







(记录学习,有误请一定告知)
文章目录
为什么需要应用层
虽然说传输层已经完成了两个应用进程间端到端的通信,但为什么还需要应用层? 因为除了端到端的通信外,网络应用进程之间还有许多其他不同的通信规则,不单单只是单纯的通信而已,因此这就需要了应用层
应用层协议要做什么
应用层协议应该要定义以下几种功能:
- 应用进程机换报文类型 ex:请求/响应 报文
- 各种报文类型的语法
- 字段的语义
- 进程何时,以及如何发送报文
应用层协议-DNS(域名系统)
1. 概述
域名系统就是互联网的命名系统,其作用就是将互联网上的主机名转换为IP地址
2. 互联网的域名结构
直接上例子:
whu.edu.cn=>whu是三级域名,edu是二级域名,cn是顶级域名
互联网上的域名结构早期采用的是非等级的名字结构,后来采用层次树状结构的命名方式,每一个连接在互联网上的主机或路由器都有一个唯一的层次结构名字,级别越低的域名写在左边,而最高级别的顶级域名写在最右边,每一个标号不超过63个字符且不区分大小写

3. 域名服务器
3.1 首先,域名服务器采用的是分布式的服务器,目的是因为如果只使用一个域名服务器来维持整个互联网这么庞大数量的主机,那么1.容易造成负荷过大无法工作2.如果该服务器损坏,则整个互联网都会瘫痪
3.2 域名服务器是以区为单位,区一定小于或等于域,例如一个公司abc有x,y两个部门,x下面又有uvw,y下面有t,则当该公司指设置一个区时>区abc.com和域abc.com是一个意思,但当公司要设置两个区如abc.com和y.abc.com则我们可以说区abc.com和y.abc.com隶属于域abc.com

3.3 各类型的域名服务器: **根域名服务器** : 根域名服务器是最高层级的域名服务器,所有的根域名服务器都知道所有的顶级域名服务器的主机名和ip地址,当本地DNS服务器没有办法解析域名时,则必须先请求根域名服务器,因此可以这么说只要所有根域名服务器都瘫痪了那么整个互联网都瘫痪了,此外,根域名服务器采用**任播**技术,因此当某台DNS服务器向某个根域名服务器的ip地址发送查询报文时,互联网上的路由器就能找到离这个DNS服务器最近的根域名服务器 **顶级域名服务器(TLD)** : 负责管理所以在顶级域名服务器登记的二级域名,当收到DNS查询时,给出相对应的回答(1.最后的结果2.下一个应该要找的域名服务器的IP地址) **权限域名服务器** : 负责的是一个区的域名服务器,当一个权限域名服务器没有办法给出最后的结果时,就会告诉DNS客户,应当去找哪一个权限域名服务器 **本地域名服务器**: 不属于域名服务器层次结构中,每一个互联网服务提供者(如移动、联通......)或者一个学校的一个系都可以有一个自己的本地域名服务器,本地域名服务器的重要在于,当一台主机发出DNS请求时,这个查询请求报文就是发给本地域名服务器的,而在透过本地域名服务器将这个DNS请求发送给根域名服务器 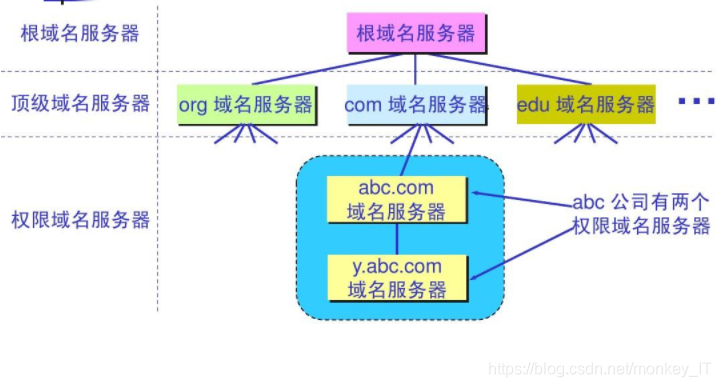
3.4 域名解析步骤:域名解析可分为 **递归查询**和 **迭代查询**,下面对这两种查询做出介绍 **递归查询 :** 通常主机向本地域名服务器发送的查询就是采用递归查询,所谓的递归就是当主机向本地域名服务器发送查询时,本地域名服务器并不知道查询域名的IP地址时,本地域名服务器会以DNS客户的身份向根域名服务器发送查询,而不是让主机自己去像根域名服务器查询 **迭代查询 :** 通常本地域名服务器向根域名服务器发出查询的方式为迭代查询,迭代查询的特点在于,如果当本地域名服务器向根域名服务器发出迭代查询时,根域名如果知道则回传相对应的IP地址(根域名通常不会知道),如果根域名服务器不知道则会告诉本地域名服务器应当去找哪一个顶级域名服务器,而本地域名服务器收到响应后,向顶级域名服务器发送DNS查询请求,最后得到本机发送给本地域名服务器的请求域名IP地址后,将结果返回给主机

3.5 高速缓存(高速缓存域名服务器) : 这个技术在域名服务器和主机经常使用,目的是为了减少互联网中DNS查询报文的数量,高速缓存会记录近期查询过的域名和IP地址映射,或者记录某一顶级域名应向哪个顶级域名服务器查询,
举两个例子:
当主机本身的高速缓存中没有相对应的域名IP映射时,向本地域名服务器发送DNS查询报文,而此时在本地域名服务器的高速缓存中
- 刚好有该查询请求的域名-IP映射,则本地域名则不再发送查询请求给根域名服务器,直接将结果返回给主机
- 没有该域名-IP的映射,但高速缓存有该查询域名的顶级域名服务器IP地址,则此时本地域名服务器就不会再将查询报文发送到根域名服务器,而是直接将查询报文发给该顶级域名服务器
万维网(WWW)
1. 万维网 :
万维网也可以理解成WEB,是一个大规模联机式的信息储藏所,用户可以很方便的通过超链接,来获取(访问)在互联网上的各种资源,万维网是一个分布式超媒体系统,比起超文本系统只是包含其他文档的链接文本,超媒体系统还包含如图片、声音…,那么问题来了:
1. 万维网是如何标志分布在整个互联网上的各种万维网文档呢? 那就是使用统一资源定位符URL
2. 万维网用什么协议来实现各种连接? 用的HTTP(超文本传送协议)
3. 万维网怎样使各种风格的创作都能在页面中显示呢? 用的HTML
2. URL (统一资源定位符) :
URL就是标记了互联网上的资源位置,和获取访问这些资源的方式,格式为
<协议>://<主机>:<端口>/<路径>,
协议 : 指的是用什么协议来获取万维网文档,现在最多的就是http,https,ftp
主机 : 就是该主机在互联网中的域名
端口、路径很多时后可以省略
注意:协议和主机不区分大小写,路径区分大小写
注意:使用HTTP的URL默认端口为80
3. HTTP (超文本传输协议) :
3.1 概述 : HTTP是面向事物的网络应用层协议,他定义了客户端(浏览器)如何向服务器端请求万维网文档,也定义了服务器端如何向客户端响应万维网文档(注意:此处的文档不单单只是文档,还包含图片、声音、影片…)
3.2 连接过程 : 每个万维网网点都会有一个服务器进程监听TCP的80端口,当发现有浏览器向他发出连接请求,当监听到有连接请求时,开始建立TCP连接,建立好TCP连接后,浏览器就向该网点发出某个页面请求,服务器接着返回浏览器请求的页面作为响应,最后断开TCP连接,在这个浏览器和服务器交互的过程中,必须严格遵守的协议就是HTTP协议
3.3 特点: HTTP是无连接、无状态的协议
无连接协议 : 虽然HTTP使用了TCP协议来保证数据传输时的可靠性,但HTTP是无连接的协议,这意味着通信的双方在交换HTTP报文之前,是不需要建立HTTP连接的
无状态协议 : 可以理解为,服务器并不会记录客户端的状态,这个状态包含了是否曾经发送过相同的请求,举个例子,当同个客户重复发送给同一个服务器同样的请求内容,服务器会重复发送相同的响应给客户端
3.4 所需时间:
从下图可以知道,客户端会在向服务器发送第三次握手时,将HTTP请求报文传输出去,服务器端收到请求后,把请求的文档作为响应返回,这个过程所需的时间为 2*RTT(建立TCP三次握手)+文档本身大小

3.5 HTTP1.0 v.s. HTTP1.1 : 其实最大的区别就在于HTTP1.0是非持续性连接,HTTP1.1是持续性连接
HTTP1.0 : HTTP1.0是非持续性连接,代表客户端每请求一个文档,就必须要建立一次新的连接,而每建立一个连接就需要至少消耗2*RTT时间,此外还需要占用TCP连接带来的缓存消耗
HTTP1.1 : HTTP1.1是持续性连接,解决了HTTP1.0占用过多的资源和消耗太多的时间问题,所谓的持续性连接就是当服务器发送完响应后,会在一段时间内保持这一条连接,如果在时间内客户端又再向该服务器端发送请求,那么客户端可以直接将请求报文传送到服务器端不需要再重新建立一次TCP连接
4. 持续性连接的方法
4.1 非流水线方式 : 就是客户端在收到响应后才会发送下一个请求,即客户每访问一次对象只花费一个往返时间的RTT,节省了每再一次访问对象时建立TCP连接的两个RTT,但非流水线的缺点在于当服务器回传响应到客户端接受响应这段时间TCP连接是空闲的,会浪费服务器资源
4.2 流水线方式 : 就是在客户端收到响应之前一直将请求发送出去,即客户访问所有对象只会花费一个往返时间的RTT,而服务器接收到请求后,就可以一个接着一个的连续发送响应报文给客户端
5. 代理服务器(万维网高速缓存)
5.1 概述 : 代理服务器是一个网络实体,会把最近的一些请求和响应暂存在本机磁盘中,当新请求到达时,如果发现新的请求和该暂时存放的请求想同,则会直接返回响应,这个新的请求就不会再去互联网上找资源了
5.2 工作过程 :
-
当一个客户端要向互联网的服务器发送请求时,先和代理服务器建立TCP连接,并向代理服务器发送HTTP请求报文
-
代理服务器收到请求后,如果代理服务器已经暂存了该请求的响应,则直接回传HTTP响应报文给客户端
-
如果代理服务器的暂存没有该请求的响应,则代理服务器就代替客户端向互联网上的服务器建立TCP连接然后发送HTTP请求报文,服务器端将请求的对象以HTTP响应报文返回给代理服务器
-
代理服务器收到响应后,先将该响应的对象暂存在自己的本地存储器,然后再将这个响应通过已经建立的TCP连接返回给请求该对象的客户端
6. HTTP报文结构
6.1 概述: HTTP报文分为 请求报文和响应报文,两种报文的格式都为 开始行+首部行+实体主体,其中请求报文的开始行称为请求行,响应报文的开始行称为状态行
开始行 : 用来区分是请求报文还是响应报文,开始行的三个字段之间都用空格隔开,最后的CRLF代表回车换行
首部行 : 用来表示客户端(浏览器)、服务器或报文主体的信息,可能不止一行
实体主体 : 在请求报文中通常不会使用这个字段,在响应报文中有时后也没有使用到这个字段
6.2 请求报文 : 即客户向服务器发送请求报文,不废话直接上图

请求行 : 方法+URL+版本号 (并且三个字段间用空格分开) ex: GET http://www.baidu.com…/…/…/… HTTP/1.1
首部行 :
HOST : 代表主机的域名位置
Connection : close => 表示告诉服务器发送完请求的文档就可以释放连接了
User-Angent : Mozilla/5.0 =>表示用户代理使用火狐浏览器
Accept-Language: cn =>表示希望优先得到中文的文档
注意:首部行后还有一个空格,这里没有显示出来是因为使用了GET方法,没有实体主体,因此看不出来,后面会详细介绍各种方法
6.2.1 常见的请求报文方法: 请求行以方法为开始,方法用来告诉服务器如何做,最常见的四种方法为 GET、POST、PUT、DELET,可以理解成,对于URL所指定的资源做出查、改、增、删四个动作,因此,GET一般用于获取或者查找该URL指定的资源,POS一般用于更新资源的信息
GET : 向特定的资源发出请求,并取得该特定资源 (查)
POST : 向特定的资源提交数据进行处里(如提交表单或者上传文件),数据包含在请求中。(改)
PUT : 向指定的资源位置上传最新内容 (增)
DELET : 请求服务器删除指定的资源 (删)
OPPTIONS : 返回一些如服务器针对特定资源所支持的HTTP方法等
HEAD : 和GET相同,但返回的响应只有HTTP报头,不返回文档主题
TRACE : 返回服务器收到的请求,通常用于测试或诊断
CONNECT : HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
6.2.2 GET 和 POST 区别 : 相信在面经和面试的时候常常碰到这题
- GET的数据参数是暴露在开始行的URL后(把数据放置在HTTP协议头中以?分隔,以&连接参数),而POST的数据参数则是在实体主体中
=> POST方法相对安全的多,因为GET方法的数据可以直接在URL上获取,但相反的GET方法的效率更高 - 因为每一个浏览器对于URL长度的限制不同但都有一定限制,因此,GET请求对于传参数量有一定限制,而POST请求没有
- GET请求只支持url编码,而POST没有限制
- GET请求有缓存,而POST没有 => GET请求的参数会保存在浏览器的历史记录内,而POST不会
- 浏览器在发送get请求时会将header和data一起发送给服务器,服务器返回200状态码,而在发送post请求时,会先将header发送给服务器,服务器返回100,之后再将data发送给服务器,服务器返回200 OK
6.3 响应报文 : 即服务器向客户回传的回答,不废话直接上图

状态行 : 版本+状态码+短语(负责解释该状态码的短语) ex: HTTP/1.1 202 Accepted
6.3.1 5种状态码 :
1XX : 表示通知信息,如收到请求了或正在进行处里
2XX : 表示成功,如接受或知道了
ex : HTTP/1.1 202 Accepted =>接受
3XX : 表示重定向,如要完成请求必须进行哪一步
ex : HTTP/1.1 301 Move Permanently
Location: http://…XXXXX =>表示请求的资源已经转移需要重新向Location的URL请求资源
4XX : 表示用户的错误,如错误的请求或者语法错误
ex : HTTP/1.1 400 Bad Request =>错误请求
HTTP/1.1 404 Not Found =>找不到(被请求的对象不在服务器上)
5XX : 表是服务器的错误,如服务器失效没办法完成请求
6.3.2 常见的状态码
200 : 请求成功,信息返回在响应报文中
202 : 接受请求
301 : 请求对象已经永久转移,新的URL定义在响应报文首部行的Location中,客户软件(浏览器)会自动跳转
400 : 通用错误码,请求不被服务器理解
404 : 被请求的对象不再服务器上
501 : 服务器不支持请求报文使用的HTTP版本(即服务器无法识别请求的方法)
7. cookie
7.1 概述 : 我们知道http是无状态的协议,但我们可以发现,往往我们在登入页面,网页会自动的记录我们曾经输入过的账号密码,又或者当我们搜索淘宝时,很多时候淘宝会推荐我们最近在搜索的商品,明明是无状态的HTTP协议却可以记住用户曾经的信息,这个背后就是因为有了Cookie, 浏览器可以透过万维网使用Cookie来记住服务器和客户之间的状态信息。
7.2 工作原理 :
- 当现在有一浏览器A浏览某个使用Cookie的网站服务器B时,B就会先为A产生一个唯一的识别码,并在后台的数据库中产生一个项目用来记录这个识别码
- 接着在HTTP响应报文的首部行中,添加一个叫作Set-cookie的首部行(ex : Set-cookie : 31d45978787e07aad42)
- 当A收到HTTP响应报文后,就会在负责管理Cookie的文件夹中,记录B的主机名以及这个唯一的识别号
- 下一次A在访问B时,每发送一个请求时,A会将Cookie以及该识别号加入到请求报文中的首部行(ex : cookie : 31d45978787e07aad42)
- 接着该网站的服务器B就可以继续追中A的状态信息















 8678
8678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









