







在hadoop中,MapReduce计算框架详细过程:

分片:
Hadoop将MapReduce的输入数据划分为等长的小数据块,称为输入分片(input split)或简称“分片”。Hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数从而处理分片中的每条记录。
拥有许多分片,意味着处理每个分片所需要的时间少于处理整个输入数据所花的时间。因此,如果我们并行处理每个分片,且每个分片数据比较小,那么整个处理过程将获得更好的负载平衡,因为一台较快的计算机能够处理的数据分片比一台较慢的计算机更多,且成一定的比例。即使使用相同的机器,失败的进程或其他同时运行的作业能够实现满意的负载平衡,并且如果分片被切分得更细,负载平衡的会更高。
另一方面,如果分片切分得太小,那么管理分片的总时间和构建map任务的总时间将决定作业的整个执行时间。对于大多数作业来说,一个合理的分片大小趋向于HDFS的一个块的大小,默认是64MB,不过可以针对集群调整这个默认值(对新建的所有文件),或对新建的每个文件具体指定。
map任务:
map任务最终将其输出写入本地硬盘,而非HDFS。这是为什么?因为map的输出是中间结果:该中间结果由reduce任务处理后才产生最终输出结果,而且一旦作业完成,map的输出结果就可以删除。因此,如果把它存储在HDFS中并实现备份,难免有些小题大做。如果该节点上运行的map任务在将map中间结果传送给reduce任务之前失败,Hadoop将在另一个节点上重新运行这个map任务以再次构建map中间结果。
map task输出结果首先会进入一个缓冲区内,这个缓冲区的大小是100MB,如果map task内容太大,是很容易撑爆内存的,所以会有一个守护进程,每当缓冲区到达上限80%的时候,就会启动一个Spill(溢写)进程,它的作用是把内存里的map task的结果写入到磁盘。这里值得注意的是,溢写程序是单独的一个进程,不会影响map task的继续输出。当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
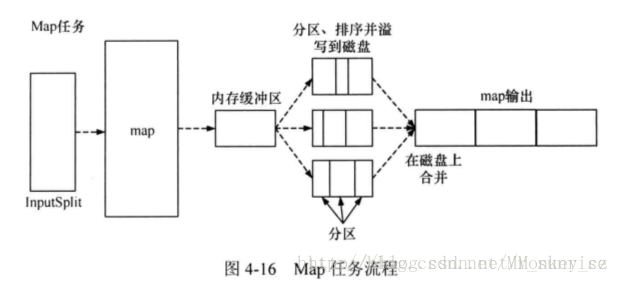
reduce任务:
reduce任务并不具备数据本地化的优势——单个reduce任务的输入通常来自于所有mapper的输出。在本例中,我们仅有一个reduce任务,其输入是所有map任务的输出。因此,排过序的map输出需通过网络传输发送到运行reduce任务的节点。数据在reduce端合并,然后由用户定义的reduce函数处理。reduce的输出通常存储在HDFS中以实现可靠存储。对于每个reduce输出的HDFS块,第一个副本存储在本地节点上,其他副本存储在其他机架节点中。因此,将reduce的输出写入HDFS确实需要占用网络带宽,但这与正常的HDFS流水线写入的消耗一样。
shuffle:
reduce任务的数量并非由输入数据的大小决定,而事实上是独立指定的。如果有好多个任务,每个map任务就会针对输出进行分区(partition),即为每个reduce任务建一个分区。每个分区有许多键(及其对应的值),但每个键对应的键/值对记录都在同一分区中。分区由用户定义的partition函数控制,但通常用默认的partitioner通过哈希函数来分区,很高效。
一般情况下,多个reduce任务的数据流如下图所示。这也就表明了为什么map任务和reduce任务之间的数据流称为shuffle(混洗),因为每个reduce任务的输入都来自许多map任务。shuffle一般比图中所示的更复杂,而且调整混洗参数对作业总执行时间的影响非常大。
- Copy过程: Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
- 有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
- Merge: 这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
- Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当Reducer的输入文件已定,整个Shuffle才最终结束。

combiner函数
集群上的可用带宽限制了
MapReduce作业的数量,因此尽量避免map和reduce任务之间的数据传输是有利的。Hadoop允许用户针对map任务的输出指定一个combiner(就像mapper和reducer)——combiner函数的输出将作为reduce函数的输入。由于combiner属于优化方案,所以Hadoop无法确定要对map任务输出记录调用多少次combiner(如果需要)。换而言之,不管调用combiner多少次,0次、1次或多次,reducer的输出结果都是一样的。
combiner的规则制约着可用的函数类型。这里最好用一个例子来说明。假设一个计算最高气温的例子,1950年的读数由两个map任务处理(因为它们在不同的分片中)。假设第一个map的输出如下:
(1950, 0)
(1950, 20)
(1950, 10)
第二个
map的输出如下:
(1950, 25)
(1950, 15)
reduce函数被调用时,输入如下:
(1950, [0, 20, 10, 25, 15])
因为
25为该列数据中最大的,所以它的输出如下:
(1950, 25)
我们可以像使用
reduce函数那样,使用combiner找出每个map任务输出结果中的最高气温。如此一来,reduce函数调用时将被传入以下数据:
(1950, [20, 25])
Reduce输出的结果和以前一样。更简单地说,我们可以通过下面的表达式来说明气温数值的函数调用:
max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
并非所有函数都具有该属性。例如,如果我们计算平均气温,就不能用平均数作为
combiner,因为
mean(0, 20, 10, 25, 15) = 14
但是
combiner不能取代reduce函数:
mean(mean(0, 20, 10), mean(25, 15)) = mean(10, 20) = 15
为什么呢?我们仍然需要reduce函数来处理不同map输出中具有相同键的记录。但它能有效减少mapper和reducer之间的数据传输量,在MapReduce作业中使用combiner函数需要慎重考虑。














 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









