







03.Python代码Pandas - DataFrame全系列分享(使用.特点.说明.取值.函数)
说明:帮帮志会陆续更新非常多的IT技术知识,希望分享的内容对您有用。本章分享的是pandas的使用语法。前后每一小节的内容是存在的有:学习and理解的关联性。【帮帮志系列文章】:每个知识点,都是写出代码和运行结果且前后关联上的去分析和说明(知识点不会跳跃),如果晦涩难懂会使用大白话帮助理解(能大量节约您的时间)。
所有文章都不会直接把代码放那里,让您自己去看去理解。我希望我的内容对您有用而努力~
python语法-pandas第三节 :DataFrame全系列分享(使用.特点.说明.取值.函数)
文章目录
DataFrame是什么
DataFrame 是一个表格型的数据结构,
有一组有序的列,其他每列可以是不同的值类型(数值、字符串、布尔型值)。
DataFrame 既有行索引(公共的)也有列索引(series的名字),它可以被看做由 若干的Series 组成的字典(每个Series 共同用一个索引)
大白话:一张数据表格就是DataFrame(DataFrame 它本来也是表格型的数据结构) 。有序的列就是这个表格的索引,其他的就是数据,其他的列是Series 组成的
长这样:
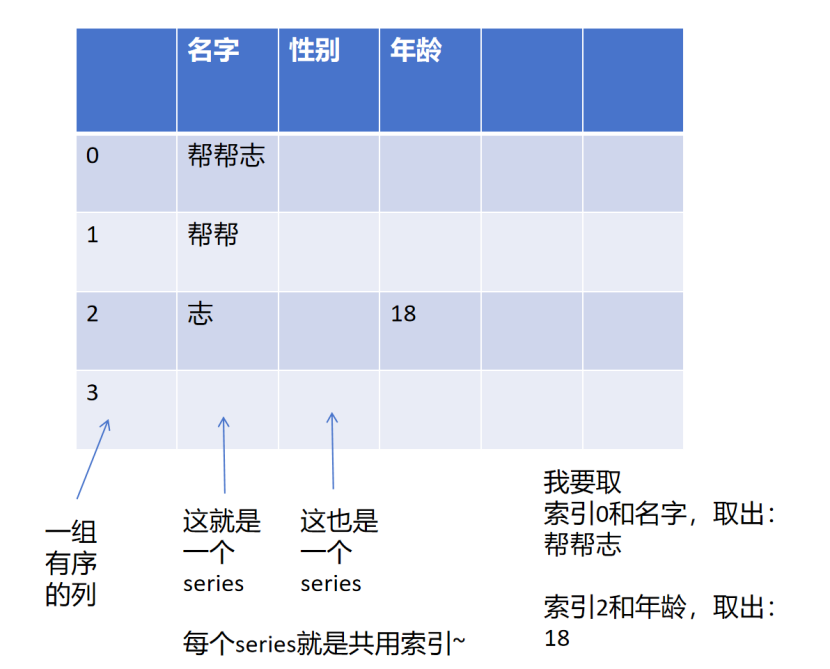
Series 本身就有很多功能,Series详细,请看链接: 02.Python代码Pandas - Series全系列分享(使用.特点.说明.取值.函数)
DataFrame有一个公共列(最左边那个,取值的索引)和若干个Series(数据)组成的表格型数据。加上DataFrame自己又很多的功能,所以对于实际使用数据分析等等 就非常的方便。
DataFrame就变成了: 又能存随便存 又能算 又能分析
表格形式的DataFrame可以存 :
一个班级的数据,一个部门员工的数据,一个商家的数据,一个商铺的数据。。。。存不下?业务复杂?那就还可以通过代码,分别取出几个不同的DataFrame来组合分析。
如果还是不懂怎么存的,没事:(可以点目录查看取值案例,另外还有一个取值的额外分享篇文章。就模拟了很多不同的数据,且演示了取值)
使用语法
字典格式数据
import pandas as pd
#准备数据 字典格式 目前是两组 k-v : name和number
mydata = {
#name为key 一个列表为value
'name':['bangbangzhi','hello','python'],
'number':[1,2,3]
}
#将字典格式数据交给pandas 声明为DataFrame
myDf01 = pd.DataFrame(mydata)
print(myDf01)
#DataFrame是表格型的,key是列名。value是列里面的数据。
#目前代码写了两列数据。
#没有指定索引列,DataFrame会默认数字从0开始来帮我们生成一个有序索引取值用

列表格式数据
01.列表里面都是列表:每个列表就为一行数据。如:运行后图片
#准备数据 列表
listData = [['bangbangzhi',1],['hello',2],['python',3]]
#将列表交给pd声明DataFrame
#columns=指定列名 dtype=指定数据类型 额外演示知识点:您生成DataFrame要指定类型
myDf02 = pd.DataFrame(listData,columns=['name','number'],dtype=float)
print(myDf02)
#列表数据里面全是数据本身。所以DataFrame()方法,需要多一个参数columns来指定列名(它是表格)。
#dtype= 是统一指定声明好DataFrame后的数据类型
#dtype=此处是语法分享,是否需要转类型,看实际情况

它提示我:
sys:1: FutureWarning: Could not cast to float64, falling back to object.
因为我演示转数据类型语法。这个提示的意思是:当你尝试将一个不能被转换为float64的数据类型(如:字符串)。这个操作可能会导致数据丢失或类型错误。因为Python无法将这些非数字字符串转换为数字,所以它只能将它们转换为object类型。
这个FutureWarning报错提示,我另一个做了非常详细的分析报错文章,从直译中文理解报错,到演示各种出这个报错的不同案例,一路分析到多种不同呢解决方案。文章为 :FutureWarning
02.列表里面都是字典:每个字典的key就是一列。最好保证字典里面的key都是相同单词,不然一个key就是一列不会整合一起。如:运行后图片
#声明一个列表,里面是字典
#注意,这里故意演示了: 空值。除了字典格式生成DataFrame , 那个c还只有一个数据
dData = [{'a':1,'bangbangzhi':2},{'a':100,'bangbangzhi':200,'c':10}]
#因为字典的key就是列名,所以现在没有指定列名
myDf03 = pd.DataFrame(dData)
print(myDf03)
#最后生成的是一个表格DataFrame
#没有数据的位置,用Nan填充
#如果每个字典的key 单词都不一样,那您的DataFrame就有很多很多列,不会合并

当前的案例是演示:不同数据类型去声明一个DataFrame。配合下面的内容来掌握使用很多操作DataFrame的方法。但是一般情况:
数据是外部的,且都很多。不会代码里面自己手动填写数据
那么请查阅:
(本来写 使用语法 这里一起的,篇幅太多太长了。最后决定拆出来单独写一遍,单独一篇就额外加内容,详细一点,目前正在上传官方审核 ing)
csv文件操作: csv导入DataFrame
json格式导入DataFrame: json格式导入DataFrame
execl导入DataFrame(正在上传ing)
不过我们可以通过自定义一些简单的数据,来学习演示DataFrame的各种方法及功能函数
完整声明语法
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
··data:DataFrame 的数据部分,可以是字典、二维数组、Series、DataFrame 或其他可转换为 DataFrame 的对象。如果不提供此参数,则创建一个空的 DataFrame。
··index:DataFrame 的行索引,用于标识每行数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的从0开始的整数索引。
··columns:DataFrame 的列索引(表头),用于标识每列数据。可以是列表、数组、索引对象等。如果不提供此参数,则创建一个默认的整数索引。
··dtype:指定 DataFrame 的数据类型。可以是 NumPy 的数据类型,例如 np.int64、np.float64 等。如果不提供此参数,则根据数据自动推断数据类型。
··copy:是否复制数据。默认为 False,表示不复制数据。如果设置为 True,则复制输入的数据。常用:有时数据分析可能会更改原始值,看情况是否允许,要么改了就改了。要么还是copy复制一份,这次算的数据是这次的数据分析,下次或者别人还要用原始数据接着算其他的
查:取值/访问/使用数据
直接用[列名][行索引] 取值就行了,
也可以:使用列名作为属性通过 .loc[]、.iloc[] 来访问,也可以使用标签或位置索引。。
如:
import pandas as pd
listData = [['bangbangzhi',1],['hello',2],['python',3]]
#将列表交给pd声明DataFrame
#columns=指定列名
myDf03 = pd.DataFrame(listData,columns=['name','number'])
print(myDf03)#输出一个表格格式的数据
print("隔开一下")
# 通过列名访问
print(myDf03['name'])#就仅仅输出这一列的数据
# 访问单个元素
print(myDf03['name'][0])#bangbangzhi name列的第1个数据(索引从0开始取值)
# 通过 .loc[] 访问
#.loc[ 行索引 , 列索引]
print(myDf03.loc[0, 'name'])#bangbangzhi 第1行的name列(索引从0开始取值)
# 通过 .iloc[] 访问
# .iloc[行位置,列位置]
print(myDf03.iloc[0, 1]) #1 第1行 第2列 (索引从0开始取值)
.loc[]、.iloc[] 具体的操作及详细语义和语法的说明,请查阅:
一共三种,很多案例且非常详细: DataFrame取值详细分享:.loc[]、.iloc[]

改:修改某值及添加新的列
修改某值及添加新的列—语法很像
import pandas as pd
listData = [['bangbangzhi',1],['hello',2],['python',3]]
#将列表交给pd声明DataFrame
#columns=指定列名
myDf04 = pd.DataFrame(listData,columns=['name','number'])
print(myDf04)#输出一个表格格式的数据
print("隔开一下")
#修改数据 直接给原有的列赋值新数据就可以了
myDf04['number'] = [100,200,300] #把number列的数据修改了
#原先不存在的列,直接写新的列名赋值数据,就可以添加一列
myDf04['New列'] = [111, 222, 333]
print(myDf04)

增:添加新的数据
loc方法
可以添加新的行
import pandas as pd
listData = [['bangbangzhi',1],['hello',2],['python',3]]
#将列表交给pd声明DataFrame
#columns=指定列名
myDf05 = pd.DataFrame(listData,columns=['name','number'])
print(myDf05)#输出一个表格格式的数据
print("隔开一下")
##当前两列数据 这个列表也两个数据
myDf05.loc[3] = ['我是新的行,且顺序和列的个数保持一致', 4]
print(myDf05)

append 方法
添加新行在末尾,已被弃用
concat方法
合并多个DataFrame (官方推荐方法)
添加新的数据,先把新的数据在生成一个DataFrame,在使用concat合并即可
import pandas as pd
#
listData = [['bangbangzhi',1],['hello',2],['python',3]]
#将列表交给pd声明DataFrame
#columns=指定列名
myDf06 = pd.DataFrame(listData,columns=['name','number'])
listData02 = [['我是新的数据',9],['我先捣鼓成DataFrame',10]]
#列名保持一致,毕竟要合并
myDf07 = pd.DataFrame(listData02,columns=['name','number'])
#concat([原有, 新的]) 新的会添加到原有的后面 (数据排序问题,第一个参数内容会在上面)
myDf06 = pd.concat([myDf06, myDf07], ignore_index=True)
print(myDf06)

删:各种删
import pandas as pd
#
listData = [['bangbangzhi',1],['hello',2],['python',3]]
#将列表交给pd声明DataFrame
#columns=指定列名
myDf07 = pd.DataFrame(listData,columns=['name','number'])
#删除name列
df_new = myDf07.drop('name', axis=1)
print(df_new)
print("隔开一下")
df_other = df_new.drop(0) # 删除索引为 0 的行
print(df_other)

DataFrame 全部 功能 函数
| 方法名称 | 功能描述 |
|---|---|
| head(n) | 返回 DataFrame 的前 n 行数据(默认前 5 行) |
| tail(n) | 返回 DataFrame 的后 n 行数据(默认后 5 行) |
| info() | 显示 DataFrame 的简要信息,包括列名、数据类型、非空值数量等 |
| describe() | 返回 DataFrame 数值列的统计信息,如均值、标准差、最小值等 |
| shape | 返回 DataFrame 的行数和列数(行数, 列数) |
| columns | 返回 DataFrame 的所有列名 |
| index | 返回 DataFrame 的行索引 |
| dtypes | 返回每一列的数值数据类型 |
| sort_values(by) | 按照指定列排序 |
| sort_index() | 按行索引排序 |
| dropna() | 删除含有缺失值(NaN)的行或列 |
| fillna(value) | 用指定的值填充缺失值 |
| isnull() | 判断缺失值,返回一个布尔值 DataFrame |
| notnull() | 判断非缺失值,返回一个布尔值 DataFrame |
| loc[] | 按标签索引选择数据 |
| iloc[] | 按位置索引选择数据 |
| at[] | 访问 DataFrame 中单个元素(比 loc[] 更高效) |
| iat[] | 访问 DataFrame 中单个元素(比 iloc[] 更高效) |
| apply(func) | 对 DataFrame 或 Series 应用一个函数 |
| applymap(func) | 对 DataFrame 的每个元素应用函数(仅对 DataFrame) |
| groupby(by) | 分组操作,用于按某一列分组进行汇总统计 |
| pivot_table() | 创建透视表 |
| merge() | 合并多个 DataFrame(类似 SQL 的 JOIN 操作) |
| concat() | 按行或按列连接多个 DataFrame |
| to_csv() | 将 DataFrame 导出为 CSV 文件 |
| to_excel() | 将 DataFrame 导出为 Excel 文件 |
| to_json() | 将 DataFrame 导出为 JSON 格式 |
| to_sql() | 将 DataFrame 导出为 SQL 数据库 |
| query() | 使用 SQL 风格的语法查询 DataFrame |
| duplicated() | 返回布尔值 DataFrame,指示每行是否是重复的 |
| drop_duplicates() | 删除重复的行 |
| set_index() | 设置 DataFrame 的索引 |
| reset_index() | 重置 DataFrame 的索引 |
| transpose() | 转置 DataFrame(行列交换) |
函数案例分享文章 单独复制走了(太多了),此处仅仅可以查阅功能。正在上传ing~
DataFrame 全部 统计 函数
import pandas as pd
listData = [['bangbangzhi',1],['hello',2],['python',3]]
#将列表交给pd声明DataFrame
#columns=指定列名
myDf08 = pd.DataFrame(listData,columns=['name','number'])
print(myDf08.shape) # 形状
print(myDf08.columns) # 列名
print(myDf08.index) # 索引
print(myDf08.head()) # 前几行数据,默认是前 5 行
print(myDf08.tail()) # 后几行数据,默认是后 5 行
print(myDf08.info()) # 数据信息
#数字运算的 标记对应的数字列(不然汉字/字符串哪来的 计算嘛)
print(myDf08['number'].describe())# 描述统计信息
print(myDf08['number'].mean()) # 求平均值
print(myDf08['number'].sum()) # 求和
print(myDf08['number'].max()) # 最大值
print(myDf08['number'].min()) # 最小值
(会陆续更新非常多的IT技术知识及泛IT的电商知识,可以点个关注,共同交流。ღ( ´・ᴗ・` )比心)
(也欢迎评论,提问。 我会依次回答~)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









