







这两天看了很多关于二叉树的资料,遂来写个总结。
1>什么是二叉树?
树:树不同于数组Array以及链表 List ,前面两种都是线性结构。而树是介于线性和非线性之间的半线性结构。实质上就是链表的链表,即一个节点可以发散出多条链表,形成树状结构,如下图:

那么我们如何在计算机中表达这种结构呢?
这里有一种很经典的表示法:长子+兄弟 表示法。
长子+兄弟:每个节点都有:parent域,data域,firstChild长子域,nextSibling兄弟域,这样上图就变成了:
二叉树:
二叉树,顾名思义就是每个节点度,最多为2的树,分别为lChild和rChild。
节点个数 n,与树的高度h之间具有如下关系:
h 小于 n 小于 2^(h+1)可不可以用二叉树表示普通的树?
试着想象一下,把上图用长子兄弟法表示的一课普通的树,每个节点都逆时针旋转45°,是不是就变成一颗二叉树了呢?这也许就是二叉树应用最广的原因吧。
一个二叉树的节点如何在计算机中表示出来呢?
public class BinNode {
/*
* 一个二叉树节点 需要 什么呢?
* 1.数据域 data
* 2.父节点域 parent
* 3.左节点域 lChild
* 4.右节点域 rChild
* 5.节点的高度 height ,用于二叉搜索树
* 6.节点的颜色 color ,用于红黑树 (这里只考虑普通的二叉树)
* */
public BinNode(int data,BinNode parent){
this.data=data;
this.parent=parent;
}
BinNode parent,lChild,rChild;
int data;
int height;
}2>二叉树的遍历算法
- 前序,中序和后序的递归遍历算法
前序:
public void preTraverseRev(BinNode x){
if(x==null){
return;
}
System.out.println(x.data);
traverseRevcursion(x.lChild);
traverseRevcursion(x.rChild);
}中序:
public void inTraverseRev(BinNode x){
if(x==null){
return;
}
traverseRevcursion(x.lChild);
System.out.println(x.data);
traverseRevcursion(x.rChild);
}后序:
public void postTraverseRev(BinNode x){
if(x==null){
return;
}
traverseRevcursion(x.lChild);
traverseRevcursion(x.rChild);
System.out.println(x.data);
}递归的算法,特别简单,但是效率来说,每个递归的空间消耗可能会有栈溢出的风险,所以应该尽量把递归改成迭代形式。
一般来说,尾递归都是可以很轻松转化成迭代形式的,只要把递归语句改成迭代的最后一句就可以了。如:
//递归形式:
int fun(n){
if(n<1)
n=1;
return n*fun(n-1);
}
//迭代形式
int fun(n){
int sum=1;
while(n>0){
sum*=n;
n--;
}
return sum;
}
//求斐波切纳数
//递归
int fib(n){
return (n<2)?n:(fib(n-1)+fib(n-2));
}
//迭代
int fib(n){
int a=0;int b=1;
while(n>0){
b=a+b;
a=b-a;
n--;
}
return b;
}
//这里用到了动态规划的方法,把前一个阶段的值存储起来,用于后一个阶段的计算。- 前序,中序,后序的迭代算法。
前序:
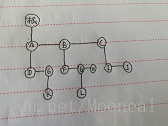
前序遍历的顺序如图所示:
A->B->D->E->F->C
我们能看出什么呢?
A B D 是一条以A为根的链表, E F 是一条以E为根的链表 C是一个以C为根的链表。实际上,我们找到这三个根,实际上就是遍历了整颗树。
但是找寻是有顺序的,A->E->C,A不必说,肯定是先找到的,那么怎么实现E C 的顺序呢,可以注意到,E C分别都是A链元素的右子树,且C 为先,但C又必须后遍历,先入后出,栈!!所以:
public void visitLeftBranch(BinNode x, Stack<BinNode> stack){
while(x!=null){
System.out.println(x.data); //遍历左链上每一个元素
stack.push(x.rChild); //右孩子入栈
x=x.lChild;
}
}
public void traversePreIterator(BinNode x){
Stack<BinNode> stack=new Stack<BinNode>();
//创立一个栈放所有右孩子。用来得到E C并合理其顺序。
while(true){
visitLeftBranch(x, stack);
if(stack.isEmpty())
break;
x=stack.pop();
}
}中序:
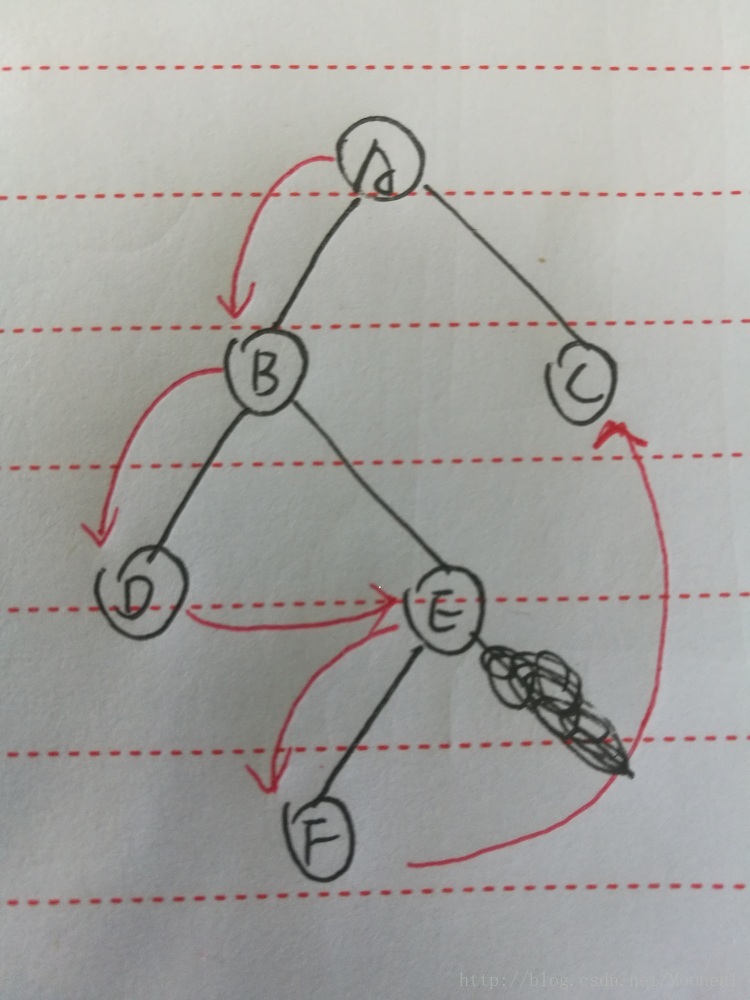
中序遍历的顺序如图:
D->B->F->E->A->C
有了前面前序的基础,这里可以看出:
D B A 是一条链 F E 是一条链 C 是一条链
但是很明显,我们拿到节点的顺序 肯定是 A B D,那么如何反方向遍历呢,依然是 先入后出 栈。而且 可以看出来 F E 在 A 前面,且E C 对于整棵树来说是右子树。所以依然只要找到A E C 就可以遍历整棵树。
public void visitLeftBranch2(BinNode x, Stack<BinNode> stack1){
while(x!=null){
stack1.push(x);
x=x.lChild;
}
}
public void inTraverseIterator(BinNode x){
Stack<BinNode> stack1=new Stack<BinNode>();
while(true){
visitLeftBranch2(x,stack1);
if(stack1.isEmpty())
break;
x=stack1.pop();
System.out.println(x.data);
x=x.rChild; //不管是否有右孩子,假设它有,每次都去检查,如果实际有,那么栈中有增加元素,没有继续出栈。
}
}后序:
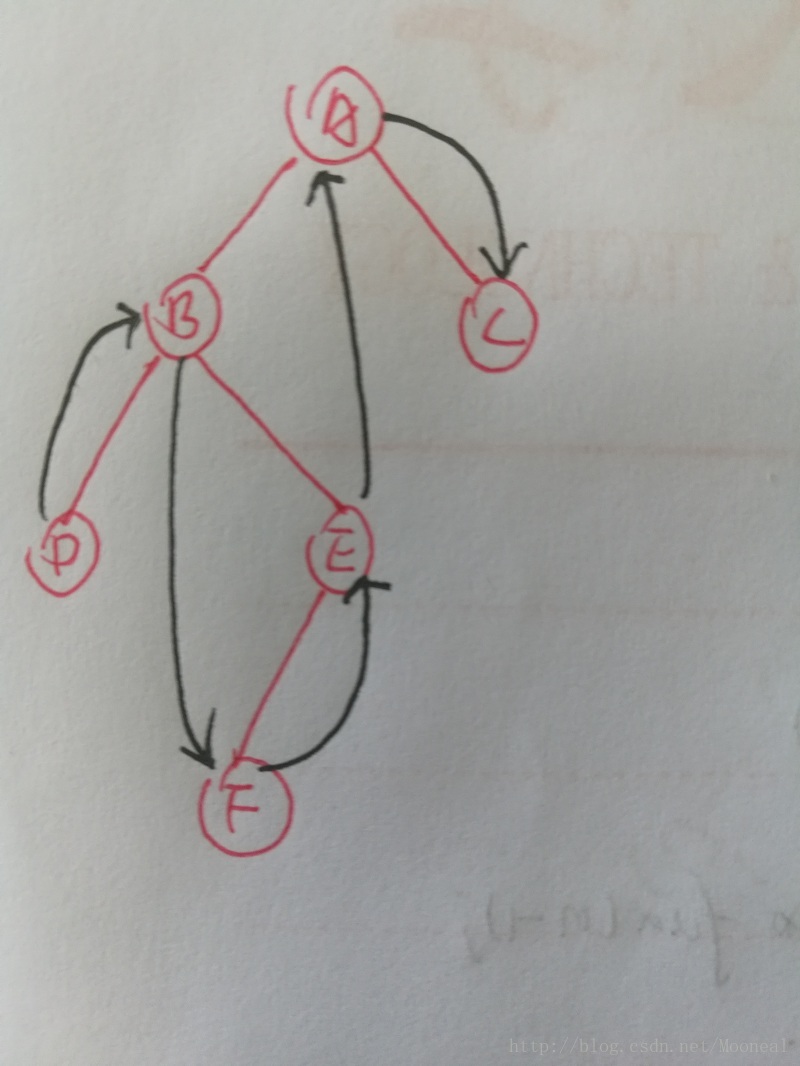
后序遍历的顺序如图:
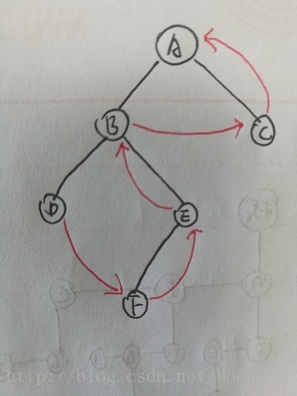
D->F->E->B->C->A
后序遍历是左右根的关系,那么由于首先访问的是A,但A必须最后访问,那依然可以用栈来处理这个问题,关键点是如何让入栈的顺序依我们遍历相反方向呢?
首先,我们可以确定的是,第一个访问的一定是A B D这个链的最左端的右子树(如果存在的话),但不再是依D B A来访问了,而是会先考虑D的兄弟节点E的链的最左端。
那么可以每次把节点的按 根右左 入栈,直到这个链的最左端:
public void leftBranch(Stack<BinNode> stack){
BinNode x=stack.peek();
while(x!=null){
if(x.lchild!=null){ //如果有左孩子,也有右孩子,先右孩子入栈,再左孩子入栈。
if(x.rChild!=null)
stack.push(x.rChild);
stack.push(x.lChild);
}else{
stack.push(x.rChild);
}
x=x.lChild;
}
stack.pop();//因为 终止这个循环 的时候,必定有一个null 入栈。
}public void postTraverse(BinNode x){
Stack<BinNode> stack1=new Stack<BinNode>();
stack1.push(x);
while(!stack1.isEmpty()){
if(stack1.peek()!=x.parent) //因为我们入栈是按照一个节点的根 右 左 来入栈的,如果一个节点的下一个节点不是父节点,那一定是它的兄弟节点。
leftBranch(stack1);
x=stack1.pop();
System.out.println(x.data);
}
}3.层次遍历
层次遍历,顾名思义,一棵树,从上到下,从左到右依次遍历。
这个比前面的好理解,从上到下,从左到右,把每个节点自身和左右节点依次放入队列中,依次出队列就好了。先入的先出。
public void rankTraverse(BinNode x){
Queue<BinNode> q=new LinkedList<BinNode>(); //队列是一种特殊的线性表,只允许在表的前段进行删除操作,在表的后端进行插入操作。
//LinkedList实现了Queue接口,因此可以把这个当Queue用。
q.offer(x);
while(!q.isEmpty()){
x=q.poll();
System.out.println(x.data);
if(x.lChild!=null){
q.offer(x.lChild);
}
if(x.rChild!=null){
q.offer(x.rChild);
}
}
}参考资料:
清华大学 邓俊辉教授的数据结构教材














 87
87

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









