









翻译这篇文章的目的是为了让读者们更好的理解spark读取parquet的原理
一个row group 是读取parquet的不可分的最小单元,并且你会以为由spark创建的task数量不会多于在parquet数据源中的row groups的数量 但是spark却可以创建出多余row groups个数的task,让我们看看怎么回事
任务计划
一般来说,为了知道有多少个task数量,我们就必须去每一个parquet文件的footer以便于知道row groups的个数,但是这种操作是比较昂贵的,尤其是在云存储中,如,在运行任务之前,需要从S3中打开读取3000到5000个parquet文件的footer,这在任务启动之前将会是持续好几分钟。
但是为了加速任务的执行,我们采用了估算task的任务数,这样就无需读取parquet footer。
首先,spark先列举data source的文件数,获取总的大小,虽然在云存储中文件列举不是很快,但是至少比打开读取每个文件要快很多:
totalBytes = sum(fileSize + conf("spark.sql.files.openCostInBytes"))
注意,spark添加了spark.sql.files.openCostInBytes(默认是4M)到每个文件的大小中。
然后定义能够并行处理多少字节,并且考虑默认的并行度:
bytesPerCore = totalBytes / conf("spark.default.parallelism")
最后,spark把spark.sql.files.maxPartitionBytes和bytesPerCore的最小值作为每个任务的可以运行的数据大小:
maxSplitBytes = min(conf("spark.sql.files.maxPartitionBytes"), bytesPerCore)
并且spark会输出计算出的数据大小日志,如下:
logInfo(s"Planning scan with bin packing, max size: $maxSplitBytes bytes, " +
s"open cost is considered as scanning $openCostInBytes bytes.")
这样,spark获取到maxSplitBytes,并且通过这个值在所有文件的迭代计算从而分配task的数量。
例如,假如有三个parquet文件(只有4个row groups):
file1.parquet 368,565,268 (with 2 row groups)
file2.parquet 46,584,043 (with 1 row group)
file3.parquet 107,315,179 (with 1 row group)
这样,
totalBytes = 368,565,268 + 46,584,043 + 107,315,179 + 3 * 4,194,304 = 535,047,402
-- 2 executor instances with 4 cores means default parallelism is 8 in my test
bytesPerCore = totalBytes / 8 = 66,880,925
maxSplitBytes = min(134,217,728; 66,880,925) = 66,880,925
在spark driver端会有只有的日志:
21/03/07 17:03:58 main INFO FileSourceScanExec: Planning scan with bin packing,
max size: 66880925 bytes, open cost is considered as scanning 4194304 bytes.
这样将会分配9个task:
21/03/07 17:03:58 dag-scheduler-event-loop INFO DAGScheduler: Got job 0
(performDistributedWrite at SqlWrapper.scala:70) with 9 output partitions
21/03/07 17:03:58 dag-scheduler-event-loop INFO YarnScheduler:
Adding task set 0.0 with 9 tasks
为什么是9个task呢?Spark迭代所有的文件,并且检查在 每个文件上根据maxSplitBytes来分配task的数量:
file1.parquet 368,565,268 - 6 tasks
file2.parquet 46,584,043 - 1 task
file3.parquet 107,315,179 - 2 tasks
通过以上可以看到spark无需读取parquet文件,无需知道数据源中的实际的row groups的任务,就可以计算出task的数量
默认的并行度
我们可以注意到task的数量不仅仅依赖于数据源的大小,也依赖于默认的并行度。
在yarn下,假如没有指定(–conf spark.default.parallelism),默认的并行度取决于executor的实例数和core数:
default_parallelism = conf("spark.executor.instances") * conf("spark.executor.cores")
例如,当我们显示指定 --conf spark.default.parallelism=30,对于同样的三个parquet source文件,我们将会得到30任务
21/03/08 15:31:52 main INFO FileSourceScanExec: Planning scan with bin packing,
max size: 17834913 bytes, open cost is considered as scanning 4194304 bytes.
21/03/08 15:31:52 dag-scheduler-event-loop INFO YarnScheduler:
Adding task set 0.0 with 30 tasks
注意maxSplitBytes变成了17,834,913字节
row group的分配和空任务
好了,无论多少个任务被创建了出来,这个row group一直是parquet读取的最小单元,多个任务不能同时处理同一个row group。
并且每个任务需要知道每个文件中实际parquet row group的边界(offset和length),而不是通过以上计算出来的抽象的边界。
就像我们之前注意到的一样,在我们的测试中,这里将会有9个task去读取3个parquet文件:
21/03/19 05:23:49 INFO YarnScheduler: Adding task set 0.0 with 9 tasks
21/03/19 05:23:49 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (executor 1, partition 0, ...)
21/03/19 05:23:49 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (executor 2, partition 1, ...)
21/03/19 05:23:49 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (executor 1, partition 2, ...)
21/03/19 05:23:49 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (executor 2, partition 3, ...)
21/03/19 05:23:49 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (executor 1, partition 4, ...)
21/03/19 05:23:49 INFO TaskSetManager: Starting task 5.0 in stage 0.0 (executor 2, partition 5, ...)
21/03/19 05:23:49 INFO TaskSetManager: Starting task 6.0 in stage 0.0 (executor 1, partition 6, ...)
21/03/19 05:23:49 INFO TaskSetManager: Starting task 7.0 in stage 0.0 (executor 2, partition 7, ...)
21/03/19 05:23:55 INFO TaskSetManager: Starting task 8.0 in stage 0.0 (executor 1, partition 8, ...)
观察Spark的Executor日志,我们能够看到文件的范围分配:
21/03/19 05:23:53 Executor task launch worker for task 2 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file1.parquet, range: 133761850-200642775
21/03/19 05:23:53 Executor task launch worker for task 4 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file1.parquet, range: 267523700-334404625
21/03/19 05:23:53 Executor task launch worker for task 6 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file2.parquet, range: 0-46584043
21/03/19 05:23:53 Executor task launch worker for task 0 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file1.parquet, range: 0-66880925
21/03/19 05:23:55 Executor task launch worker for task 8 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file1.parquet, range: 334404625-368565268
Executor 2:
21/03/19 05:23:53 Executor task launch worker for task 1 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file1.parquet, range: 66880925-133761850
21/03/19 05:23:53 Executor task launch worker for task 7 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file3.parquet, range: 66880925-107315179
21/03/19 05:23:53 Executor task launch worker for task 3 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file1.parquet, range: 200642775-267523700
21/03/19 05:23:53 Executor task launch worker for task 5 INFO FileScanRDD:
Reading File path: s3://cloudsqale/data/file3.parquet, range: 0-66880925
但是在Spark UI中我们确只能看到4个task在处理数据(在我们的测试中,3个文件只有4个row group),而其他的只是读取0个记录:
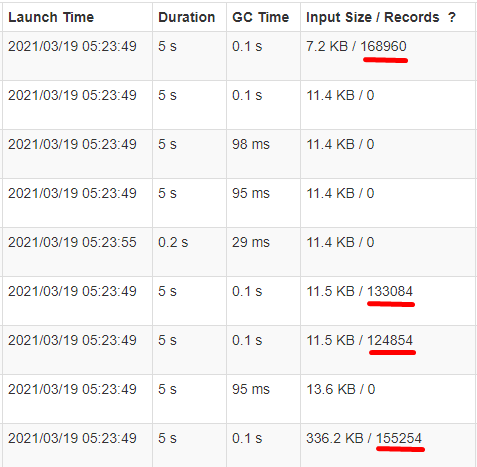
原因是在每个任务读取分配的parquet文件的footer的时候,会获取都一个row groups的列表,并且去检查这个任务分配的数据是否覆盖了row group的中点:
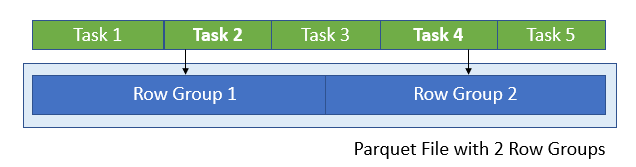
在以上例子中,5个任务被分配去读取一个有2个row groups的parquet文件,但是只有任务2和任务4读取数据,因为他们的数据范围覆盖了row group的中点。
更多的细节,可以参考ParquetFileFormat和 ParquetInputSplit以及org.apache.parquet.format.converterParquetMetadataConverter的filterFileMetaDataByMidpoint方法
所以虽然任务的数量多于row group的数量,但是这些冗余的任务实际上并不读取数据,但是他们都会去读取Parquet文件的footers,从而增加了IO操作,所以理想情况下,task的数量应该不要多于row groups的数量。
本文翻译自Spark – Reading Parquet – Why the Number of Tasks can be Much Larger than the Number of Row Groups


















 474
474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









