







目录
示例:LengthFieldBasedFrameDecoder
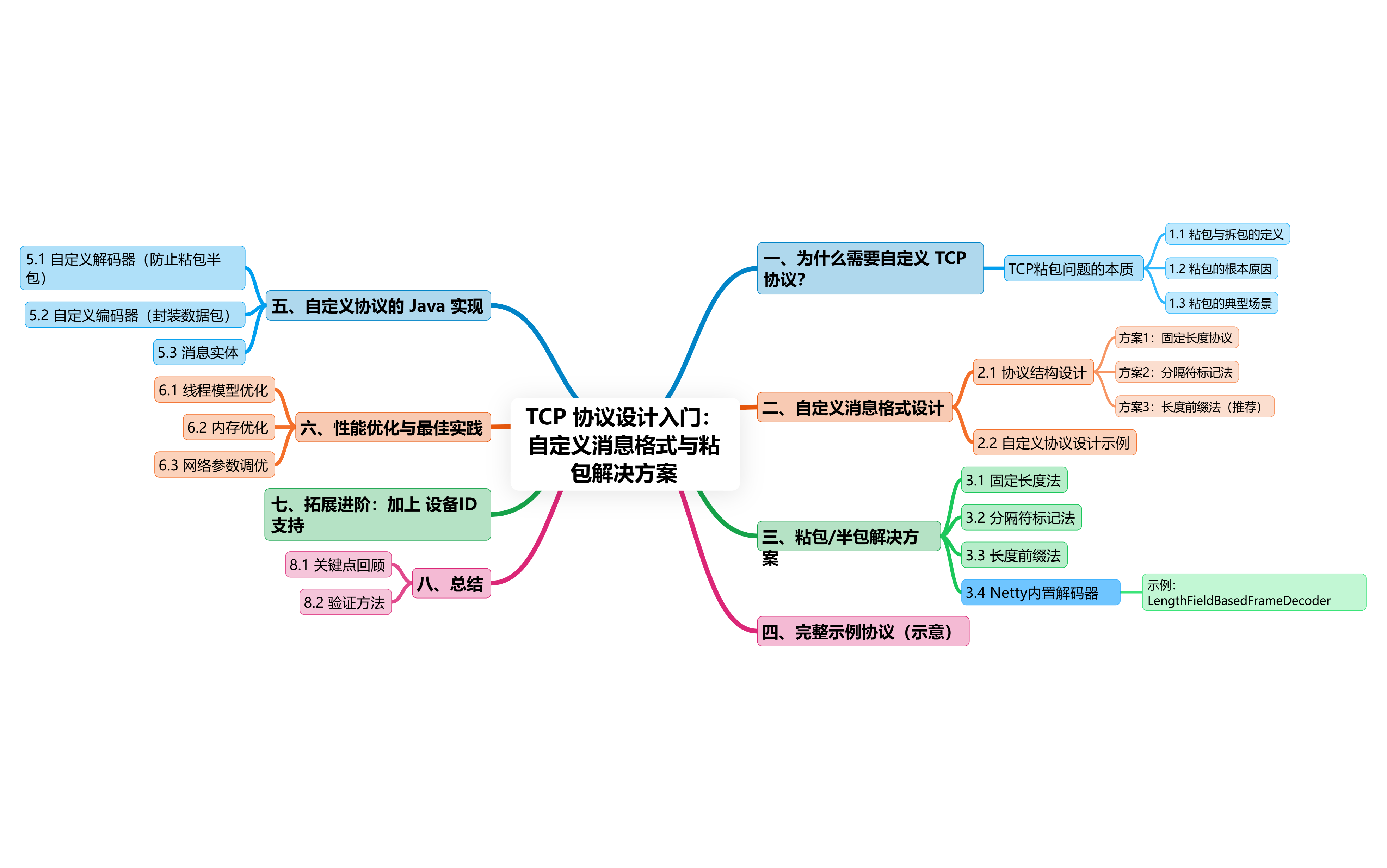
一、为什么需要自定义 TCP 协议?
TCP 是流式传输(无消息边界概念),可能出现:
| 问题 | 说明 |
| 粘包 | 多个消息粘在一起,一次性收到 |
| 拆包 | 一个消息被拆成多次收到 |
所以,必须设计一套【消息结构】,让接收端能准确拆分出完整的消息。
TCP粘包问题的本质
1.1 粘包与拆包的定义
-
粘包:多个独立的数据包被合并为一个数据块接收,导致接收端无法正确区分原始数据包的边界。
-
拆包:单个数据包被拆分为多次接收,接收端无法一次性读取完整数据。
1.2 粘包的根本原因
(1)TCP的字节流特性 TCP将数据视为连续的字节流,不保留消息边界。发送端多次写入的数据可能被合并发送(如Nagle算法优化),接收端可能一次性读取多个包或分多次读取一个包。
(2)缓冲区机制 发送端和接收端的内核缓冲区可能合并或拆分数据包。
(3)网络传输不确定性 数据包可能因MTU(最大传输单元,如1500字节)限制被分片,中间节点可能错误合并分片。
1.3 粘包的典型场景
-
高并发短连接:多个小数据包被合并发送。
-
大文件传输:数据包超过MSS(最大报文段长度,如1460字节)被拆分。
-
心跳机制失效:长时间无数据传输后,首次发送的小数据包可能与其他数据粘连。
二、自定义消息格式设计
2.1 协议结构设计
通过在应用层定义明确的消息边界,解决TCP的字节流问题。常见设计方案如下:
方案1:固定长度协议
-
结构:所有数据包长度固定,不足部分填充空字符。
-
示例:
[固定长度10字节] → "hello" → 填充为 "hello\0\0\0\0\0"-
适用场景:数据长度固定的场景(如工业控制指令)。
方案2:分隔符标记法
-
结构:在数据包末尾添加特殊分隔符(如
\r\n或自定义符号)。 -
示例:
"data1\r\ndata2\r\n"-
适用场景:文本协议解析(如HTTP头)。
方案3:长度前缀法(推荐)
-
结构:在数据包头部添加长度字段,明确后续数据长度。
-
示例:
[4字节长度字段] + [n字节数据体]-
优势:通用性强,支持变长数据,适合高性能场景。
2.2 自定义协议设计示例
统一格式:
+----------+--------+--------------+-----------+
| 消息头部 | 消息类型 | 消息体长度 | 消息体内容 |
| 4字节 | 1字节 | 4字节 | N字节 |
+----------+--------+--------------+-----------+字段解释:
| 字段 | 长度 | 说明 |
| Magic Number | 4字节 | 用于快速识别有效数据包,如 0xCAFEBABE |
| 消息类型 | 1字节 | 定义消息业务类型,如登录、心跳、数据上报等 |
| 消息体长度 | 4字节 | 消息体(payload)的字节长度 |
| 消息体内容 | N字节 | 业务数据(如JSON、二进制) |
三、粘包/半包解决方案
3.1 固定长度法
-
原理:发送端发送固定长度的数据包,接收端按固定长度读取。
-
代码示例:
发送端
data = b"hello"
packet = data.ljust(10) # 填充至10字节
socket.send(packet)
# 接收端
while True:
packet = socket.recv(10)
process(packet.strip()) # 去除填充字符3.2 分隔符标记法
-
原理:在数据包末尾添加特殊分隔符(如
\r\n)。 -
代码示例:
发送端
message = "data1\r\ndata2\r\n"
socket.send(message.encode())
# 接收端
buffer = b""
while True:
buffer += socket.recv(1024)
while b"\r\n" in buffer:
line, buffer = buffer.split(b"\r\n", 1)
process(line)3.3 长度前缀法
-
原理:在数据包头部添加长度字段,接收端先读取长度,再按长度读取数据体。
-
代码示例:
发送端
data = b"important_data"
length = len(data).to_bytes(4, "big") # 4字节长度字段
socket.send(length + data)
# 接收端
def recv_all(sock, size):
data = b""
while len(data) < size:
chunk = sock.recv(size - len(data))
if not chunk:
raise ConnectionError()
data += chunk
return data
length_data = recv_all(socket, 4)
length = int.from_bytes(length_data, "big")
data = recv_all(socket, length)3.4 Netty内置解码器
Netty提供现成的解码器简化粘包处理:
-
FixedLengthFrameDecoder:固定长度解码器。
-
DelimiterBasedFrameDecoder:分隔符解码器。
-
LengthFieldBasedFrameDecoder:长度前缀解码器(推荐)。
示例:LengthFieldBasedFrameDecoder
// 在ChannelPipeline中添加解码器
pipeline.addLast(new LengthFieldBasedFrameDecoder(
1024 * 1024, // 单个数据包最大长度
0, // 长度字段偏移量
4, // 长度字段长度
0, // 跳过字节数(长度字段之后)
4 // 初始偏移量(跳过长度字段)
));在 Netty 中:
-
自定义一个 解码器(ByteToMessageDecoder)。
-
规则:
-
先读取前面的固定字段(头、类型、长度)。
-
判断剩余字节够不够完整的消息体,不够就
resetReaderIndex,等待下一波数据。
-
这样,就完美防止了 粘包 和 半包!
四、完整示例协议(示意)
举个例子,设备登录发送:
| 字段 | 示例值 |
| Magic Number | 0xCAFEBABE |
| 消息类型 | 0x01(登录请求) |
| 消息体长度 | 16 |
| 消息体 | JSON串 {"deviceId":"abc123"} |
发送的二进制流就是:
CAFEBABE 01 00000010 7B226465766963654964223A226162633132337D五、自定义协议的 Java 实现
5.1 自定义解码器(防止粘包半包)
public class IotMessageDecoder extends ByteToMessageDecoder {
private static final int HEADER_SIZE = 9; // Magic(4) + Type(1) + Length(4)
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
if (in.readableBytes() < HEADER_SIZE) {
return; // 不够包头长度
}
in.markReaderIndex();
int magic = in.readInt();
if (magic != 0xCAFEBABE) {
ctx.close();
return; // 魔数校验失败,关闭连接
}
byte type = in.readByte();
int length = in.readInt();
if (in.readableBytes() < length) {
in.resetReaderIndex();
return; // 等待更多数据
}
byte[] payload = new byte[length];
in.readBytes(payload);
IotMessage message = new IotMessage();
message.setType(type);
message.setPayload(payload);
out.add(message);
}
}5.2 自定义编码器(封装数据包)
public class IotMessageEncoder extends MessageToByteEncoder<IotMessage> {
@Override
protected void encode(ChannelHandlerContext ctx, IotMessage msg, ByteBuf out) {
byte[] payload = msg.getPayload();
out.writeInt(0xCAFEBABE); // 魔数
out.writeByte(msg.getType());
out.writeInt(payload.length);
out.writeBytes(payload);
}
}5.3 消息实体
public class IotMessage {
private byte type;
private byte[] payload;
// getter、setter
}六、性能优化与最佳实践
6.1 线程模型优化
-
Epoll(Linux):使用
EpollEventLoopGroup替代NioEventLoopGroup,减少系统调用开销。
EventLoopGroup bossGroup = new EpollEventLoopGroup(1);
EventLoopGroup workerGroup = new EpollEventLoopGroup(
Runtime.getRuntime().availableProcessors() * 2);6.2 内存优化
-
池化内存:强制使用
PooledByteBufAllocator减少内存分配开销。
bootstrap.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);-
及时释放资源:确保所有
ByteBuf调用release(),避免内存泄漏。
try {
// 使用ByteBuf
} finally {
buf.release();
}6.3 网络参数调优
-
禁用Nagle算法:减少小数据包延迟。
channel.config().setTcpNoDelay(true);-
调整缓冲区大小:增大接收缓冲区。
channel.config().setReceiveBufferSize(1024 * 1024);七、拓展进阶:加上 设备ID 支持
如果你希望协议里直接带上【设备ID】(比如设备登录、发送消息时),可以这样设计:
+----------+--------+------------+--------------+------------+
| Magic | Type | DeviceID长度 | Payload长度 | DeviceID |
| 4字节 | 1字节 | 1字节 | 4字节 | N字节 |
+-------------------------------------------------------------+
| Payload (业务数据) |
+-------------------------------------------------------------+增加一个 DeviceIdLength 字段,让服务器可以识别哪个设备发来的消息!
八、总结
8.1 关键点回顾
(1)协议设计:优先采用长度前缀法,结合魔数、指令码明确消息边界。
(2)粘包解决方案:根据场景选择固定长度、分隔符或长度前缀法。
(3)性能优化:线程池配置、内存池化、网络参数调优。
8.2 验证方法
-
抓包工具:使用Wireshark分析数据包,确认粘包问题是否解决。
-
单元测试:模拟高并发场景,验证协议的鲁棒性。
-
日志监控:记录接收端的数据解析日志,检查是否出现异常。
配合 Netty,就能轻松支撑 百万设备高并发 IoT 通信服务器!
进阶版:
| 面向未来的 TCP 协议设计:可扩展与兼容并存 |
扩展阅读:
| 解锁 PHP 并发潜能:Swoole 框架详解与最佳实践 | 解锁 PHP 并发潜能:Swoole 框架详解与最佳实践 |
| 驾驭并发:Netty 高性能网络通信框架原理与实践 | 驾驭并发:Netty 高性能网络通信框架原理与实践 |
| 高并发网络编程框架对比:Netty 与 Swoole 的全面解析 | 高并发网络编程框架对比:Netty 与 Swoole 的全面解析 |
| 基于Netty的IoT设备通信架构:高并发、低延迟与长连接管理 | 基于Netty的IoT设备通信架构:高并发、低延迟与长连接管理 |
| Netty高并发聊天服务器实战:协议设计、性能优化与Spring Boot集成 | Netty高并发聊天服务器实战:协议设计、性能优化与Spring Boot集成 |
| Netty高并发物联网通信服务器实战:协议优化与性能调优指南 | Netty高并发物联网通信服务器实战:协议优化与性能调优指南 |
| TCP 协议设计入门:自定义消息格式与粘包解决方案 | TCP 协议设计入门:自定义消息格式与粘包解决方案 |




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











