










🤟致敬读者
- 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉
📘博主相关
文章目录
📃文章前言
- 🔷文章均为学习工作中整理的笔记。
- 🔶如有错误请指正,共同学习进步。
一、直接使用代码
更详细内容请参考阿里云官网文档的python部分oss-python
import oss2
from itertools import islice
# 1 代码嵌入方式配置
# 填写RAM用户的访问密钥(AccessKey ID和AccessKey Secret)。
accessKeyId = 'yourAccessKeyId'
accessKeySecret = 'yourAccessKeySecret'
# 使用代码嵌入的RAM用户的访问密钥配置访问凭证。
auth = oss2.Auth(accessKeyId, accessKeySecret)
# endpoint填写Bucket所在地域对应的Endpoint。以华东1(杭州)为例,Endpoint填写为https://oss-cn-hangzhou.aliyuncs.com。
endpoint = 'http://oss-cn-shanghai.aliyuncs.com'
# 填写Bucket名称。
bucketName = 'z-libai-test'
bucket = oss2.Bucket(auth, endpoint, bucketName)
# 上传文件到OSS。
# objectName由包含文件后缀,不包含Bucket名称组成的Object完整路径,例如abc/efg/123.jpg。
objectName = '3_JWH/25_fileTest/test1.lab'
# localFile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt。
localFile = 'E:\\VSCodePros\\PYTHON\\OSS\\test001.txt'
bucket.put_object_from_file(objectName, localFile)
# 生成下载链接
fileLink = 'http://'+bucketName+'.oss-cn-shanghai.aliyuncs.com/'+objectName
print(fileLink)
#下载OSS文件到本地文件。
# objectName由包含文件后缀,不包含Bucket名称组成的Object完整路径,例如abc/efg/123.jpg。
# localFile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt。
bucket.get_object_to_file('yourObjectName', 'yourLocalFile')
# oss2.ObjectIterator用于遍历文件。列举10个文件
for b in islice(oss2.ObjectIterator(bucket), 10):
print(b.key)
# 列举Bucket下的所有文件。
for obj in oss2.ObjectIterator(bucket):
print(obj.key)
# 列举指定前缀的所有文件
# 列举fun文件夹下的所有文件,包括子目录下的文件。
for obj in oss2.ObjectIterator(bucket, prefix='fun/'):
print(obj.key)
# 列举指定起始位置后的所有文件
# 列举指定字符串之后的所有文件。即使存储空间中存在marker的同名object,返回结果中也不会包含这个object。
for obj in oss2.ObjectIterator(bucket, marker="x2.txt"):
print(obj.key)
# 列举指定目录下的文件和子目录
# 列举fun文件夹下的文件与子文件夹名称,不列举子文件夹下的文件。
for obj in oss2.ObjectIterator(bucket, prefix = 'fun/', delimiter = '/'):
# 通过is_prefix方法判断obj是否为文件夹。
if obj.is_prefix(): # 判断obj为文件夹。
print('directory: ' + obj.key)
else: # 判断obj为文件。
print('file: ' + obj.key)
# 获取指定目录下的文件大小
def CalculateFolderLength(bucket, folder):
length = 0
for obj in oss2.ObjectIterator(bucket, prefix=folder):
length += obj.size
return length
for obj in oss2.ObjectIterator(bucket, delimiter='/'):
if obj.is_prefix(): # 判断obj为文件夹。
length = CalculateFolderLength(bucket, obj.key)
print('directory: ' + obj.key + ' length:' + str(length) + "Byte.")
else: # 判断obj为文件。
print('file:' + obj.key + ' length:' + str(obj.size) + "Byte.")
二、详细使用
1. 环境准备
官方文档地址:
oss文档Python参考
1.1 Python环境
参考文章:https://blog.csdn.net/mo_sss/article/details/132449962
1.2 OSS的SDK安装
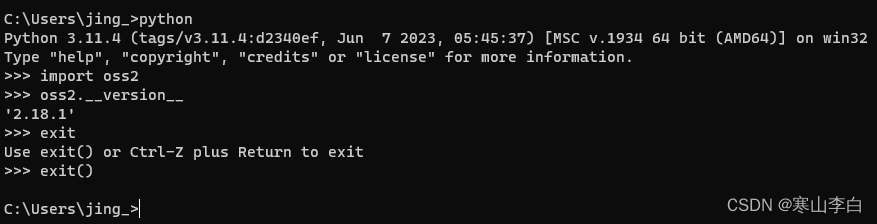
cmd窗口进入后执行命令安装oss的SDK
pip install oss2
执行
python
进入python环境
输入命令查看oss的SDK
import oss2
回车
oss2.__version__
回车
显示oss版本即可
exit()
退出
2. 初始化配置
配置访问凭证(连接oss的参数)
# -*- coding: utf-8 -*-
import oss2
# 填写RAM用户的访问密钥(AccessKey ID和AccessKey Secret)。
accessKeyId = 'yourAccessKeyId'
accessKeySecret = 'yourAccessKeySecret'
# 使用代码嵌入的RAM用户的访问密钥配置访问凭证。
auth = oss2.Auth(accessKeyId, accessKeySecret)
# yourEndpoint填写Bucket所在地域对应的Endpoint。以华东1(杭州)为例,Endpoint填写为https://oss-cn-hangzhou.aliyuncs.com。
endpoint = 'yourEndpoint'
3. bucket配置创建
# 填写Bucket名称。# yourBucketName填写存储空间名称。
bucket = oss2.Bucket(auth, endpoint, 'yourBucketName')
# 设置存储空间为私有读写权限。此步可省略
bucket.create_bucket(oss2.models.BUCKET_ACL_PRIVATE)
4. 文件上传到oss
# 上传文件到OSS。
# yourObjectName由包含文件后缀,不包含Bucket名称组成的Object完整路径,例如abc/efg/123.jpg。
# yourLocalFile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt。
bucket.put_object_from_file('yourObjectName', 'yourLocalFile')
5. oss文件链接生成
可通过链接直接下载文件
fileLink = 'http://'+'yourLocalFile'+'.oss-cn-shanghai.aliyuncs.com/'+'yourObjectName'
print(fileLink)
6. oss文件下载到本地
#下载OSS文件到本地文件。
# yourObjectName由包含文件后缀,不包含Bucket名称组成的Object完整路径,例如abc/efg/123.jpg。
# yourLocalFile由本地文件路径加文件名包括后缀组成,例如/users/local/myfile.txt。
bucket.get_object_to_file('yourObjectName', 'yourLocalFile')
7. 生成文件下载链接
# 生成下载链接
fileLink = 'http://'+bucketName+'.oss-cn-shanghai.aliyuncs.com/'+objectName
print(fileLink)
8. 列举oss文件(指定数量)
需引入islice
from itertools import islice
# oss2.ObjectIterator用于遍历文件。列举10个文件
for b in islice(oss2.ObjectIterator(bucket), 10):
print(b.key)
9. 列举oss文件(所有)
# 列举Bucket下的所有文件。
for obj in oss2.ObjectIterator(bucket):
print(obj.key)
10. 列举指定前缀的文件(所有)
# 列举指定前缀的所有文件
# 列举fun文件夹下的所有文件,包括子目录下的文件。
for obj in oss2.ObjectIterator(bucket, prefix='fun/'):
print(obj.key)
11. 列举指定起始位置的文件(所有)
# 列举指定起始位置后的所有文件
# 列举指定字符串之后的所有文件。即使存储空间中存在marker的同名object,返回结果中也不会包含这个object。
for obj in oss2.ObjectIterator(bucket, marker="x2.txt"):
print(obj.key)
12. 列举指定目录下的文件和子目录(所有)
# 列举指定目录下的文件和子目录
# 列举fun文件夹下的文件与子文件夹名称,不列举子文件夹下的文件。
for obj in oss2.ObjectIterator(bucket, prefix = 'fun/', delimiter = '/'):
# 通过is_prefix方法判断obj是否为文件夹。
if obj.is_prefix(): # 判断obj为文件夹。
print('directory: ' + obj.key)
else: # 判断obj为文件。
print('file: ' + obj.key)
13. 删除oss文件
# yourObjectName表示删除OSS文件时需要指定包含文件后缀,不包含Bucket名称在内的完整路径,例如abc/efg/123.jpg。
bucket.delete_object('yourObjectName')
14. 获取指定目录下的文件大小
def CalculateFolderLength(bucket, folder):
length = 0
for obj in oss2.ObjectIterator(bucket, prefix=folder):
length += obj.size
return length
for obj in oss2.ObjectIterator(bucket, delimiter='/'):
if obj.is_prefix(): # 判断obj为文件夹。
length = CalculateFolderLength(bucket, obj.key)
print('directory: ' + obj.key + ' length:' + str(length) + "Byte.")
else: # 判断obj为文件。
print('file:' + obj.key + ' length:' + str(obj.size) + "Byte.")
📜文末寄语
- 🟠关注我,获取更多内容。
- 🟡技术动态、实战教程、问题解决方案等内容持续更新中。
- 🟢《全栈知识库》技社区,集结全栈各领域开发者,期待你的加入。
- 🔵加入开发者的《专属社群》,分享交流,技术之路不再孤独,一起变强。
- 🟣点击下方名片获取更多内容🍭🍭🍭👇


















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









