






Mask_RCNN在(40系显卡)rtx 4070下的GPU环境配置以及运行(附带CPU环境配置运行)
前言
因为最近在学习有关图像分割的一些内容,同时做的项目与图像定位分割有一定联系,先是在本机上跑了一些测试代码,其中就有Mask_RCNN,但在所有模型中,Mask_RCNN的发布时间也是相对较早,我开始配置的时候遇到了一系列的问题,也受到了网上很多大佬博文的帮助,在这里记录一下,同时cpu环境的配置比较简单,在下文中会有参考的链接,gpu是因为我最近换了新的显卡,40系好像只能支持11以上的cuda运行环境,所以花了一些时间。
源码地址
原始链接(只用cpu下使用的代码,10系和20系的老显卡可以使用):
https://github.com/matterport/Mask_RCNN
修改支持tensorfolw 2以上的链接(建议30系列以上的显卡使用该链接的代码):
https://github.com/leekunhee/Mask_RCNN
Anaconda python环境
conda create -n rcnn_cpu python=3.6 ##cpu环境创建,环境名为rcnn_cpu
conda create -n rcnn_gpu python=3.6.13 ##gpu环境创建,环境名为rcnn_gpu
数据集的制作与训练、测试代码
参考博文https://blog.csdn.net/qq_40770527/article/details/124249140
CPU环境配置
参考博文https://blog.csdn.net/weixin_54546190/article/details/123768891
我使用的代码如下:
# -*- coding: utf-8 -*-
import os
import sys
import random
import math
import re
import time
import numpy as np
import cv2
#import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf
from mrcnn.config import Config
# import utils
from mrcnn import model as modellib, utils
from mrcnn import visualize
import yaml
from mrcnn.model import log
from PIL import Image
os.environ["CUDA_VISIBLE_DEVICES"] = '0' # use GPU with ID=0
config = tf.compat.v1.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.7 # maximun alloc gpu50% of MEM
config.gpu_options.allow_growth = True # allocate dynamically
# os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
# os.environ["CUDA_VISIBLE_DEVICES"]="0"
# os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# Root directory of the project
ROOT_DIR = os.getcwd()
# ROOT_DIR = os.path.abspath("../")
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
iter_num = 0
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
class ShapesConfig(Config):
"""Configuration for training on the toy shapes dataset.
Derives from the base Config class and overrides values specific
to the toy shapes dataset.
"""
# Give the configuration a recognizable name
NAME = "shapes"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1
IMAGES_PER_GPU = 8
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # background + 1 shapes
# Use small images for faster training. Set the limits of the small side
# the large side, and that determines the image shape.
IMAGE_MIN_DIM = 320
IMAGE_MAX_DIM = 384
# Use smaller anchors because our image and objects are small
RPN_ANCHOR_SCALES = (8 * 6, 16 * 6, 32 * 6, 64 * 6, 128 * 6) # anchor side in pixels
# Reduce training ROIs per image because the images are small and have
# few objects. Aim to allow ROI sampling to pick 33% positive ROIs.
TRAIN_ROIS_PER_IMAGE = 100
# Use a small epoch since the data is simple
STEPS_PER_EPOCH = 100
# use small validation steps since the epoch is small
VALIDATION_STEPS = 50
config = ShapesConfig()
config.display()
class DrugDataset(utils.Dataset):
# 得到该图中有多少个实例(物体)
def get_obj_index(self, image):
n = np.max(image)
return n
# 解析labelme中得到的yaml文件,从而得到mask每一层对应的实例标签
def from_yaml_get_class(self, image_id):
info = self.image_info[image_id]
with open(info['yaml_path']) as f:
temp = yaml.safe_load(f.read())
labels = temp['label_names']
del labels[0]
return labels
# 重新写draw_mask
def draw_mask(self, num_obj, mask, image, image_id):
# print("draw_mask-->",image_id)
# print("self.image_info",self.image_info)
info = self.image_info[image_id]
# print("info-->",info)
# print("info[width]----->",info['width'],"-info[height]--->",info['height'])
for index in range(num_obj):
for i in range(info['width']):
for j in range(info['height']):
# print("image_id-->",image_id,"-i--->",i,"-j--->",j)
# print("info[width]----->",info['width'],"-info[height]--->",info['height'])
at_pixel = image.getpixel((i, j))
if at_pixel == index + 1:
mask[j, i, index] = 1
return mask
# 重新写load_shapes,里面包含自己的自己的类别
# 并在self.image_info信息中添加了path、mask_path 、yaml_path
# yaml_pathdataset_root_path = "/tongue_dateset/"
# img_floder = dataset_root_path + "rgb"
# mask_floder = dataset_root_path + "mask"
# dataset_root_path = "/tongue_dateset/"
def load_shapes(self, count, img_floder, mask_floder, imglist, dataset_root_path):
"""Generate the requested number of synthetic images.
count: number of images to generate.
height, width: the size of the generated images.
"""
# Add classes
self.add_class("shapes", 1, "strip")
for i in range(count):
# 获取图片宽和高
print(i)
filestr = imglist[i].split(".")[0]
# print(imglist[i],"-->",cv_img.shape[1],"--->",cv_img.shape[0])
# print("id-->", i, " imglist[", i, "]-->", imglist[i],"filestr-->",filestr)
# filestr = filestr.split("_")[1]
mask_path = mask_floder + "/" + filestr + ".png"
yaml_path = dataset_root_path + "labelme_json/" + filestr + "/info.yaml"
print(dataset_root_path + "labelme_json/" + filestr + "_json/img.png")
cv_img = cv2.imread(dataset_root_path + "labelme_json/" + filestr + "/img.png")
self.add_image("shapes", image_id=i, path=img_floder + "/" + imglist[i],
width=cv_img.shape[1], height=cv_img.shape[0], mask_path=mask_path, yaml_path=yaml_path)
# 重写load_mask
def load_mask(self, image_id):
"""Generate instance masks for shapes of the given image ID.
"""
global iter_num
print("image_id", image_id)
info = self.image_info[image_id]
count = 1 # number of object
img = Image.open(info['mask_path'])
num_obj = self.get_obj_index(img)
mask = np.zeros([info['height'], info['width'], num_obj], dtype=np.uint8)
mask = self.draw_mask(num_obj, mask, img, image_id)
occlusion = np.logical_not(mask[:, :, -1]).astype(np.uint8)
for i in range(count - 2, -1, -1):
mask[:, :, i] = mask[:, :, i] * occlusion
occlusion = np.logical_and(occlusion, np.logical_not(mask[:, :, i]))
labels = []
labels = self.from_yaml_get_class(image_id)
labels_form = []
for i in range(len(labels)):
if labels[i].find("strip") != -1:
# print "car"
labels_form.append("strip")
# elif labels[i].find("leg") != -1:
# # print "leg"
# labels_form.append("leg")
# elif labels[i].find("well") != -1:
# # print "well"
# labels_form.append("well")
class_ids = np.array([self.class_names.index(s) for s in labels_form])
return mask, class_ids.astype(np.int32)
def get_ax(rows=1, cols=1, size=8):
"""Return a Matplotlib Axes array to be used in
all visualizations in the notebook. Provide a
central point to control graph sizes.
Change the default size attribute to control the size
of rendered images
"""
_, ax = plt.subplots(rows, cols, figsize=(size * cols, size * rows))
return ax
# 基础设置
dataset_root_path = "D:\data_zhongding\\train_test\mask_rcnn_dingwei\\train_data\\"
img_floder = dataset_root_path + "pic"
mask_floder = dataset_root_path + "cv2_mask"
# yaml_floder = dataset_root_path
imglist = os.listdir(img_floder)
count = len(imglist)
# train与val数据集准备
dataset_train = DrugDataset()
dataset_train.load_shapes(count, img_floder, mask_floder, imglist, dataset_root_path)
dataset_train.prepare()
# print("dataset_train-->",dataset_train._image_ids)
dataset_val = DrugDataset()
dataset_val.load_shapes(count, img_floder, mask_floder, imglist, dataset_root_path)
dataset_val.prepare()
# print("dataset_val-->",dataset_val._image_ids)
# Load and display random samples
# image_ids = np.random.choice(dataset_train.image_ids, 4)
# for image_id in image_ids:
# image = dataset_train.load_image(image_id)
# mask, class_ids = dataset_train.load_mask(image_id)
# visualize.display_top_masks(image, mask, class_ids, dataset_train.class_names)
# Create model in training mode
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=MODEL_DIR)
# Which weights to start with?
init_with = "coco" # imagenet, coco, or last
if init_with == "imagenet":
model.load_weights(model.get_imagenet_weights(), by_name=True)
elif init_with == "coco":
# Load weights trained on MS COCO, but skip layers that
# are different due to the different number of classes
# See README for instructions to download the COCO weights
# print(COCO_MODEL_PATH)
model.load_weights(COCO_MODEL_PATH, by_name=True,
exclude=["mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
elif init_with == "last":
# Load the last model you trained and continue training
model.load_weights(model.find_last()[1], by_name=True)
# Train the head branches
# Passing layers="heads" freezes all layers except the head
# layers. You can also pass a regular expression to select
# which layers to train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=10,
layers='heads')
# Fine tune all layers
# Passing layers="all" trains all layers. You can also
# pass a regular expression to select which layers to
# train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE / 10,
epochs=10,
layers="all")
同时需要注意的是,源代码输出的图像没有自动保存,他只会plot出来,然后我嫌这样太麻烦,就在中./mrcnn/visualize.py文件中做出了以下的修改,注释的代码是源代码:
# def display_differences(image,
# gt_box, gt_class_id, gt_mask,
# pred_box, pred_class_id, pred_score, pred_mask,
# class_names, title="", ax=None,
# show_mask=True, show_box=True,
# iou_threshold=0.5, score_threshold=0.5):
# """Display ground truth and prediction instances on the same image."""
# # Match predictions to ground truth
# gt_match, pred_match, overlaps = utils.compute_matches(
# gt_box, gt_class_id, gt_mask,
# pred_box, pred_class_id, pred_score, pred_mask,
# iou_threshold=iou_threshold, score_threshold=score_threshold)
# # Ground truth = green. Predictions = red
# colors = [(0, 1, 0, .8)] * len(gt_match)\
# + [(1, 0, 0, 1)] * len(pred_match)
# # Concatenate GT and predictions
# class_ids = np.concatenate([gt_class_id, pred_class_id])
# scores = np.concatenate([np.zeros([len(gt_match)]), pred_score])
# boxes = np.concatenate([gt_box, pred_box])
# masks = np.concatenate([gt_mask, pred_mask], axis=-1)
# # Captions per instance show score/IoU
# captions = ["" for m in gt_match] + ["{:.2f} / {:.2f}".format(
# pred_score[i],
# (overlaps[i, int(pred_match[i])]
# if pred_match[i] > -1 else overlaps[i].max()))
# for i in range(len(pred_match))]
# # Set title if not provided
# title = title or "Ground Truth and Detections\n GT=green, pred=red, captions: score/IoU"
# # Display
# display_instances(
# image,
# boxes, masks, class_ids,
# class_names, scores, ax=ax,
# show_bbox=show_box, show_mask=show_mask,
# colors=colors, captions=captions,
# title=title)
def display_instances(image, boxes, masks, class_ids, class_names,path='',
scores=None, title="",
figsize=(16, 16), ax=None,
show_mask=True, show_bbox=True,
colors=None, captions=None):
"""
boxes: [num_instance, (y1, x1, y2, x2, class_id)] in image coordinates.
masks: [height, width, num_instances]
class_ids: [num_instances]
class_names: list of class names of the dataset
scores: (optional) confidence scores for each box
title: (optional) Figure title
show_mask, show_bbox: To show masks and bounding boxes or not
figsize: (optional) the size of the image
colors: (optional) An array or colors to use with each object
captions: (optional) A list of strings to use as captions for each object
"""
# Number of instances
N = boxes.shape[0]
if not N:
print("\n*** No instances to display *** \n")
else:
assert boxes.shape[0] == masks.shape[-1] == class_ids.shape[0]
# If no axis is passed, create one and automatically call show()
auto_show = False
if not ax:
_, ax = plt.subplots(1, figsize=figsize)
auto_show = True
# Generate random colors
colors = colors or random_colors(N)
# Show area outside image boundaries.
height, width = image.shape[:2]
ax.set_ylim(height + 10, -10)
ax.set_xlim(-10, width + 10)
ax.axis('off')
ax.set_title(title)
masked_image = image.astype(np.uint32).copy()
for i in range(N):
color = colors[i]
# Bounding box
if not np.any(boxes[i]):
# Skip this instance. Has no bbox. Likely lost in image cropping.
continue
y1, x1, y2, x2 = boxes[i]
if show_bbox:
p = patches.Rectangle((x1, y1), x2 - x1, y2 - y1, linewidth=2,
alpha=0.7, linestyle="dashed",
edgecolor=color, facecolor='none')
ax.add_patch(p)
# Label
if not captions:
class_id = class_ids[i]
score = scores[i] if scores is not None else None
label = class_names[class_id]
caption = "{} {:.3f}".format(label, score) if score else label
else:
caption = captions[i]
ax.text(x1, y1 + 8, caption,
color='w', size=11, backgroundcolor="none")
# Mask
mask = masks[:, :, i]
if show_mask:
masked_image = apply_mask(masked_image, mask, color)
# Mask Polygon
# Pad to ensure proper polygons for masks that touch image edges.
padded_mask = np.zeros(
(mask.shape[0] + 2, mask.shape[1] + 2), dtype=np.uint8)
padded_mask[1:-1, 1:-1] = mask
contours = find_contours(padded_mask, 0.5)
for verts in contours:
# Subtract the padding and flip (y, x) to (x, y)
verts = np.fliplr(verts) - 1
p = Polygon(verts, facecolor="none", edgecolor=color)
ax.add_patch(p)
ax.imshow(masked_image.astype(np.uint8))
if auto_show:
plt.savefig(path+'.jpg')
plt.show()
注意事项(bug)
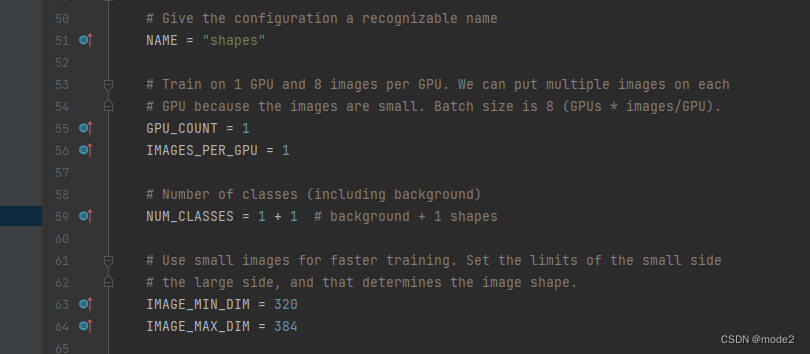
代码的第55行左右的GPU_COUNT参数,就算你使用CPU进行训练,也不要将它的参数改为0,不然训练会报错,我之前因为这个问题调了两天的代码。
同时由于python3.6的pip版本过老,会提醒更新,如果运行以下代码发生报错
python -m pip install --upgrade pip
报错信息如果是ssl报错,信息如下:
Could not fetch URL https://pypi.tuna.tsinghua.edu.cn/simple/ipython/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.tuna.tsinghua.edu.cn', port=443): Max retries exceeded with url: /simple/ipython/ (Caused by SSLError(SSLEOFError(8, 'EOF occurred in violation of protocol (_ssl.c:1124)'))) - skipping
ERROR: Could not find a version that satisfies the requirement ipython (from versions: none)
可以尝试将上述的运行命令修改如下:
python -m pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple ipython --trusted-host pypi.tuna.tsinghua.edu.cn
GPU环境配置
主要框架:
cudatoolkit:11.0.221
cudnn:8.2.1
tensorflow-gpu:2.4.0
Keras:2.4.3
opencv-python:3.4.3.18
整体使用的包版本如下:
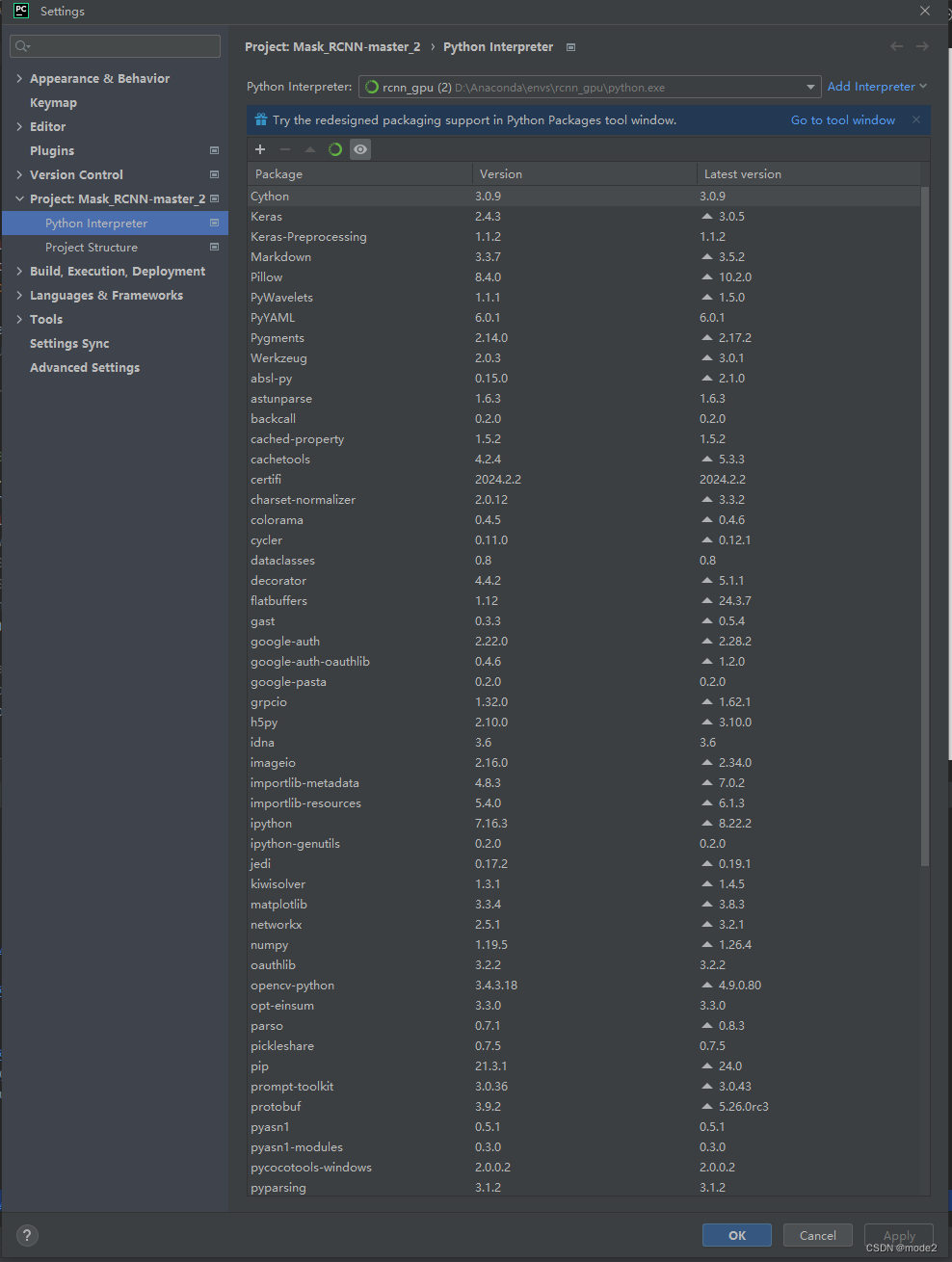
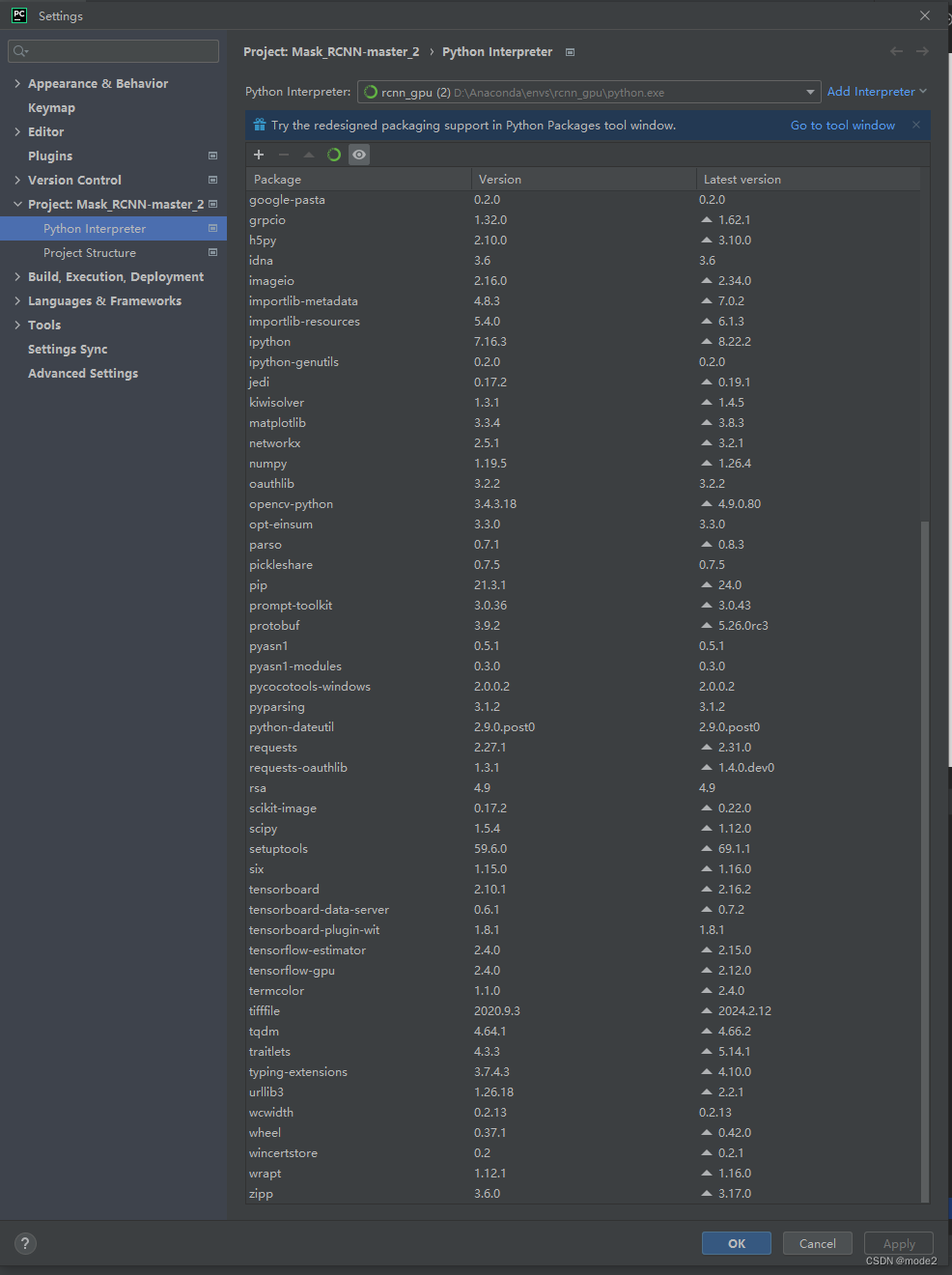
测试图:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









