






本文将从五个方面【技术问题、技术手段、技术效果、代码实现逻辑和工程落地建议】解读以下专利。
US201916271154A1,ENHANCING HIYBRID SELE-ATTENTIONSTRUCTURE WITHRELATIVE-POSITION-AWARE BIAS FORSPEECH SYNTHESIS.
一、技术问题
传统的语音合成系统(如基于Transformer的自注意力模型)存在以下痛点:
-
位置信息缺失:自注意力机制本身不显式编码序列位置,需依赖额外位置编码,但对局部上下文(如语音中的邻近音素)建模不足。
-
注意力分散:全局加权平均可能导致注意力分布过于分散,忽略局部关键信号(例如相邻音素的依赖关系)。
-
层次结构建模不足:纯自注意力在建模语音的层次化结构(如音节→音素→音调)时表现不如RNN/CNN。
这些问题可能导致合成语音不自然(如逻辑混乱或发音错误)。
二、技术手段
专利提出一种混合架构,结合CNN/RNN与改进的自注意力机制,核心创新点如下:
1. 混合编码器结构
-
输入处理:
-
字符嵌入(Character Embeddings)通过CNN或RNN编码,捕获局部特征(如音素的短时依赖)。
-
同时,对同一字符嵌入应用相对位置感知的自注意力函数,增强全局依赖建模。
-
-
特征融合:
-
将CNN/RNN的输出与自注意力处理后的输出拼接(Concatenate),形成编码器输出。
-
目的:结合CNN/RNN的局部建模能力与自注意力的全局依赖捕捉能力。
-
2. 相对位置感知自注意力
-
标准自注意力缺陷:仅通过绝对位置编码(如正弦函数)无法有效建模局部关系。
-
改进方案:
-
在自注意力计算中引入相对位置偏置(Relative-Position-Aware Bias),公式详见专利内容。
-
局部增强:对相对位置进行截断(Clip),限制最大相对距离(如±m),仅学习局部范围内的关系(见专利中的图6)。
-
3. 多塔架构与解码器设计
-
编码器:多塔混合结构(Multi-Tower Hybrid Encoder)包含多个并行模块(如CNN/RNN塔 + 自注意力塔)。
-
解码器:基于N层自注意力块的解码器,通过多头注意力连接编码器输出与输入梅尔频谱图。
-
关键组件:
-
层归一化(Layer Norm):稳定训练过程。
-
前馈网络(Feed Forward):非线性变换增强表示能力。
-
线性投影(Linear Projection):调整特征维度以适应后续处理。
-
三、技术效果
通过实验验证(MOS评分),该方案实现了以下提升:
-
语音自然度:混合结构(CNN/RNN + 自注意力)的MOS评分优于单一结构(如纯CBHG或CNN)。
-
局部关系建模:相对位置编码显著减少注意力分散问题,合成语音更接近自然录音(仅差0.11 MOS)。
-
灵活性:支持可变长度输入(如未见过的文本序列),适应实际语音合成场景。
四、代码实现逻辑
核心模块伪代码 python
# 1. 字符嵌入编码(CNN/RNN分支)
char_embeddings = Embedding(text_input)
cnn_output = CNN_Encoder(char_embeddings) # 或 RNN_Encoder
# 2. 相对位置感知自注意力分支
relative_bias = RelativePositionBias(max_distance=m)
self_attn_output = SelfAttentionWithBias(char_embeddings, relative_bias)
self_attn_encoded = FFN(LayerNorm(self_attn_output)) # 前馈+归一化
# 3. 特征拼接与编码器输出
encoder_output = Concatenate([cnn_output, self_attn_encoded])
# 4. 解码器(多头注意力 + 梅尔频谱预测)
decoder_input = MultiHeadAttention(encoder_output, mel_spectrogram)
decoder_output = FFN(LayerNorm(decoder_input))
predicted_mel = LinearProjection(decoder_output)
# 5. 语音波形生成(通过Vocoder如WaveNet)
speech_waveform = Vocoder(predicted_mel)
关键实现细节
-
相对位置偏置矩阵:预计算所有可能相对位置的嵌入表(大小为2m+1),通过查表快速获取
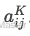 。
。 -
混合编码器:可设计为并行塔结构,每个塔独立处理输入后拼接。
-
训练技巧:使用残差连接、层归一化加速收敛,并采用Teacher Forcing策略训练解码器。
五、工程落地建议
-
模块化设计:将CNN/RNN编码器、自注意力模块、相对位置编码拆分为独立组件,便于复用和调试。
-
性能优化:利用CUDA内核加速相对位置矩阵计算,或使用预生成的相对位置索引。
-
实验验证:逐步对比纯自注意力、混合结构、加入相对偏置的效果(通过MOS或主观听测)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









