;
// newElements数组的长度=“原始数组的长度”+1
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 将“新增加的元素”保存到newElements中。
newElements[len] = e;
// 将newElements赋值给”volatile数组“。
setArray(newElements);
return true;
} finally {
// 释放“锁”
lock.unlock();
}
}
说明:
add(E e)的作用就是将数据e添加到”volatile数组“中。它的实现方式是,新建一个数组,接着将原始的”volatile数组“的数据拷贝到新数组中,
然后将新增数据也添加到新数组中;最后,将新数组赋值给”volatile数组“。
在add(E e)中有两点需要关注。
第一,在”添加操作“开始前,获取独占锁(lock),若此时有需要线程要获取锁,则必须等待;在操作完毕后,释放独占锁(lock),
此时其它线程才能获取锁。通过独占锁,来防止多线程同时修改数据!lock的定义如下:
transient final ReentrantLock lock = new ReentrantLock();
第二,操作完毕时,会通过setArray()来更新”volatile数组“。而且,前面我们提过”即对一个volatile变量的读,
总是能看到(任意线程)对这个volatile变量最后的写入“;这样,每次添加元素之后,其它线程都能看到新添加的元素。
3. 获取
以get(int index)为例,来对“CopyOnWriteArrayList的删除操作”进行说明。下面是get(int index)的代码:
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
说明:get(int index)的实现很简单,就是返回”volatile数组“中的第index个元素。
4. 删除
以remove(int index)为例,来对“CopyOnWriteArrayList的删除操作”进行说明。下面是remove(int index)的代码:
public E remove(int index) {
final ReentrantLock lock = this.lock;
// 获取“锁”
lock.lock();
try {
// 获取原始”volatile数组“中的数据和数据长度。
Object[] elements = getArray();
int len = elements.length;
// 获取elements数组中的第index个数据。
E oldValue = get(elements, index);
int numMoved = len - index - 1;
// 如果被删除的是最后一个元素,则直接通过Arrays.copyOf()进行处理,而不需要新建数组。
// 否则,新建数组,然后将”volatile数组中被删除元素之外的其它元素“拷贝到新数组中;最后,将新数组赋值给”volatile数组“。
if (numMoved == 0)
setArray(Arrays.copyOf(elements, len - 1));
else {
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
// 释放“锁”
lock.unlock();
}
}
说明:remove(int index)的作用就是将”volatile数组“中第index个元素删除。它的实现方式是,如果被删除的是最后一个元素,则直接通过Arrays.copyOf()进行处理,而不需要新建数组。否则,新建数组,然后将”volatile数组中被删除元素之外的其它元素“拷贝到新数组中;最后,将新数组赋值给”volatile数组“。
和add(E e)一样,remove(int index)也是”在操作之前,获取独占锁;操作完成之后,释放独占是“;并且”在操作完成时,会通过将数据更新到volatile数组中“。
5. 遍历
以iterator()为例,来对“CopyOnWriteArrayList的遍历操作”进行说明。下面是iterator()的代码:
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
说明:iterator()会返回COWIterator对象。
COWIterator实现额ListIterator接口,它的源码如下:
说明:COWIterator不支持修改元素的操作。例如,对于remove(),set(),add()等操作,COWIterator都会抛出异常!
另外,需要提到的一点是,CopyOnWriteArrayList返回迭代器不会抛出ConcurrentModificationException异常,即它不是fail-fast机制的!
CopyOnWriteArraySet介绍
它是线程安全的无序的集合,可以将它理解成线程安全的HashSet。有意思的是,CopyOnWriteArraySet和HashSet虽然都继承于共同的父类AbstractSet;
但是,HashSet是通过“散列表(HashMap)”实现的,而CopyOnWriteArraySet则是通过“动态数组(CopyOnWriteArrayList)”实现的,并不是散列表。
和CopyOnWriteArrayList类似,CopyOnWriteArraySet具有以下特性:
1. 它最适合于具有以下特征的应用程序:Set 大小通常保持很小,只读操作远多于可变操作,需要在遍历期间防止线程间的冲突。
2. 它是线程安全的。
3. 因为通常需要复制整个基础数组,所以可变操作(add()、set() 和 remove() 等等)的开销很大。
4. 迭代器支持hasNext(), next()等不可变操作,但不支持可变 remove()等 操作。
5. 使用迭代器进行遍历的速度很快,并且不会与其他线程发生冲突。在构造迭代器时,迭代器依赖于不变的数组快照。
说明:
1. CopyOnWriteArraySet继承于AbstractSet,这就意味着它是一个集合。
2. CopyOnWriteArraySet包含CopyOnWriteArrayList对象,它是通过CopyOnWriteArrayList实现的。而CopyOnWriteArrayList本质是个动态数组队列,
所以CopyOnWriteArraySet相当于通过通过动态数组实现的“集合”! CopyOnWriteArrayList中允许有重复的元素;
但是,CopyOnWriteArraySet是一个集合,所以它不能有重复集合。因此,CopyOnWriteArrayList额外提供了addIfAbsent()和addAllAbsent()这两个添加元素的API,
通过这些API来添加元素时,只有当元素不存在时才执行添加操作!
至于CopyOnWriteArraySet的“线程安全”机制,和CopyOnWriteArrayList一样,是通过volatile和互斥锁来实现的。
这个在前一章节介绍CopyOnWriteArrayList时数据结构时,已经进行了说明,这里就不再重复叙述了。ConcurrentHashMap介绍
ConcurrentHashMap是线程安全的哈希表。HashMap, Hashtable, ConcurrentHashMap之间的关联如下:
HashMap是非线程安全的哈希表,常用于单线程程序中。
Hashtable是线程安全的哈希表,它是通过synchronized来保证线程安全的;即,多线程通过同一个“对象的同步锁”来实现并发控制。
Hashtable在线程竞争激烈时,效率比较低(此时建议使用ConcurrentHashMap)!因为当一个线程访问Hashtable的同步方法时,其它线程就访问Hashtable的同步方法时,可能会进入阻塞状态。
ConcurrentHashMap是线程安全的哈希表,它是通过“锁分段”来保证线程安全的。ConcurrentHashMap将哈希表分成许多片段(Segment),
每一个片段除了保存哈希表之外,本质上也是一个“可重入的互斥锁”(ReentrantLock)。多线程对同一个片段的访问,是互斥的;但是,对于不同片段的访问,却是可以同步进行的。
(01) ConcurrentHashMap 继承于AbstractMap抽象类。
(02) Segment是ConcurrentHashMap中的内部类,它就是ConcurrentHashMap中的“锁分段”对应的存储结构。
ConcurrentHashMap与Segment是组合关系,1个ConcurrentHashMap对象包含若干个Segment对象。在代码中,这表现为ConcurrentHashMap类中存在“Segment数组”成员。
(03) Segment类继承于ReentrantLock类,所以Segment本质上是一个可重入的互斥锁。
(04) HashEntry也是ConcurrentHashMap的内部类,是单向链表节点,存储着key-value键值对。Segment与HashEntry是组合关系,Segment类中存在“HashEntry数组”成员,“HashEntry数组”中的每个HashEntry就是一个单向链表。
对于多线程访问对一个“哈希表对象”竞争资源,Hashtable是通过一把锁来控制并发;而ConcurrentHashMap则是将哈希表分成许多片段,
对于每一个片段分别通过一个互斥锁来控制并发。ConcurrentHashMap对并发的控制更加细腻,它也更加适应于高并发场景!
Java是如何实现跨平台的?
跨平台是怎样实现的呢?这就要谈及Java虚拟机(Java Virtual Machine,简称 JVM)。
JVM也是一个软件,不同的平台有不同的版本。我们编写的Java源码,编译后会生成一种 .class 文件,称为字节码文件。Java虚拟机就是负责将字节码文件翻译成特定平台下的机器码然后运行。也就是说,只要在不同平台上安装对应的JVM,就可以运行字节码文件,运行我们编写的Java程序。
而这个过程中,我们编写的Java程序没有做任何改变,仅仅是通过JVM这一”中间层“,就能在不同平台上运行,真正实现了”一次编译,到处运行“的目的。
JVM是一个”桥梁“,是一个”中间件“,是实现跨平台的关键,Java代码首先被编译成字节码文件,再由JVM将字节码文件翻译成机器语言,从而达到运行Java程序的目的。
注意:编译的结果不是生成机器码,而是生成字节码,字节码不能直接运行,必须通过JVM翻译成机器码才能运行。不同平台下编译生成的字节码是一样的,但是由JVM翻译成的机器码却不一样。
所以,运行Java程序必须有JVM的支持,因为编译的结果不是机器码,必须要经过JVM的再次翻译才能执行。即使你将Java程序打包成可执行文件(例如 .exe),仍然需要JVM的支持。
注意:跨平台的是Java程序,不是JVM。JVM是用C/C++开发的,是编译后的机器码,不能跨平台,不同平台下需要安装不同版本的JVM。
JVM内存模型
堆
你的Java程序中所分配的每一个对象都需要存储在内存里。堆是这些实例化的对象所存储的地方。是的——都怪new操作符,是它把你的Java堆都占满了的!
它由所有线程共享
当堆耗尽的时候,JVM会抛出java.lang.OutOfMemoryError 异常
堆的大小可以通过JVM选项-Xms和-Xmx来进行调整
堆被分为:
Eden区 —— 新对象或者生命周期很短的对象会存储在这个区域中,这个区的大小可以通过-XX:NewSize和-XX:MaxNewSize参数来调整。新生代GC(垃圾回收器)会清理这一区域。
Survivor区 —— 那些历经了Eden区的垃圾回收仍能存活下来的依旧存在引用的对象会待在这个区域。这个区的大小可以由JVM参数-XX:SurvivorRatio来进行调节。
老年代 —— 那些在历经了Eden区和Survivor区的多次GC后仍然存活下来的对象(当然了,是拜那些挥之不去的引用所赐)会存储在这个区里。
这个区会由一个特殊的垃圾回收器来负责。年老代中的对象的回收是由老年代的GC(major GC)来进行的。
方法区
也被称为非堆区域(在HotSpot JVM的实现当中)
它被分为两个主要的子区域
持久代 —— 这个区域会 存储包括类定义,结构,字段,方法(数据及代码)以及常量在内的类相关数据。
它可以通过-XX:PermSize及 -XX:MaxPermSize来进行调节。如果它的空间用完了,会导致java.lang.OutOfMemoryError: PermGen space的异常。
代码缓存——这个缓存区域是用来存储编译后的代码。编译后的代码就是本地代码(硬件相关的),它是由JIT(Just In Time)编译器生成的,这个编译器是Oracle HotSpot JVM所特有的。
JVM栈
和Java类中的方法密切相关
它会存储局部变量以及方法调用的中间结果及返回值
Java中的每个线程都有自己专属的栈,这个栈是别的线程无法访问的。
可以通过JVM选项-Xss来进行调整
本地栈
用于本地方法(非Java代码)
按线程分配
PC寄存器
特定线程的程序计数器
包含JVM正在执行的指令的地址(如果是本地方法的话它的值则未定义)Java中object常用方法
1、clone()
2、equals()
3、finalize()
4、getclass()
5、hashcode()
6、notify()
7、notifyAll()
8、toString()
单例模式
解法一:只适合单线程环境(不好)
public class Singleton {
private static Singleton instance=null;
private Singleton(){
}
public static Singleton getInstance(){
if(instance==null){
instance=new Singleton();
}
return instance;
}
}
注解:Singleton的静态属性instance中,只有instance为null的时候才创建一个实例,构造函数私有,确保每次都只创建一个,避免重复创建。
缺点:只在单线程的情况下正常运行,在多线程的情况下,就会出问题。例如:当两个线程同时运行到判断instance是否为空的if语句,并且instance确实没有创建好时,那么两个线程都会创建一个实例。
解法二:多线程的情况可以用。(懒汉式,不好)
public class Singleton {
private static Singleton instance=null;
private Singleton(){
}
public static synchronized Singleton getInstance(){
if(instance==null){
instance=new Singleton();
}
return instance;
}
}
注解:在解法一的基础上加上了同步锁,使得在多线程的情况下可以用。例如:当两个线程同时想创建实例,由于在一个时刻只有一个线程能得到同步锁,当第一个线程加上锁以后,第二个线程只能等待。第一个线程发现实例没有创建,创建之。第一个线程释放同步锁,第二个线程才可以加上同步锁,执行下面的代码。由于第一个线程已经创建了实例,所以第二个线程不需要创建实例。保证在多线程的环境下也只有一个实例。
缺点:每次通过getInstance方法得到singleton实例的时候都有一个试图去获取同步锁的过程。而众所周知,加锁是很耗时的。能避免则避免。
解法三:加同步锁时,前后两次判断实例是否存在(可行)
public class Singleton {
private static Singleton instance=null;
private Singleton(){
}
public static Singleton getInstance(){
if(instance==null){
synchronized(Singleton.class){
if(instance==null){
instance=new Singleton();
}
}
}
return instance;
}
}
注解:只有当instance为null时,需要获取同步锁,创建一次实例。当实例被创建,则无需试图加锁。
缺点:用双重if判断,复杂,容易出错。
解法四:饿汉式(建议使用)
public class Singleton {
private static Singleton instance=new Singleton();
private Singleton(){
}
public static Singleton getInstance(){
return instance;
}
}
注解:初试化静态的instance创建一次。如果我们在Singleton类里面写一个静态的方法不需要创建实例,它仍然会早早的创建一次实例。而降低内存的使用率。
缺点:没有lazy loading的效果,从而降低内存的使用率。
解法五:静态内部内。(建议使用)
public class Singleton {
private Singleton(){
}
private static class SingletonHolder{
private final static Singleton instance=new Singleton();
}
public static Singleton getInstance(){
return SingletonHolder.instance;
}
}
注解:定义一个私有的内部类,在第一次用这个嵌套类时,会创建一个实例。而类型为SingletonHolder的类,只有在Singleton.getInstance()中调用,由于私有的属性,他人无法使用SingleHolder,不调用Singleton.getInstance()就不会创建实例。
优点:达到了lazy loading的效果,即按需创建实例。
jvm垃圾回收原理
1. 引用计数(Reference Counting)
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。
垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
2. 标记-清除(Mark-Sweep)
此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,
第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
3. 复制(Copying)
此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,
把正在使用中的对象复制到另外一个区域中。次算法每次只处理正在使用中的对象,因此复制成本比较小,
同时复制过去以后还能进行相应的内存整理,不过出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
4. 标记-整理(Mark-Compact)
此算法结合了 “标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,
第二阶段遍历整个堆,清除未标记对象并且把存活对象 “压缩”到堆的其中一块,按顺序排放。
此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
5. 增量收集(Incremental Collecting)
实施垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。
6. 分代(Generational Collecting)
基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用
不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









