







1.数据流
首先定义一些术语。MapReduce作业(job)是客户端需要执行的一个工作单元:它包括输入数据、MapReduce程序和配置信息。Hadoop将作业分成若干个小任务(task)来执行,其中包括两类任务:map任务和reduce任务。
Hadoop将MapReduce的输入数据划分为等长的小数据块,称为输入分片(input split)或简称“分片”。Hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数从而处理分片中的每条记录。
拥有许多分片,意味着处理每个分片所需要的时间少于处理整个输入数据所花的时间。因此,如果我们并行处理每个分片,且每个分片数据比较小,那么整个处理过程将获得更好的负载平衡,因为一台较快的计算机能够处理的数据分片比一台较慢的计算机更多,且成一定的比例。即使使用相同的机器,失败的进程或其他同时运行的作业能够实现满意的负载平衡,并且如果分片被切分得更细,负载平衡的会更高。
另一方面,如果分片切分得太小,那么管理分片的总时间和构建map任务的总时间将决定作业的整个执行时间。对于大多数作业来说,一个合理的分片大小趋向于HDFS的一个块的大小,默认是64MB,不过可以针对集群调整这个默认值(对新建的所有文件),或对新建的每个文件具体指定。
Hadoop在存储有输入数据(HDFS 中的数据)的节点上运行map任务,可以获得最佳性能。这就是所谓的“数据本地化优化”(data locality optimization),因为它无需使用宝贵的集群带宽资源。但是,有时对于一个map任务的输入来说,存储有某个HDFS数据块备份的三个节点可能正在运行其他map任务,此时作业调度需要在三个备份中的某个数据寻求同个机架中空闲的机器来运行该map任务。仅仅在非常偶然的情况下(该情况基本上不会发生),会使用其他机架中的机器运行该map任务,这将导致机架与机架之间的网络传输。下图显示这三种可能性:
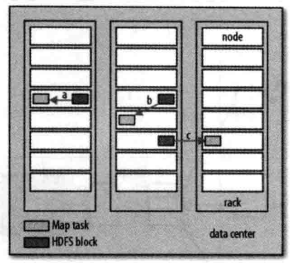
现在我们应该清楚为什么最佳分片的大小应该与块大小相同:因为它是确保可以存储在单个节点上的最大输入块的大小。如果分片跨越两个数据块,那么对于任何一个HDFS节点,基本上都不可能同时存储这两个数据块,因此分片中的部分数据需要通过网络传输到map任务节点。
map任务将其输出写入本地硬盘,而非HDFS。这是为什么?因为map的输出是中间结果:该中间结果由reduce任务处理后才产生最终输出结果,而且一旦作业完成,map的输出结果就可以删除。因此,如果把它存储在HDFS中并实现备份,难免有些小题大做。如果该节点上运行的map任务在将map中间结果传送给reduce任务之前失败,Hadoop将在另一个节点上重新运行这个map任务以再次构建map中间结果。
reduce任务并不具备数据本地化的优势——单个reduce任务的输入通常来自于所有mapper的输出。在本例中,我们仅有一个reduce任务,其输入是所有map任务的输出。因此,排过序的map输出需通过网络传输发送到运行reduce任务的节点。数据在reduce端合并,然后由用户定义的reduce函数处理。reduce的输出通常存储在HDFS中以实现可靠存储。对于每个reduce输出的HDFS块,第一个副本存储在本地节点上,其他副本存储在其他机架节点中。因此,将reduce的输出写入HDFS确实需要占用网络带宽,但这与正常的HDFS流水线写入的消耗一样。
一个reduce任务的完整数据流如下图所示,虚线框表示节点,虚线箭头表示节点内部的数据传输,而实线箭头表示不同节点之间的数据传输:
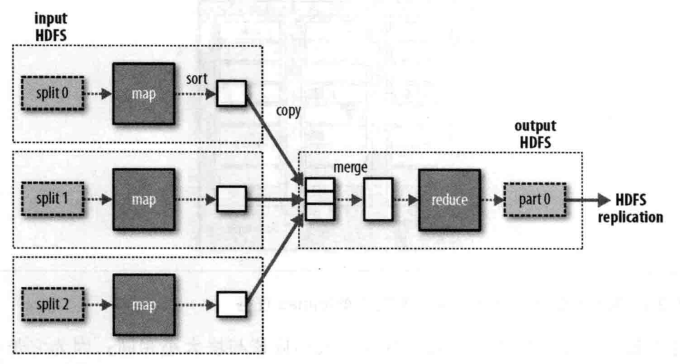
reduce任务的数量并非由输入数据的大小决定,而事实上是独立指定的。如果有好多个任务,每个map任务就会针对输出进行分区(partition),即为每个reduce任务建一个分区。每个分区有许多键(及其对应的值),但每个键对应的键/值对记录都在同一分区中。分区由用户定义的partition函数控制,但通常用默认的partitioner通过哈希函数来分区,很高效。
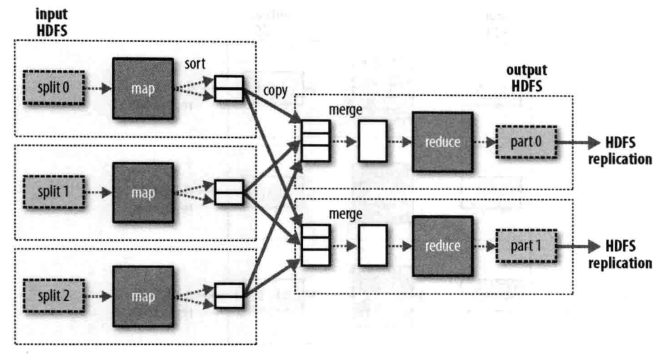
一般情况下,多个reduce任务的数据流如下图所示。这也就表明了为什么map任务和reduce任务之间的数据流称为shuffle(混洗),因为每个reduce任务的输入都来自许多map任务。shuffle一般比图中所示的更复杂,而且调整混洗参数对作业总执行时间的影响非常大。
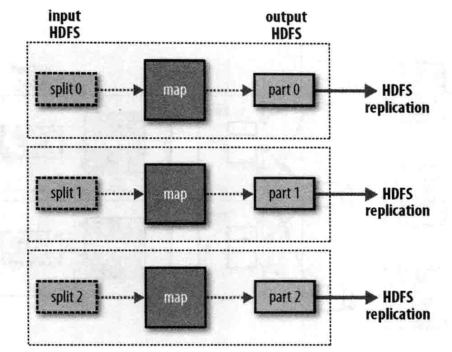
最后,当数据处理可以完全并行,即无需混洗时,可能会出现无reduce任务的情况。在这种情况下,唯一的非本地节点数据传输是map任务将结果写入HDFS(参见下图)。
2.combiner函数
集群上的可用带宽限制了MapReduce作业的数量,因此尽量避免map和reduce任务之间的数据传输是有利的。Hadoop允许用户针对map任务的输出指定一个combiner(就像mapper和reducer)——combiner函数的输出将作为reduce函数的输入。由于combiner属于优化方案,所以Hadoop无法确定要对map任务输出记录调用多少次combiner(如果需要)。换而言之,不管调用combiner多少次,0次、1次或多次,reducer的输出结果都是一样的。
combiner的规则制约着可用的函数类型。这里最好用一个例子来说明。假设一个计算最高气温的例子,1950年的读数由两个map任务处理(因为它们在不同的分片中)。假设第一个map的输出如下:
(1950, 0)
(1950, 20)
(1950, 10)
第二个map的输出如下:
(1950, 25)
(1950, 15)
reduce函数被调用时,输入如下:
(1950, [0, 20, 10, 25, 15])
因为25为该列数据中最大的,所以它的输出如下:
(1950, 25)
我们可以像使用reduce函数那样,使用combiner找出每个map任务输出结果中的最高气温。如此一来,reduce函数调用时将被传入以下数据:
(1950, [20, 25])
Reduce输出的结果和以前一样。更简单地说,我们可以通过下面的表达式来说明气温数值的函数调用:
max(0, 20, 10, 25, 15) = max(max(0, 20, 10), max(25, 15)) = max(20, 25) = 25
并非所有函数都具有该属性。例如,如果我们计算平均气温,就不能用平均数作为combiner,因为
mean(0, 20, 10, 25, 15) = 14
但是combiner不能取代reduce函数:
mean(mean(0, 20, 10), mean(25, 15)) = mean(10, 20) = 15
为什么呢?我们仍然需要reduce函数来处理不同map输出中具有相同键的记录。但它能有效减少mapper和reducer之间的数据传输量,在MapReduce作业中使用combiner函数需要慎重考虑。















 2478
2478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









