







 关于web-harvest的使用,上篇转载的文章已经有简单的说明,本文主要以爬取yahoo!answers的数据为例,说明在使用过程中需要注意的问题。当然,最好的使用文档就是官方网站的user manual。 web-harvest有三个版本,这里用的是源码包。要完成数据的爬取,最重要的是配置config文件。源码包中有个Java类,Test.java,源代码如下:publ
关于web-harvest的使用,上篇转载的文章已经有简单的说明,本文主要以爬取yahoo!answers的数据为例,说明在使用过程中需要注意的问题。当然,最好的使用文档就是官方网站的user manual。 web-harvest有三个版本,这里用的是源码包。要完成数据的爬取,最重要的是配置config文件。源码包中有个Java类,Test.java,源代码如下:publ
关于web-harvest的使用,上篇转载的文章已经有简单的说明,本文主要以爬取yahoo!answers的数据为例,说明在使用过程中需要注意的问题。当然,最好的使用文档就是官方网站的user manual。
web-harvest有三个版本,这里用的是源码包。要完成数据的爬取,最重要的是配置config文件。源码包中有个Java类,Test.java,源代码如下:
public class Test {
public static void main(String[] args) throws IOException {
ScraperConfiguration config = new ScraperConfiguration("e:/temp/yahooanswer/auto racing.xml"); //line a
Scraper scraper = new Scraper(config, "e:/temp/wikianswer"); //line b
scraper.setDebug(true);
long startTime = System.currentTimeMillis();
scraper.execute();
System.out.println("time elapsed: " + (System.currentTimeMillis() - startTime));
}
}
line a中的.xml文件即抓取配置数据,line b 为抓取后数据的存放路径。其功能是完成yahoo!answers分类中sports/auto racing的resolved问题中的前5页内容,每页20条,以如下格式写入文件中:
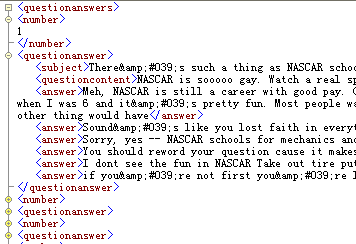
下面主要来分析一下auto racing.xml,xml文件如下:
<?xml version="1.0" encoding="utf-8"?>
<config charset="utf-8">
<include path="functions.xml"/>
<var-def name="home">http://answers.yahoo.com</var-def>
<var-def name="QALinks"> //定义变量QALinks,其值为函数download-m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2703
2703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









