







锲子
在使用pandas处理数据时,遇到了一种要按照留存天数来处理的数据,当列所对应的日期超过了最晚的“今天”那么数据就要置为0,举个例子:
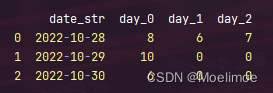
在这个DataFrame中,需要将超过了今天2022-10-30的数据置为“-”,需要得到下面的一个倒三角形状的数据
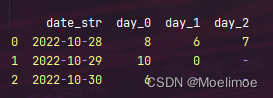
在这个DataFrame中,day_0, day_1, …还可能是week_0, week_1, …,解决这类问题会有很多种方法,比较直观但是复杂度很高的方法就是for 循环遍历行,再遍历列,在遇到大于“今天”的数据时将其值修改为“-”
处理按天为单位的数据
待处理的数据:
import re
import pandas as pd
date_unit = "day"
now_date = pd.Timestamp.now().floor("D")
print(now_date)
print(now_date - pd.to_datetime("2022-10-10"))
raw_df = pd.DataFrame(
{
"date_str": ["2022-10-27", "2022-10-28", "2022-10-29", "2022-10-30", "2022-10-31"],
"day_0": [8, 8, 10, 6, 0],
"day_1": [4, 6, 0, 0, 0],
"day_2": [6, 7, 0, 0, 0],
"day_3": [4, 3, 1, 0, 0],
}
)
print(raw_df)
# 当前df
# date_str day_0 day_1 day_2 day_3
# 0 2022-10-27 8 4 6 4
# 1 2022-10-28 8 6 7 3
# 2 2022-10-29 10 0 0 1
# 3 2022-10-30 6 0 0 0
# 4 2022-10-31 0 0 0 0
# 目标df
# date_str day_0 day_1 day_2 day_3
# 0 2022-10-27 8 4 6 4
# 1 2022-10-28 8 6 7 3
# 2 2022-10-29 10 0 0 -
# 3 2022-10-30 6 0 - -
# 4 2022-10-31 0 - - -
今日的日期以我处理时的2022-10-31为准,日期的单位是按天,获取今天的日期使用pd.Timestamp.now()比datetime.datetime.now()会更方便转换成其他的格式来使用,
将日期列date_str设置为index并转换为datetime对象方便比较
df.set_index("date_str", inplace=True)
# date_str变成了index放在最左侧
# day_0 day_1 day_2 day_3
# date_str
# 2022-10-27 8 4 6 4
# 2022-10-28 8 6 7 3
# 2022-10-29 10 0 0 1
# 2022-10-30 6 0 0 0
# 2022-10-31 0 0 0 0
# 修改index列的类型为datetime类型,之后要用于日期加减运算
df.index = df.index.map(pd.to_datetime)
print(df.index)
# DatetimeIndex(['2022-10-27', '2022-10-27', '2022-10-28', '2022-10-30',
# '2022-10-31'],
# dtype='datetime64[ns]', name='date_str', freq=None)
这里用了df.index.map和接下来的df.columns.map,map方法是对DataFrame的整个列的值做运算和各种操作的方法,类似Python内置的map方法,接收一个方法来同时处理多个数据
将列名称的数字提取出来转换为整数,方便日期加减运算,处理完之后要还原列名称,所以拷贝一个副本,完事之后将列名称修改回去
raw_columns = df.columns.copy()
df.columns = df.columns.map(lambda x: int(re.sub("\D", "", x))) # \d表示匹配数字,大写\D表示匹配非数字,将非数字替换为“”
print(df.columns) # Int64Index([0, 1, 2], dtype='int64')
使用pandas的整体操作行列的方法df.apply对二维的行和列一起做计算和比较,这里参数axis默认为0使用的是横向操作
df = df.apply(
lambda col:
# 这里为了方便debug断点调试可以单独写成一个方法就可以在方法里面打断点观察
col.where(
col.index + pd.Timedelta(col.name, unit=date_unit) <= now_date,
"-"
)
)
其中col.index + pd.Timedelta(col.name, unit=date_unit),col.index就是date_str index中的日期(2022-10-27, 2022-10-28, …),col.name是列的名称现在已经被修改成整数(0, 1, 2…),就是用将df中index的日期加上往后延的留存天数:

其中col.where(...)的操作是对pd.DataFrame或者pd.DataFrame其中一列pd.Series对象的操作,可以对不满足条件的数据赋予想要的值,第一个参数是一个条件,满足这个条件的数据都会被保留,否则就会被赋予其他的值,这个值就是第二个参数,当然这个值也可以用方法做各种运算
当然也可以纵向操作,不过在这次的情况效率会比横向操作要差,大概率是因为多使用了row.index.map方法
df = df.apply(
lambda row:
row.where(
row.name + row.index.map(lambda x: pd.Timedelta(x, unit=date_unit)) <= now_date,
"-"
),
axis=1
)
df.columns = raw_columns
print(df)
最后把列名称还原,把index转换回列
# 将留存的天数的列还原名称,顺序没有发生改变,直接替换即可
df.columns = raw_columns
# 将index还原为列
df.reset_index(inplace=True)
print(df)
# date_str day_0 day_1 day_2 day_3
# 0 2022-10-27 8 4 6 4
# 1 2022-10-28 8 6 7 3
# 2 2022-10-29 10 0 0 -
# 3 2022-10-30 6 0 - -
# 4 2022-10-31 0 - - -
完整的代码
import re
import pandas as pd
date_unit = "day"
now_date = pd.Timestamp.now().floor("D")
print(now_date)
print(now_date - pd.to_datetime("2022-10-10"))
raw_df = pd.DataFrame(
{
"date_str": ["2022-10-27", "2022-10-28", "2022-10-29", "2022-10-30", "2022-10-31"],
"day_0": [8, 8, 10, 6, 0],
"day_1": [4, 6, 0, 0, 0],
"day_2": [6, 7, 0, 0, 0],
"day_3": [4, 3, 1, 0, 0],
}
)
print(raw_df)
# 当前df
# date_str day_0 day_1 day_2 day_3
# 0 2022-10-27 8 4 6 4
# 1 2022-10-28 8 6 7 3
# 2 2022-10-29 10 0 0 1
# 3 2022-10-30 6 0 0 0
# 4 2022-10-31 0 0 0 0
# 目标df
# date_str day_0 day_1 day_2 day_3
# 0 2022-10-27 8 4 6 4
# 1 2022-10-28 8 6 7 3
# 2 2022-10-29 10 0 0 -
# 3 2022-10-30 6 0 - -
# 4 2022-10-31 0 - - -
df = raw_df
# 将日期列date_str设置为index并转换为datetime对象方便比较
df.set_index("date_str", inplace=True)
# day_0 day_1 day_2 day_3
# date_str
# 2022-10-27 8 4 6 4
# 2022-10-28 8 6 7 3
# 2022-10-29 10 0 0 1
# 2022-10-30 6 0 0 0
# 2022-10-31 0 0 0 0
df.index = df.index.map(pd.to_datetime)
print(df.index)
# DatetimeIndex(['2022-10-27', '2022-10-27', '2022-10-28', '2022-10-30',
# '2022-10-31'],
# dtype='datetime64[ns]', name='date_str', freq=None)
# 将列名称的数字提取出来,方便做运算,处理完之后要还原列名称,所以拷贝一个副本,完事之后将列名称修改回去
raw_columns = df.columns.copy()
df.columns = df.columns.map(lambda x: int(re.sub("\D", "", x))) # \d表示匹配数字,大写\D表示匹配非数字,将非数字替换为“”
print(df.columns) # Int64Index([0, 1, 2], dtype='int64')
print(df)
df = df.apply(
lambda col:
col.where(
col.index + pd.Timedelta(col.name, unit=date_unit) <= now_date,
"-"
),
# apply还有一个参数axis=0,默认横向操作,也就是一列一列地操作,axis=1时为竖向操作
)
# 将留存的天数的列还原名称,顺序没有发生改变,直接替换即可
df.columns = raw_columns
# 将index还原为列
df.reset_index(inplace=True)
print(df)
# date_str day_0 day_1 day_2 day_3
# 0 2022-10-27 8 4 6 4
# 1 2022-10-28 8 6 7 3
# 2 2022-10-29 10 0 0 -
# 3 2022-10-30 6 0 - -
# 4 2022-10-31 0 - - -
标记位于“今天”的位置提示数据未满
在上面的DataFrame中同时想要标记位于“今天”的数据,以提示这一天的数据是不满一天的,也就是得到一条which_today的这样的数据:
which_today
day_4
day_3
day_2
day_1
day_0
df.set_index("date_str", inplace=True)
df.index = df.index.map(pd.to_datetime)
which_is_today = df.index.map(
lambda x:
f"{date_unit}_{(now_date - x).days}"
)
print(which_is_today)
df["which_today"] = which_is_today
print(df)
# date_str
# 2022-10-27 8 4 6 4 day_4
# 2022-10-28 8 6 7 3 day_3
# 2022-10-29 10 0 0 - day_2
# 2022-10-30 6 0 - - day_1
# 2022-10-31 0 - - - day_0
now_date - x得到一个pd.TimeDelta的时间差对象,可以用.days从这个对象中获取时间差的天数
最后总结一下,这一篇介绍了在同时操作DataFrame行列时使用到的一些方法,主要有Series的map方法,DataFrame的apply方法,DataFrame和Series共有的where方法以及pandas中的一些时间相关操作方法,这些方法在特定业务逻辑的处理中都会有不错的帮助














 2784
2784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









