







一、开发环境
1.Python 3.7windows版 下载链接:https://www.python.org/downloads/windows/
2.Pycharm 下载链接:https://www.jetbrains.com/pycharm/download/#section=windows
二、Python库包
1.urllib
urllib是Python标准库的一个URL处理包,包含了4个模块,每个模块都有特定的函数实现对网站的操作:
1.1 urllib.request:打开和读取URL;
1.2 urllib.error:使用try捕捉处理错误;
1.3 urllib.parse:解析URL;
1.4 urllib.robotparser:解析robots.txt文本文件。
以下是urllib库的简单使用(爬取豆瓣电影网页为例):
from urllib import request #导入request模块
response=request.urlopen("https://movie.douban.com/") #打开豆瓣电影网页
html=response.read() #读取网页html代码
html=html.decode("utf-8") #将代码转码成utf-8格式,生成剖析树
print(html) #输出网页代码
2.BeautifulSoup
BeautifulSoup是一个第三方库,用于解析html/xml文本,它可以很好的处理不规范标记并生成剖析树(parse tree)。配合urllib在获取到html文本后可通过其上的标签提取部分指定文本。
2.1 BeautifulSoup(html,“html.parser”):生成文档树,html为解析文本,html.parser为解析模型;
2.2 Beautifulsoup将html文本解析成4种对象类型:
2.2.1 Tag:标签,html文本中用<>包括起来的东西
2.2.2 NavigabString:标签的文本内容,标签下显示的文本
2.2.3 BeautifulSoup:文档内容,可以当成一个特殊的Tag
2.2.4 Comment:与NavigabString相似,但它会省略注释符号,从而得到注释内容
2.3 find_all(name,attrs,recursive,text,limit):在文档树中搜索标签名为name,标签属性为attrs,是否递归为recursive(默认为True),标签文本为text的标签,最多搜索limit条。
具体参考BeautifulSoup官方文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0
以下是BeautifulSoup库的简单使用:
from urllib import request #导入request模块
from bs4 import beautifulSoup #导入beautifulSoup库
response=request.urlopen("https://movie.douban.com/") #打开豆瓣电影网页
html=response.read() #读取网页html代码
soup=BeautifulSoup(html,"html.parser") #生成文档树,效果与utf-8格式编写的网页使用代码html=html.decode("utf-8")相似
#Tag 标签
print(soup.p) #获取html文本中第一个名字为p的标签
print(soup.p.name) #name:获取第一个p标签的名字,即p
print(soup.p.attrs) #attrs:获取第一个p标签的属性
print(soup('p')) #获取所有名字为p的标签
print(soup.p.contents) #contents:获取p标签下的所有子节点内容
print(type(soup.p.children)) #children:对p下的子节点循环生成一个生成器
#NavigabString 标签内容
print(soup.p.string) #第一个p标签的文本显示
print(soup.p.get_text()) #p标签的内容
三、导入库包
1.urllib是python标准库,所以直接在项目代码中添加“import urlib”字段即可完成导入。
2.BeautifulSoup是第三方库,导入方法如下:
1)在Pycharm主界面中,打开设置:File->Settings…
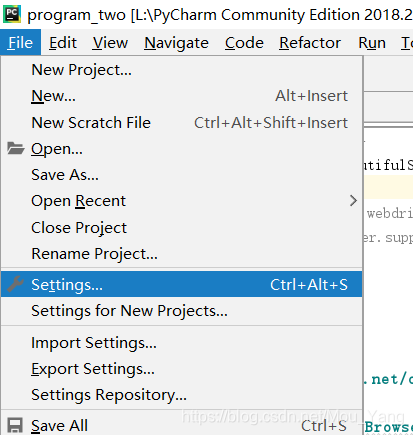
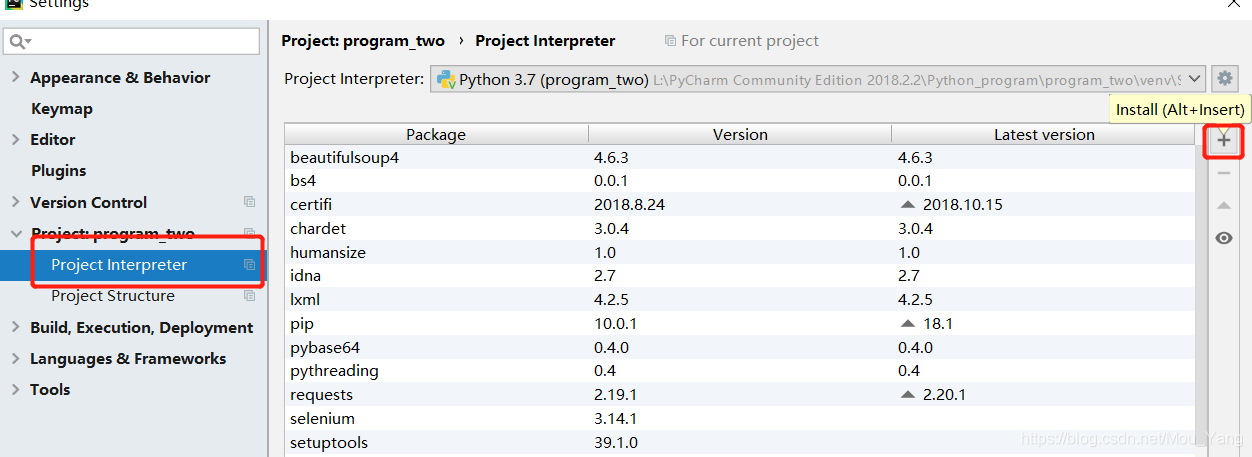
2)在设置中,找到项目解释器,并在展开框中点击“+”,为项目添加库包
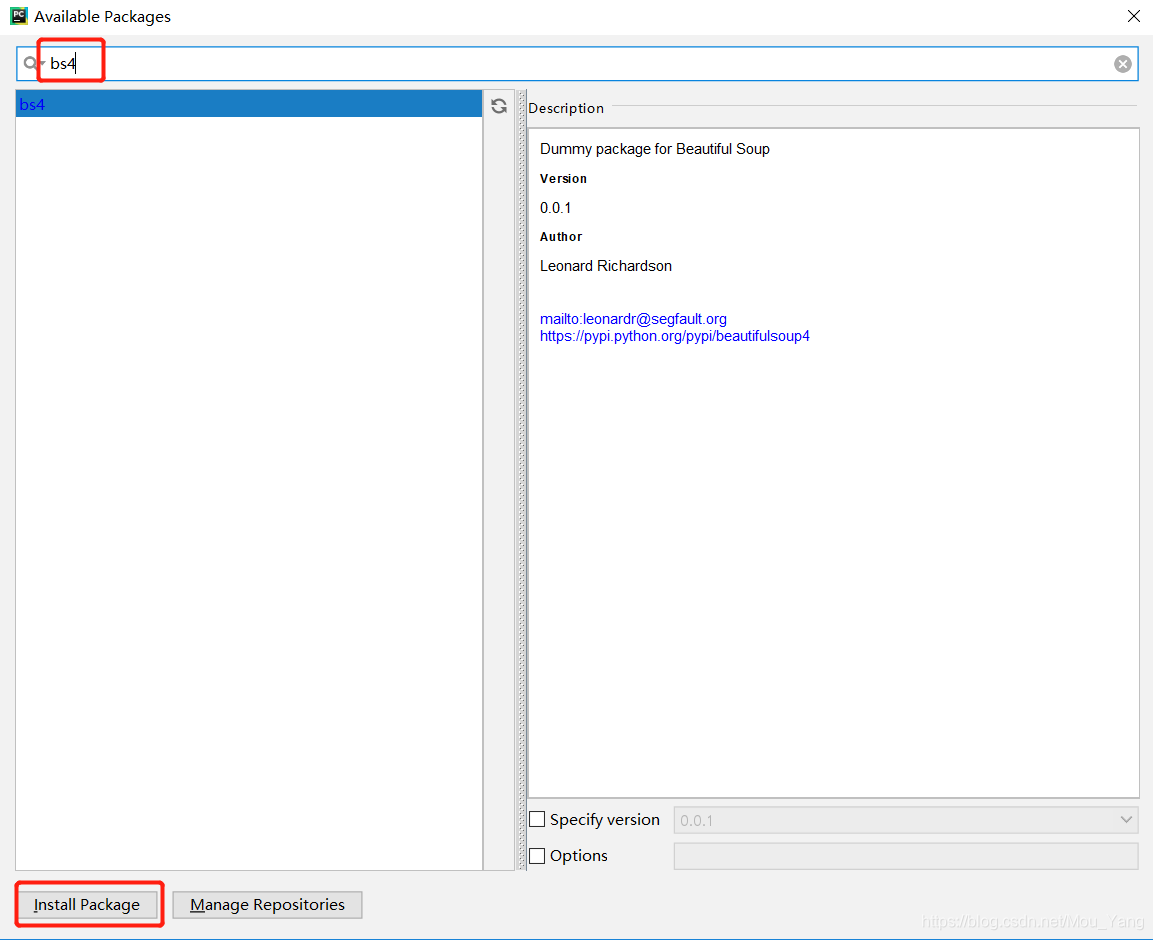
3)在搜索框中输入“bs4”,选中bs4库包并点击左下角“Install Package”将库包导入项目
4)在项目代码中添加“from bs4 import BeautifulSoup”字段即可完成库包导入
5)第一次从setting中导入库包后,之后再想使用BeautiulSoup库包就只需要执行4)步骤就行了。














 2179
2179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









