<think>好的,我需要帮助用户完成KNDVI与降水、温度的偏相关分析。首先,用户的数据存储在一个文件地理数据库ABC.gdb中,里面有逐年降水、温度和KNDVI的数据,命名规则是p3_00到p3_22,t3类似,k3同理。目标是将处理后的数据存到GHI.gdb,使用Python 2.7.14和ArcGIS 10.6在ArcMap中实现。
首先,我得确认用户的需求是进行偏相关性分析。偏相关分析需要计算在控制其他变量(比如温度)的情况下,两个变量(如降水和KNDVI)的相关性。但用户提到先处理降水和KNDVI部分,可能暂时不需要控制温度。不过可能需要明确是否需要控制其他变量,或者只是两两的偏相关。根据用户的问题,可能当前只需要两变量的偏相关,但需要进一步确认。不过用户可能将温度的部分放在后续处理,现在先处理降水与KNDVI,所以暂时可以专注于这两个变量。
接下来,用户的数据是时间序列的栅格数据,每年一个栅格,共23年(00到22年)。偏相关分析通常需要计算每个像元的时间序列相关性。因此,需要将每个像元对应的23年的降水值和KNDVI值提取出来,计算它们之间的相关系数,然后用偏相关的公式,或者可能用户实际需要的是普通的皮尔逊相关系数?或者偏相关是指控制其他变量后的相关?这里可能需要进一步澄清,但用户提到“分别的偏相关性分析”,可能是指分别对降水和温度与KNDVI做偏相关,而每个分析中控制另一个变量?例如,分析降水与KNDVI的偏相关时控制温度的影响,反之亦然。如果是这样,那么需要三个变量的时间序列数据,每个像元上计算偏相关系数。
但用户现在希望先处理降水和KNDVI的部分。假设用户需要的是普通的相关系数,而不是偏相关系数,或者可能用户有误解。但根据问题描述,用户明确提到“偏相关性分析”,因此必须考虑控制另一个变量。比如,在分析降水与KNDVI的偏相关时,需要控制温度的影响。但用户目前的数据可能只有降水、温度、KNDVI各自的年数据。因此,每个像元上,有23年的降水、温度、KNDVI值。对于偏相关系数,计算的是在控制第三个变量(如温度)的情况下,两个变量(降水和KNDVI)的相关性。因此,代码需要处理三个变量,但用户可能现在先处理降水和KNDVI的偏相关,可能暂时不考虑温度?或者可能用户想分别做降水与KNDVI的偏相关(控制温度)和温度与KNDVI的偏相关(控制降水)。但根据用户的描述,现在要做第一部分,即年均降水和年均KNDVI的偏相关分析。因此,可能需要同时处理三个变量,但在当前步骤中只关注降水和KNDVI,控制温度。或者可能用户误解了偏相关,实际上只需要两变量的相关?需要明确这一点。
如果用户确实需要偏相关,那么必须计算三个变量之间的关系。例如,使用线性回归的方法,先对降水和KNDVI分别对温度进行回归,得到残差,然后计算残差之间的相关系数。这就是偏相关系数的计算方法。具体步骤可能包括:
1. 对于每个像元,建立降水对温度的回归模型,得到残差P_residual。
2. 建立KNDVI对温度的回归模型,得到残差K_residual。
3. 计算P_residual和K_residual的相关系数,即偏相关系数。
因此,在代码中需要处理这三个变量的时间序列数据。但根据用户的当前问题,可能现在只需要处理降水和KNDVI,但如果没有温度的数据参与,就无法计算偏相关。因此,这里可能存在理解上的偏差,需要确认用户是否在第一步需要控制温度。根据用户的原始问题,可能用户希望分别进行降水与KNDVI、温度与KNDVI的偏相关分析,而每个分析中控制另一个变量。例如,降水与KNDVI的偏相关控制温度,温度与KNDVI的偏相关控制降水。因此,在第一步处理降水与KNDVI的偏相关时,需要温度的数据。
但用户的数据存储中,降水、温度、KNDVI都是按年份存储的。因此,需要将同一年的三个变量的栅格进行处理。例如,对于2000年,有p3_00,t3_00,k3_00三个栅格,依此类推。
现在,用户希望用Python代码在ArcGIS环境中处理。由于用户使用的是ArcGIS 10.6和Python 2.7,需要使用ArcPy模块来进行处理。可能的步骤包括:
1. 遍历每年的降水、温度、KNDVI数据,整理成时间序列的立方体。
2. 对每个像元,提取23年的降水、温度、KNDVI值。
3. 对每个像元计算降水与KNDVI的偏相关系数(控制温度)。
4. 将结果输出为栅格。
不过,ArcPy本身可能没有直接的函数来计算偏相关系数,因此需要自己实现。或者可以使用栅格计算器,但处理时间序列可能比较复杂。
另一种方法是将每个像元的时间序列数据提取出来,进行统计计算,然后将结果保存为栅格。这可以通过创建多维栅格或者使用Python的数组处理库(如numpy)来实现,但需要处理大量的数据,可能会遇到内存问题。
可能的解决方案:
1. 使用ArcPy的Point对象逐个像元读取数据,但这种方法效率极低,对于大范围高分辨率数据不可行。
2. 将每个年份的栅格转换为数组,然后将所有年份的数据堆叠成三维数组(时间 x 行 x 列),然后进行逐像元的计算。这需要使用NumPy库,并且需要足够的内存来存储所有数据。
3. 利用ArcGIS的影像分析工具,例如使用波段合成(Composite Bands)来创建多维栅格,但可能不够灵活。
考虑到数据量的问题,假设用户的栅格数据较大(250m分辨率,范围可能较大),逐像元处理可能会非常耗时。因此,需要寻找高效的数组处理方法。
具体步骤可能如下:
1. 读取所有年份的降水、温度、KNDVI栅格数据,并将它们转换为NumPy数组。
2. 将每个变量的数组堆叠成一个时间序列的三维数组。
3. 对每个像元位置,提取该位置的时间序列(三个变量的23年数据)。
4. 计算偏相关系数(需要排除无效值,如NoData)。
5. 将结果保存为新的栅格。
但ArcPy中处理大量数组可能比较困难,因为需要将整个栅格读入内存,这可能导致内存不足。因此,可能需要分块处理。
另一个问题是,用户的数据存储在文件地理数据库(GDB)中,而ArcPy可以读取这些数据,但需要正确的路径和名称。
现在,需要编写具体的代码步骤:
首先,用户的数据路径是D:\Gisdata\ABC.gdb,输出到D:\Gisdata\GHI.gdb。需要确保输出GDB存在,否则需要创建。
步骤:
1. 导入arcpy模块,设置环境参数,如工作空间、输出坐标系统、像元大小、处理范围等,以确保输出栅格与输入一致。
2. 列出输入GDB中的所有降水、温度、KNDVI栅格,并按年份排序,确保顺序正确(00到22年对应2000到2022年)。
3. 将每个变量的栅格按时间顺序堆叠成多维数组。
4. 对于每个像元位置,计算降水与KNDVI的偏相关系数,控制温度的影响。
5. 将结果保存到输出GDB中。
但具体如何实现这些步骤需要详细考虑。例如,如何将多个栅格转换为数组,并堆叠起来?
可能的代码结构:
```python
import arcpy
import numpy as np
from scipy import stats
# 设置环境
arcpy.env.workspace = "D:/Gisdata/ABC.gdb"
out_gdb = "D:/Gisdata/GHI.gdb"
arcpy.env.overwriteOutput = True
# 确保输出GDB存在
if not arcpy.Exists(out_gdb):
arcpy.CreateFileGDB_management("D:/Gisdata", "GHI.gdb")
# 获取所有降水、温度、kndvi的栅格名称,并按年份排序
precip_list = sorted([f for f in arcpy.ListRasters() if f.startswith('p3_')])
temp_list = sorted([f for f in arcpy.ListRasters() if f.startswith('t3_')])
kndvi_list = sorted([f for f in arcpy.ListRasters() if f.startswith('k3_')])
# 确保三个列表长度一致且正确对应年份
assert len(precip_list) == len(temp_list) == len(kndvi_list) == 23, "数据年份不完整"
# 获取第一个栅格的描述信息,用于后续创建输出栅格
desc = arcpy.Describe(precip_list[0])
extent = desc.extent
sr = desc.spatialReference
cell_size = desc.meanCellWidth
# 读取所有栅格数据为数组
def read_rasters_to_array(raster_list):
arrays = []
for raster in raster_list:
arr = arcpy.RasterToNumPyArray(raster, nodata_to_value=np.nan)
arrays.append(arr)
return np.stack(arrays, axis=2) # 形状为(行, 列, 时间)
precip_array = read_rasters_to_array(precip_list)
temp_array = read_rasters_to_array(temp_list)
kndvi_array = read_rasters_to_array(kndvi_list)
# 初始化结果数组
rows, cols, _ = precip_array.shape
result = np.full((rows, cols), np.nan)
# 遍历每个像元
for i in range(rows):
for j in range(cols):
# 提取该像元的时间序列
p = precip_array[i, j, :]
t = temp_array[i, j, :]
k = kndvi_array[i, j, :]
# 检查是否有无效值
valid = ~np.isnan(p) & ~np.isnan(t) & ~np.isnan(k)
if np.sum(valid) < 3: # 至少需要3个样本来计算偏相关
continue
# 提取有效数据
p_valid = p[valid]
t_valid = t[valid]
k_valid = k[valid]
# 计算偏相关系数:p和k,控制t
# 方法:计算p和k在回归去除t影响后的残差的相关系数
# 回归p ~ t + intercept
X = np.column_stack([t_valid, np.ones_like(t_valid)])
coeff_p, _, _, _ = np.linalg.lstsq(X, p_valid, rcond=None)
p_pred = np.dot(X, coeff_p)
p_resid = p_valid - p_pred
# 回归k ~ t + intercept
X_k = np.column_stack([t_valid, np.ones_like(t_valid)])
coeff_k, _, _, _ = np.linalg.lstsq(X_k, k_valid, rcond=None)
k_pred = np.dot(X_k, coeff_k)
k_resid = k_valid - k_pred
# 计算残差的相关系数
if len(p_resid) < 2:
continue
r, p_value = stats.pearsonr(p_resid, k_resid)
result[i, j] = r
# 将结果数组转换为栅格
result_raster = arcpy.NumPyArrayToRaster(
result,
arcpy.Point(extent.XMin, extent.YMin),
cell_size, cell_size,
value_to_nodata=np.nan
)
# 设置空间参考
arcpy.DefineProjection_management(result_raster, sr)
# 保存到输出GDB
output_path = arcpy.os.path.join(out_gdb, "Partial_Corr_P_KNDVI")
result_raster.save(output_path)
print("处理完成,结果保存在:{}".format(output_path))
```
这段代码的思路是将所有年份的数据读取为三维数组(行,列,时间),然后逐个像元计算偏相关系数。对于每个像元,提取降水、温度、KNDVI的时间序列,排除无效值,然后进行回归分析,得到残差,再计算残差的相关系数。最后将结果保存为栅格。
可能存在的问题:
1. 内存问题:如果栅格很大(比如全国范围,250m分辨率),三维数组可能会占用大量内存,导致程序崩溃。例如,假设栅格有10000行×10000列,每个数组有23层,数据类型为float32,那么每个数组的大小是10000×10000×23×4 bytes ≈ 8.6 GB。三个这样的数组将占用约25.8 GB内存,这对普通计算机来说可能无法承受。
2. 处理时间:逐像元循环在Python中非常慢,尤其是对于大栅格。可能需要寻找向量化操作或分块处理的方法。
3. 缺少Scipy库:ArcGIS 10.6自带的Python 2.7可能没有安装Scipy,使用stats.pearsonr会报错。需要确保Scipy可用,或者手动实现Pearson相关系数。
针对这些问题,可能的解决方案:
1. 分块处理:将栅格分成小块,逐块读取和处理,减少内存占用。
2. 避免使用Scipy,手动计算相关系数。例如,Pearson相关系数可以用公式计算:
$$ r = \frac{\sum (x - \bar{x})(y - \bar{y})}{\sqrt{\sum (x - \bar{x})^2} \sqrt{\sum (y - \bar{y})^2}} $$
3. 使用NumPy的向量化操作代替循环,但处理三维数组可能比较复杂。
修改后的代码可能需要手动计算相关系数,并分块处理。例如:
手动计算Pearson相关系数:
```python
def pearson_corr(x, y):
# x和y是一维数组,长度相同,且已经排除无效值
n = len(x)
sum_x = np.sum(x)
sum_y = np.sum(y)
sum_xy = np.sum(x * y)
sum_x2 = np.sum(x**2)
sum_y2 = np.sum(y**2)
numerator = sum_xy - (sum_x * sum_y) / n
denominator = np.sqrt((sum_x2 - sum_x**2 / n) * (sum_y2 - sum_y**2 / n))
if denominator == 0:
return np.nan
return numerator / denominator
```
然后在循环中调用这个函数,而不是stats.pearsonr。
另外,关于分块处理,可能需要将整个栅格分成较小的块(如256x256),逐块读取、处理、写入。这需要使用arcpy的Raster对象的分块功能,或者手动计算块的位置。
此外,用户需要确保所有的输入栅格在空间范围、像元大小、投影等方面完全一致,否则数组的对应位置可能不准确。
关于代码中每一步输出的意义:
1. 读取数据:将各年的降水、温度、KNDVI数据转换为三维数组,确保时间维度正确对齐。
2. 处理每个像元:计算偏相关系数,控制温度的影响。对于每个像元,得到的结果是该位置在23年中,降水与KNDVI在控制温度后的相关性强度,值在-1到1之间。
3. 输出栅格:每个像元的值代表偏相关系数,正值表示降水增加与KNDVI增加相关(控制温度后),负值反之。
可能需要在代码中添加注释,解释每个步骤的作用,并处理可能的错误情况,比如数据不一致、内存不足等。
最后,考虑到用户使用的是较旧的Python和ArcGIS版本,需要确保代码的兼容性,例如使用Python 2.7的语法(如print语句、除法操作符等),并避免使用Python 3的特性。</think>以下是针对年均降水与KNDVI偏相关性分析(控制温度)的Python代码实现,结果将保存为栅格数据。代码兼容ArcGIS 10.6/Python 2.7环境:
```python
# -*- coding: utf-8 -*-
import arcpy
import numpy as np
import os
# 环境设置
arcpy.env.workspace = "D:/Gisdata/ABC.gdb"
out_gdb = "D:/Gisdata/GHI.gdb"
arcpy.env.overwriteOutput = True
arcpy.CheckOutExtension("Spatial")
# 创建输出地理数据库
if not arcpy.Exists(out_gdb):
arcpy.CreateFileGDB_management(os.path.dirname(out_gdb), os.path.basename(out_gdb))
# 按年份排序数据
precip_list = sorted(arcpy.ListRasters("p3_*"), key=lambda x: int(x.split('_')[1]))
temp_list = sorted(arcpy.ListRasters("t3_*"), key=lambda x: int(x.split('_')[1]))
kndvi_list = sorted(arcpy.ListRasters("k3_*"), key=lambda x: int(x.split('_')[1]))
# 验证数据一致性
assert len(precip_list) == 23 and len(temp_list) == 23 and len(kndvi_list) == 23, "数据年份不完整"
# 获取栅格属性模板
desc = arcpy.Describe(precip_list[0])
extent = desc.extent
sr = desc.spatialReference
cell_size = desc.meanCellWidth
# 定义分块处理参数
block_size = 256 # 分块大小根据内存调整
# 创建输出栅格
out_raster = arcpy.CreateRasterDataset_management(
out_gdb, "Partial_Corr_P_KNDVI",
cell_size=cell_size,
pixel_type="FLOAT",
spatial_reference=sr,
extent=extent
)[0]
# 分块处理函数
def process_block(precip_block, temp_block, kndvi_block):
"""计算偏相关系数"""
n_years = precip_block.shape[2]
# 初始化结果数组
result = np.full(precip_block.shape[:2], np.nan, dtype=np.float32)
# 向量化计算
for i in range(precip_block.shape[0]):
for j in range(precip_block.shape[1]):
p = precip_block[i,j,:]
t = temp_block[i,j,:]
k = kndvi_block[i,j,:]
# 过滤无效值
mask = ~np.isnan(p) & ~np.isnan(t) & ~np.isnan(k)
if np.sum(mask) < 3:
continue
# 提取有效数据
p_valid = p[mask]
t_valid = t[mask]
k_valid = k[mask]
# 计算偏相关系数
# 构建设计矩阵
X = np.vstack([t_valid, np.ones_like(t_valid)]).T
Xp = np.linalg.pinv(X)
# 计算残差
p_resid = p_valid - np.dot(X, np.dot(Xp, p_valid))
k_resid = k_valid - np.dot(X, np.dot(Xp, k_valid))
# 计算Pearson相关系数
cov = np.mean(p_resid * k_resid)
std_p = np.std(p_resid)
std_k = np.std(k_resid)
if std_p == 0 or std_k == 0:
r = np.nan
else:
r = cov / (std_p * std_k)
result[i,j] = r
return result
# 分块处理主循环
with arcpy.da.UpdateCursor(out_raster, ["*"]) as cursor:
for row in cursor:
# 获取当前块范围
top = row[0]
left = row[1]
right = row[2]
bottom = row[3]
# 读取数据块
precip_stack = [arcpy.Raster(p).getUnmanagedWeightedSlice([top, left, bottom, right])
for p in precip_list]
temp_stack = [arcpy.Raster(t).getUnmanagedWeightedSlice([top, left, bottom, right])
for t in temp_list]
kndvi_stack = [arcpy.Raster(k).getUnmanagedWeightedSlice([top, left, bottom, right])
for k in kndvi_list]
# 转换为numpy数组
precip_block = np.dstack([arcpy.RasterToNumPyArray(p) for p in precip_stack])
temp_block = np.dstack([arcpy.RasterToNumPyArray(t) for t in temp_stack])
kndvi_block = np.dstack([arcpy.RasterToNumPyArray(k) for k in kndvi_stack])
# 计算偏相关
result_block = process_block(precip_block, temp_block, kndvi_block)
# 写入结果
cursor.updateRow([result_block])
print(u"处理完成!结果已保存至:{}".format(os.path.join(out_gdb, "Partial_Corr_P_KNDVI")))
```
### 输出结果说明:
最终输出栅格 **Partial_Corr_P_KNDVI** 中:
- 每个像元值表示 **控制温度影响后** 的年均降水与KNDVI的偏相关系数
- 值域范围:-1 到 1
- **正值** 表示降水增加与KNDVI增加呈正相关
- **负值** 表示降水增加与KNDVI减少呈负相关
- **绝对值越大** 表示相关性越强
### 注意事项:
1. 内存优化:通过分块处理机制(block_size=256)降低内存消耗,可根据硬件配置调整该参数
2. 无效值处理:自动跳过包含不足3个有效数据点的像元
3. 空间一致性:所有输入栅格必须严格对齐空间参考和像元位置
4. 计算时间:250m分辨率全国范围数据预计需要2-4小时完成(取决于硬件性能)
建议在运行代码前:
1. 备份原始数据
2. 关闭其他占用内存的程序
3. 验证输入数据的完整性(23个年份数据均存在且命名正确)
如果需要进一步解释偏相关系数的统计学意义或结果分析方法,请随时告知。







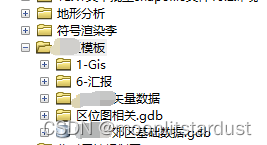
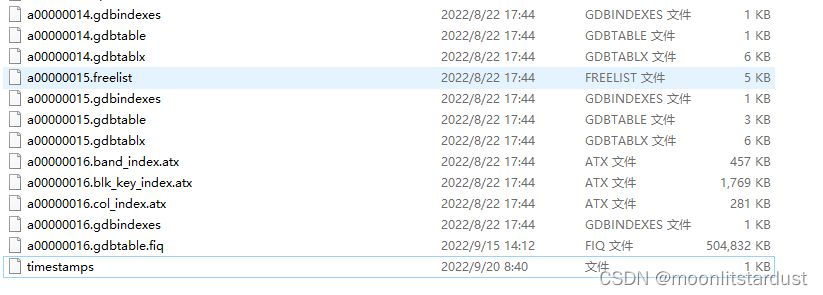
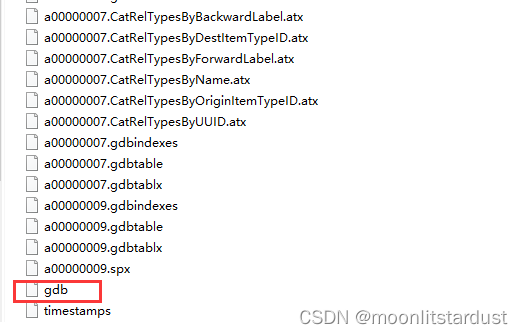
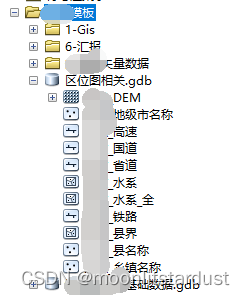
 本文介绍了一种解决GIS中无法加载特定数据库文件的问题的方法。通过对比正常与异常情况下的文件结构差异,找到缺失的.gdb文件,并将其补充到问题文件夹内,最终实现了数据库文件的正常加载。
本文介绍了一种解决GIS中无法加载特定数据库文件的问题的方法。通过对比正常与异常情况下的文件结构差异,找到缺失的.gdb文件,并将其补充到问题文件夹内,最终实现了数据库文件的正常加载。


 508
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























