







 urllib.parse是Python标准库中的模块,用于处理URL的相关操作,包括URL解析、构建、查询参数处理和URL引用处理。它提供了解析URL到各部分的函数,以及构建完整URL的工具。此外,该模块还支持对特殊字符进行编码和解码,例如使用urlencode、quote和unquote函数。掌握urllib.parse的使用能帮助开发者更高效地处理Web相关任务。
urllib.parse是Python标准库中的模块,用于处理URL的相关操作,包括URL解析、构建、查询参数处理和URL引用处理。它提供了解析URL到各部分的函数,以及构建完整URL的工具。此外,该模块还支持对特殊字符进行编码和解码,例如使用urlencode、quote和unquote函数。掌握urllib.parse的使用能帮助开发者更高效地处理Web相关任务。
urllib.parse模块简介 主要功能 URL解析构建 查询参数处理 URL引用处理 使用示例 对特殊字符进行编码 urllib.parse编码和解码的使用——《跟老吕学Python编程》附录资料
urllib.parse模块简介
urllib.parse模块是Python标准库中的一个重要组件,主要用于处理URL(统一资源定位符)相关的操作。它提供了一组函数和类,用于解析、构建、合并、引用和引用URL。对于需要处理网页请求、API调用或任何与Web交互的Python开发者来说,这个模块都是不可或缺的。
主要功能
1. URL解析
urllib.parse提供了多个函数来解析URL的各个组成部分。例如,urlparse()函数可以将一个URL字符串分解为多个组成部分,如协议(http、https等)、网络位置(netloc)、路径(path)、查询参数(params)、查询字符串(query)和片段标识符(fragment)。
2. URL构建
与解析相对应,urllib.parse也提供了构建URL的函数。urlunparse()函数可以接受解析后得到的组件,并将它们重新组合成一个完整的URL字符串。
3. 查询参数处理
urllib.parse还提供了处理URL查询参数的功能。parse_qs()和parse_qsl()函数可以解析查询字符串,将其转换为Python字典或列表。同样,urlencode()函数可以将字典或类似的数据结构转换为查询字符串。
4. URL引用和引用处理
urllib.parse中的urljoin()函数可以合并基础URL和相对URL,生成完整的URL。此外,urldefrag()和urlsplit()函数可以进一步分解URL的不同部分。
使用示例
下面是一个简单的使用示例,展示了如何使用urllib.parse模块来解析和构建URL:
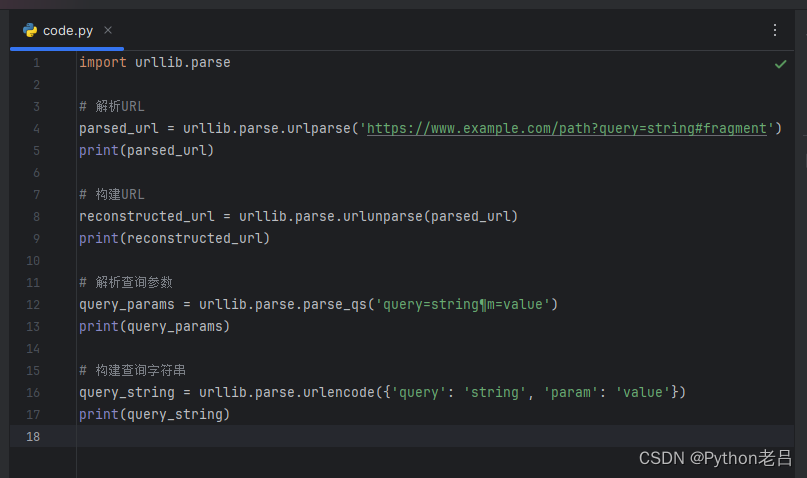
import urllib.parse
# 解析URL
parsed_url = urllib.parse.urlparse('https://www.example.com/path?query=string#fragment')
print(parsed_url)
# 构建URL
reconstructed_url = urllib.parse.urlunparse(parsed_url)
print(reconstructed_url)
# 解析查询参数
query_params = urllib.parse.parse_qs('query=string¶m=value')
print(query_params)
# 构建查询字符串
query_string = urllib.parse.urlencode({'query': 'string', 'param': 'value'})
print(query_string)
urllib.parse模块是Python处理URL的强大工具,它提供了丰富的函数和类,帮助开发者轻松地解析、构建、合并和处理URL。无论是进行网页爬虫开发、API调用,还是其他任何需要处理URL的场合,这个模块都能提供极大的便利。通过掌握urllib.parse模块的使用,Python开发者可以更加高效地处理Web相关的任务。
对特殊字符进行编码
urllib.parse模块提供了两个主要的函数来处理URL编码:quote()和quote_plus()。这两个函数都可以对特殊字符进行编码,但它们在处理空格和加号时有所不同。
quote()函数只编码非字母数字字符和某些保留字符。这意味着空格不会被编码,而是保持原样。quote_plus()函数则更加严格,它会编码所有的非字母数字字符,包括空格。空格会被编码为+,而其他特殊字符则会被编码为%加上对应的ASCII码。
下面是一个使用urllib.parse对特殊字符进行编码的示例:
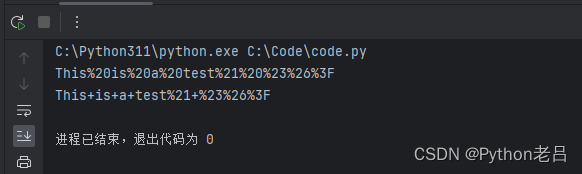
import urllib.parse
# 使用quote()函数对URL进行编码
encoded_url_with_quote = urllib.parse.quote("This is a test! #&?")
print(encoded_url_with_quote) # 输出:This+is+a+test%21+%23%26%3F
# 使用quote_plus()函数对URL进行编码
encoded_url_with_quote_plus = urllib.parse.quote_plus("This is a test! #&?")
print(encoded_url_with_quote_plus) # 输出:This+is+a+test%21+%23%26%3F
# 注意,对于空格,quote()保持原样,而quote_plus()则编码为+

在处理URL时,选择使用quote()还是quote_plus()取决于你的具体需求。如果你希望保持空格不变,可以使用quote();如果你希望将所有特殊字符都编码,包括空格,那么quote_plus()是更好的选择。
除了对URL进行编码外,urllib.parse模块还提供了其他有用的函数,如unquote()和unquote_plus(),用于对编码后的URL进行解码。这些函数可以帮助我们在处理URL时更加灵活和方便。
urllib.parse编码和解码的使用
urllib.parse编码和解码的使用在Python的网络编程中扮演着至关重要的角色。当我们需要从Web页面中获取数据或与Web服务器进行交互时,常常需要对URL进行编码和解码操作,以确保数据的正确传输和解析。
在Python的urllib.parse模块中,提供了多个函数来处理URL的编码和解码。其中,quote()函数用于对URL中的特殊字符进行编码,而unquote()函数则用于对编码后的URL进行解码。
编码过程通常发生在我们将数据添加到URL中时。
由于URL中只允许使用特定的字符集,因此当我们的数据中包含URL不允许的字符时,就需要使用quote()函数进行编码。
例如,如果我们要将字符串"Hello, World!“添加到URL的查询参数中,就需要使用quote()函数将其编码为"Hello%2C%20World%21”,因为逗号(,)和空格()在URL中是特殊字符,需要被编码。
解码过程则发生在我们从URL中获取数据后。
当我们从Web页面中获取到编码后的URL时,为了能够正确解析其中的数据,就需要使用unquote()函数对URL进行解码。
例如,如果我们从Web页面中获取到编码后的URL"Hello%2C%20World%21",就可以使用unquote()函数将其解码为原始的字符串"Hello, World!"。
除了quote()和unquote()函数外,urllib.parse模块还提供了其他用于处理URL编码和解码的函数,如quote_plus()和unquote_plus()。这些函数与quote()和unquote()类似,但在处理空格时有所不同。quote_plus()函数会将空格编码为"+“,而unquote_plus()函数则会将”+"解码为空格。
urllib.parse模块中的编码和解码函数为我们在Python中进行网络编程提供了强大的支持。通过使用这些函数,我们可以轻松地对URL进行编码和解码操作,确保数据的正确传输和解析。
总结
urllib.parse模块是Python中处理URL的强大工具,其中urlencode函数用于对URL进行编码,将特殊字符转换为可以在URL中安全传输的格式。同时,我们也可以使用quote和quote_plus函数对单个特殊字符进行编码,以及使用unquote和unquote_plus函数对编码后的字符串进行解码。掌握这些函数的使用,可以帮助我们更好地处理URL,确保数据的正确传输和解析。
👨💻博主Python老吕说:如果您觉得本文有帮助,辛苦您🙏帮忙点赞、收藏、评论,您的举手之劳将对我提供了无限的写作动力!🤞
🔥精品付费专栏:《跟老吕学Python编程》、《Python游戏开发实战讲解》、《Python Web开发实战》、《Python网络爬虫实战》、《Python APP开发实战》
🌐前端:《HTML》、《CSS》、《JavaScript》、《Vue》
💻后端:《C语言》、《C++语言》、《Java语言》、《R语言》、《Ruby语言》、《PHP语言》、《Go语言》、《C#语言》、《Swift语言》、《跟老吕学Python编程·附录资料》
💾数据库:《Oracle》、《MYSQL》、《SQL》、《PostgreSQL》、《MongoDB》




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











