






数组的概念
---数组是一组相同类型元素的集合。(其实就是多个类型相同的变量值放在一起定义)
数组与变量一样都是c语言提供给用户操控内存的一种方式,都是在内存中开辟空间存放数据。区别是数组可以开辟自定数量的连续空间。空间的大小由元素数量决定。
数组的特点:
数组中所有元素具有相同的数据类型;
数组创建后,不能改变大小。
数组中的元素存储在内存中的存储单元是连续依次排列的
一维数组
定义数组
---类型+数组名字+元素数量 ;
类型 名称 [元素数量]; //相比变量的定义,数组加了[ ] ,中括号内存放的值是元素的个数。
int name [20]; //定义了一个数组,元素类型是整型,起了name的名称,数组大小是20个元素
double weight [10]; //元素数量必须为整数。元素个数不能为0。c99开始,可以用变量来定义元素数量,数组一旦创建就无法改变大小。
- 类型:数组中存放数据的类型(非数组类型),可以是:char、short、int、float等也可以是自定义的类型。
- 数组名称:指的是数组的名字,根据实际情况,起一个方便阅读理解的名字。
- 元素数量:指定数组的大小,根据实际需求指定大小即可。 元素的数量就是数组的大小。
数组的类型
数组本身也是有类型的,数组是一种自定义类型。去掉数组名留下的就是数组的类型。
int name [20]; //数组name的类型是 int [20]
double weight [10]; //数组weight的类型是 double [10]
数组的初始化
---在数组创建时,给定一些初始值,被称为初始化。
数组初始化赋值使用大括号,将数据放在大括号中,每个元素用逗号隔开。
int arr[5] = {1,2,3,4,5}; //完全初始化,数组大小为5个元素,给予5个值。
int arr[5] = {1}; //不完全初始化,数组大小5,给予1个值,剩余的元素默认值为0。
所赋值的个数不能超过数组的大小。
变长数组
c99之前创建数组
int a1[10];
int a2[3+5];
int a3[]={1,2,3,4,5};
c99标准开始,c语言中引入变长数组的概念,可以使用变量来自定义数组空间大小。但数组被创建后就不能更改大小了。
int n = 0;
scanf(“%d”,&n);
int a[n]; //数组的大小由n的值来决定,一旦确定了n的值,就确定了变量空间的大小。
数组a的大小取决与变量n的值,编译器没法事先确定,只有运行时知道n是多少后才能确定数组a的大小。当确定了n的值并在内存中创建了数组a的空间后。数组的大小就被确定,不能更改。
变长数组不能被初始化。
一维数组的使用
下标
下标也被称为索引。
c语言规定,数组的每个元素按顺序进行编号。从0开始一直到最后一个元素。这个编号被称为下标。这样第一个元素的下标就是0,最后一个元素的下标是元素的个数减1。
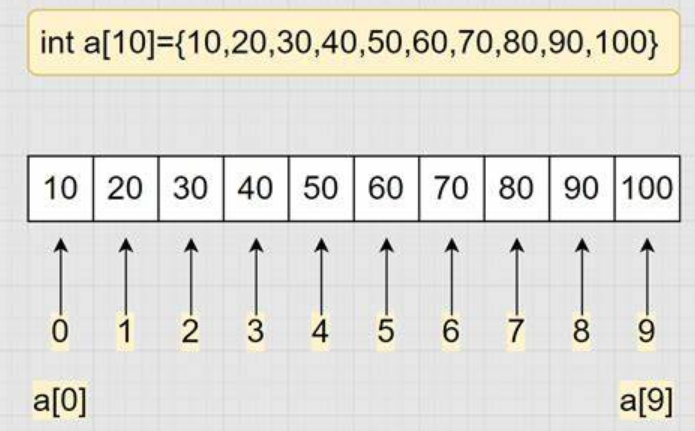
下标引用操作符
c语言在数组的访问提供了一个操作符[ ],叫做:下标引用操作符
通过下标引用操作符,我们可以轻松的访问到数组的元素的值。如访问第一个元素就可以使用a[0],访问第2个元素就可以使用a[1]。
a[0]; //a数组下标为0的元素。
a[5]; //a数组下标为5的元素
下标是从0开始计数,最大下标是元素个数-1。
通过下标访问数组
通过数组下标访问数组时,获取的是对应位置元素的值
int a[10] = {1,2,3,4,5,6,7,8,9,10}; //数组初始化。
printf(“%d”,a[0]); //通过第零个下标打印第一个元素
越界访问问题
int name[20]; //定义了一个数组,有20个元素。
name[20]; //使用下标号为20的元素。超出了数组定义的元素个数。超出19就会超出name数组在内存中开辟的空间,进行越界访问。
注意:
- 编译器和运行环境都不会检查数组下标是否越界,无论是对数组单元做读或写。
- 程序运行后,越界的访问的数组可能造成问题,可能会导致程序崩溃。 segmentation fault 所以写程序时一定要保证程序使用有效的下标值:[0,数组的大小-1]
- 数组的下标必须是整型,c语言中字符是整数类型也可以作为下标使用
数组的遍历
通过for循环产生数组的下标来访问所有的元素
int a[10] = {1,2,3,4,5,6,7,8,9,10}; //数组初始化。
int i = 0; //定义i变量存放下标。
for (i=0;i<10;i++) //同过for循环将所有下标遍历一遍。
printf("%d ",a[i]); //输出数组的所有元素。
数组的输入
通过scanf函数,输入值给数组的某一个元素。
int a[10] = {1,2,3,4,5,6,7,8,9,10};
scanf("%d",&a[0]); // 通过scanf函数给数组的第一个元素输入值。
printf(“%d”,a[0]);
输入值给数组的所有元素。
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0; //定义i变量存放下标。
for (i=0;i<10;i++) //同过for循环将所有下标遍历一遍。
scanf("%d ",&a[i]); //通过循环输值给数组的所有元素。
for (i=0;i<10;i++) //同过for循环将所有下标遍历一遍。
printf("%d ",a[i]); //输出数组的所有元素。
数组元素在内存中是连续存放的
通过访问数组元素在内存中的地址来探究数组在内存中的存放方式。
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0; //定义i变量存放下标。
for (i=0;i<10;i++) //同过for循环将所有下标遍历一遍。
printf("%p\n ",&a[i]); // 地址的格式占位符是%p
通过输出分析,地址的大小随着下标的增长而变大,且相邻的元素之间相差4(因为一个整型是4个字节)。
所以得出结论:数组在内存中是连续存放的。
sizeof计算数组元素的个数
sizeof是c语言的关键字,可以计算类型或者变量空间的大小。sizeof也可以计算数组空间的大小。单位是字节。
计算数组所占空间大小
int a[10] = {1,2,3,4,5,6,7,8,9,10};
printf("%d\n",sizeof(a)); //结果是40,计算数组所占内存空间的大小,单位是字节。
计算数组单个元素所占空间大小
int a[10] = {1,2,3,4,5,6,7,8,9,10};
printf("%d\n",sizeof(a[0])); //结果是4,计算数组下标为零的元素所占内存空间的大小,单位是字节。
数组空间大小除以单个元素的空间大小,得到数组的元素个数。
int a[10] = {1,2,3,4,5,6,7,8,9,10};
int c = sizeof(a)/sizeof(a[0]); //定义c变量来存储数组的个数
printf("%d\n",c); //结果为10,表示有10个元素。
strlen计算字符串的长度。
如果数组元素是字符,求字符的个数可以用strlen()。需要头文件string.h。
strlen()计算字符串长度的时候,遇到\0就自动停止了,不会将\0计算在内
char a[]="hello world!";
printf("%c",strlen(a)); //输出结果为12。
printf("%c",a[strlen(a)-1]); //通过最后一个元素的下标获取元素的值,结果为‘!’
printf("%s",a); //%s字符串格式占位符,直接打印hello world!
多维数组
二维数组就是将多个一维数组作为数组的元素。三维数组就是将多个二维数组作为数组的元素。二维数组以上的数组统称为多维数组
二维数组的创建
类型+名称+[常量值1][常量值2];
int a[3] [5];
通常理解为a是一个3行5列的矩阵。
二维数组初始化
二维数组也使用大括号进行初始化
int a [3][5]={1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7}; //完全初始化
int a [3][5] = {1,2}; //不完全初始化,前两个数是1和2,剩余的值默认用0补全
int a [3][5] = {{1,2},{3,4},{5,6,}} //按照行初始化。每行的前两个值有输入,其他默认0
int a [ ] [5] = {1,2,3}; //初始化时可以省略行,但不能省略列。1行5列
int a [ ] [5] = {1,2,3,4,5,6,7}; //2行5列,第一行值为1,2,3,4,5第二行为6,7,0,0,0
int a [ ] [5] = { {1,2},{3,4},{5,6} }; //3行5列,每行前两个值有输入,其他值默认为0
二维数组的使用
二维数组的下标
二维数组是有行和列的,只要锁定了行和列就能锁定数组中的一个元素。
c语言规定,二维数组的访问也是使用下标的形式。行是从0开始,列也是从0开始。
int a [3][5]={1,2,3,4,5,
2,3,4,5,6,
3,4,5,6,7};
printf("%d",a[0][0]); //打印行下标0,列下标0的元素(第一行第一个)。结果为1
printf("%d",a[2][4]); //打印行下标2,列下标4的元素(第三行第五个)。结果为7
数组的遍历,访问整个数组
for(int i=0;i<3;i++) //循环行
{
for(int j=0;j<5;j++) //循环列
{
printf(“%d ”,a[i][j]); //输出每一个元素
}
}
数组输入并输出
for(int i=0;i<3;i++) //循环行
{
for(int j=0;j<5;j++) //循环列
{
scanf("%d",&a[i][j]); //输入值
}
}
for(int i=0;i<3;i++) //循环行
{
for(int j=0;j<5;j++) //循环列
{
printf("%d ",a[i][j]); //输出值
}
}
注意:a[i,j]不是一个正确的表达二维数组的方式,逗号运算符的值是最右边的表达式,所以a[i,j]就是a[j]
二维数组方便阅读的书写格式
int a[][5]={
{0,1,2,3,4}, //可以直接写0,1,2,3,4,2,3,4,5,6然后由编译器按顺序存放。
{2,3,4,5,6}, //带上大括号分行书写方便阅读。 最后带逗号不带逗号都行,
};
行数可以由编译器来数,列数是必须给出的。
每行一个{},逗号分隔
最后的逗号可以存在,有古老的传统
二维数组的元素在内存中也是连续存放的。
通过打印数组所有元素的地址来探究二维数组在内存中的存储方式。
int a[3][5] = {0};
for(int i=0;i<3;i++)
for(int j =0;j<5;j++)
printf("%p\n",&a[i][j]); //打印地址的格式化占位符%p。
从输出的结果来看,每一行的每个元素都是相邻的,地址相差4个字节,跨行位置的两个元素之间也是差4个字节,所以二维数组中的每个元素都是连续存放的。
函数
函数(function)也被称为子程序。c语言中的函数就是完成某项特定的任务的一小段代码。
函数有特殊的写法与调用方法。
库函数
库函数是c语言标准库中提供的现成的函数,要使用库函数,必须包含对应的头文件。
库函数相关头文件:https://zh.cppreference.com/w/c/header
自定义函数
函数是一段代码,接收零个或多个参数,做运算,并返回一个或者零个值。
函数的定义:
---自定义函数由函数头、函数体组成。
函数头:返回类型,函数名,(参数表)
函数体:大括号+内部功能代码
例如自定义一个函数:函数作用是计算两个整数的和
int add(int x,int y) //函数返回类型int,函数名add,()内两个变量可以接收两个参数。
{
return x+y; //返回x与y的和(表达式的结果被返回),返回值的类型定义在函数头内。
} //函数的返回值会放在寄存器内然后再被调用的。
函数的使用
调用函数:函数名(参数值)
调用自定义的加法函数;
int add (int x,int y) //自定义一个加法函数
{
return x+y;
}
int main()
{
int a,b,c;
scanf(“%d %d %d”,&a,&b,&c); //调用:scanf()库函数
printf(“a与b的和是%d\n”,add(a,b)); //调用:add(a,b)函数。a与b的值会按顺序传给自定义函数参数表内的变量x与y。然后经过自定义函数的内部功能,输出两个数的和。最终通过printf()库函数打印出来
printf(“a与c的和是%d\n”,add(a,c)); //再次调用自定义函数;自定义函数优点,将功能封装方便重复调用。
printf(“b与c的和是%d\n”,add(b,c)); //再次调用加法函数
return 0;
}
每个函数都有自己的变量空间,参数也位于这个独立的空间中,和其他函数没有关系。定义的变量等也是在自己的函数内部中,与其他函数没有关系。
函数中逗号和逗号运算符的区分。
调用函数时的逗号是标点符号,不是运算符。如add(a,b);。而add((a,b),(a,c));内的a,b a,c间的逗号才是运算符
函数的参数传递
调用函数时必须传递给它数量、类型正确的值。
可以传递给函数的值是表达式的结果,可以是
常量 add(10,20);
变量 add(a,b);
计算的结果 add(a+5,b);
函数的返回值 add(add10,20),a);
调用函数时,是将数值传给函数,并非变量等表达式。
自动类型转换
如果调用函数的时候,给的值和参数的类型不匹配,编译器会自动进行类型转换,以适配函数参数表的参数类型。但编译器将类型转换后的结果可能并不是你所期望的。
add(2.5,3.6); //自定义加法函数接收的是整型,传参时传了浮点数就会发生类型转换。
return 语句
return后可以是一个数值,也可以是一个表达式,如果是表达式则先执行表达式,再返回表达式的结果。
return后也可以什么都没有,直接写return;适合函数返回类型为void的情况
return返回值和函数返回类型不一致时,系统会自动将返回的值转换为函数的返回类型。
return语句执行后,函数就彻底返回,后面的代码将不再执行。
非void类型函数必须要有返回值,如果函数中存在if等分支的语句,要保证每种分支都能有返回值供给函数返回使用,否则会出编译错误。例如只写了if(a>0)return1;没有写a<=0的情况就会报错
返回值可以赋值给变量,可以再传递给函数,甚至可以丢弃(调用函数但未使用返回值,例如返回值外还打印了一串字符,我们需要这串字符不需要返回值时,就可以不使用返回值)。
没有返回值的函数
void 函数名 (参数表)
void end(void) //返回类型为void说明函数没有返回值,参数表内void,表示不需要参数。
{
printf("游戏结束"); //调用printf()函数时,会在屏幕打印“游戏结束”。
} //end()函数没有任何返回值。
不能使用带值的return,可以没有return。调用的时候不能做返回值的赋值。
调用时直接写end();即可
函数不需要传递任何参数,那么在参数表内写void 如:void end(void);如果不写void,编译器会认为不确定是否有参数,而且如果有参数传到函数参数表内会默认为int类型参数。
注意:
()起到了表示函数调用的重要作用,即使没有参数也需要()
如果有参数,需要给出正确的数量和顺序
自定义函数没有写返回类型时,默认为整型。
如果函数有返回类型,但函数体内没写return时,那就不能确定具体返回什么。
函数在设计的时候,一定要尽量功能单一,方便调用。
数组做函数参数
传参方式:
数组传参时()内写数组名即可,会把数组在内存中的地址传过去。这与数值、变量传参有本质的不同。(数组传参在内存中地址用的是同一个,也就是说并没有创建新的空间存放数据。数值、变量传参时在内存中开辟了新的空间,不同空间不同地址。)
接收参数;
接收数组的参数时接收的是数组的地址。(地址对应的就是数组的参数)
参数表内要创建对应的类型属性空间。
例如:自定义函数将整型数组内容全部设置为任意整数,再自定函数打印数组内容。
void set(int x[ ],int y,int z) //创建设置数组内容函数 参数表(接收数组,接收元素个数,接收任意值)
{
int sz = sizeof( x ) / sizeof(x [0] ) ; //不可以在函数内求数组的大小。数组作为参数传递给自定函数时,它会退化为指针(数组地址)。所以sizeof(x)求的是指针本身的大小(在64位系统是8字节,在32位是4字节)。当sizeof(x)/sizeo(x[0])计算时,实际是指针大小除以数组元素的大小。结果肯定不是元素的数量。所以需要传元素数量进来。
for(int i = 0;i<y;i++) //遍历数组
int x[i] = z; // 将数组的每个元素设置为传过来的任意数.
} //自定义函数内的数组与主函数中的数组是同一个(函数内的数组是通过指针将数组内容重新指向主函数中的数组)。所以在函数中改变了元素的值后,主函数中的数组元素的值也会被改变。这与普通变量的传值有很大的不同。
void print(int x[ ],int y) //创建打印数组的函数 参数表(接收数组,接收元素个数)
{
for(int i = 0; i<y;i++)
printf("%d ",x[i]);
printf("\n"); //如果连续调用函数时,每次打印完可以换行。
}
int main()
{
int a[ ] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18};
int sz = sizeof( a ) / sizeof( a[0] ) ; //定义变量sz用来存放元素个数
int n = 0; //创建变量n用来存放任意整数。
scanf("%d",&n);
set(a,sz,n); //调用set()函数,数组传参时只需要数组名即可。
print(a,sz); //调用自定义的print()函数并按顺序传递参数。
return 0;
}
函数参数表中参数如果是一维数组,数组大小可以省略不写,如果是二维数组 ,行可以省略,但是列不能省略。
自定义函数参数表中接收的数组,不是重新创建的数组,而是与主函数中的数组是同一个。
嵌套调用和链式访问
嵌套调用
嵌套调用就是函数之间的互相调用。
例如:输入年份,月份,输出天数,用函数实现。
bool leapyear(int y) //自定义函数,判断是否是闰年 布尔类型需要头文件stdbool.h
{
if(y%400==0 || y%100!=0 && y%4==0)
return true;
else
return false;
}
int getday(int y, int m) //自定义函数,通过年份,月份,获得天数
{
int day[ ]={0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 30};//多输入一个元素使下标就是月份
if(m==2 && leapyear(y)) //getday()函数内调用leapyear()函数就是嵌套调用。利用逻辑与短路特性,如果m==2不成立也就无需调用leapyear()函数。
day[m]=29; //如果是闰年,那么2月份是29天。
return day[m]; //返回月份对应的天数
}
int main() //主函数,要求输入年与月,输入天数
{
int year month;
scanf("%d %d",&year, &month); //输入年份与月份
printf("%d", getday(year,month)); //通过getday()函数获得天数,并打印
return 0;
}
链式访问
将一个函数的返回值作为另外一个函数的参数,像链条一样将函数串起来就是函数的链式访问。
例如上面printf("%d", getday(year,month));将getday()函数的返回值作为printf()函数的参数
函数的声明
c的编译器子上而下顺序分析代码。所以函数要定义在主函数的上面。这样程序在运行时编译器就会知道所调用的函数是什么样的,要几个参数,参数是什么类型,返回什么类型等。
如果函数定义在函数调用的下面,那么调用函数前需要先进行声明。
如何声明:
返回类型 名称 (参数类型);
最简单的方法是将函数头复制到main函数前面并以分号;结尾。 这叫做函数的原型声明。
当程序运行时编译器会根据原型声明来确认函数的定义。如果声明与函数定义一致(返回类型,名称,参数个数及类型。),主函数正常运行,如果不一致会提示出错。
bool leapyear(int);//声明:返回类型 函数名 参数表内参数类型,参数的名可省略
int getday(int y, int m);//函数的声明:参数名虽然可以省略,但一般不省,方便阅读。
int main() //主函数,要求输入年与月,输入天数
{
int year month;
scanf("%d %d",&year, &month);
printf("%d", getday(year,month));
return 0;
}
bool leapyear(int y) //自定义函数,判断是否是闰年 头文件stdbool.h
{
if(y%400==0 || y%100!=0 && y%4==0)
return true;
else
return false;
}
int getday(int y, int m) //自定义函数,通过年份,月份,获得天数
{
int day[ ]={0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 30};
if(m==2 && leapyear(y))
day[m]=29;
return day[m];
}
函数和变量都要满足:先声明后使用。
如果函数定义在主函数下面,并且未进行声明。那么主函数中调用自定义函数时,默认调用的函数为int类型。
C语言不允许定义函数内嵌套另一个函数的定义,只能调用或者声明。
int a ,b,sum(int x,int b);//定义了整型变量a与b。声明了函数原型sum,sum需要两个int类型的参数,并且返回一个int类型的值。
递归
在c语言中,函数自己调用自己就是递归。
递归的限制条件
递归存在限制条件,每次递归调用之后越来越接近这个限制条件,当满足这个限制条件的时候,递归便不再继续。
如果没有限制条件,代码会陷入死递归,导致栈溢出(Stack overflow)
递归的执行逻辑
递归中的递就是递推的意思,归就是回归的意思
把一个大型复杂的问题,一层层的转化为一个与源问题相似,但规模较小的子问题来求解。
例如:输入一个整数,按照顺序打印整数的每一位。 输入 1234,输出1 2 3 4
void pt(int n)
{
if(n>9) //判断,如果是个位数就结束递归。
pt(n/10); //函数自己调用自己。知道达到限制条件为止。
printf("%d ",n%10);
}
int main()
{
int num = 0;
scanf("%d",num);
pt(num);
return;
}
如果传输n值为1234,那么递归的执行逻辑是:
pt(1234) 进入if判断大于9,执行pt(1234/10),待执行printf(“4”)函数;
pt(123)进入判断大于9,执行pt(123/10)待执行printf(“3”)函数;
pt(12)进入判断是否大于9,执行pt(12/10)待执行printf(“2”)函数;
pt(1)小于9,递推结束,开始回归。开始执行后面的代码;
pt(1)函数开始执行printf(“1”)代码,1%10打印1
pt(12)函数开始执行printf(“2”)代码,12%10打印2
pt(123)函数开始执行printf(“3”)代码,123%10打印3
pt(1234)函数开始执行printf(“4”)代码,1234%10打印4
最终输出1 2 3 4.
本地变量
函数的每次运行,就产生了一个独立的变量空间,在这个函数空间中的变量,是函数运行所独有的,称作本地变量。
定义在函数内部的变量就是本地变量,也被称为局部变量,自动变量等。
参数表的参数也是本地变量。
变量的生存期和作用域
生存期:变量的定义到变量的消亡(出作用域就消亡)
作用域:在(代码的)什么范围内可以访问这个变量,(这个变量可以起作用的范围)
对于本地变量,它的生存期和作用域是大括号内。
对于全局变量,它的生存期和作用域是整个工程项目。
本地变量的规则
1.本地变量是定义在块内(大括号内)的
它可以是定义在函数的块内
也可以是定义在语句的块内,如分支与循环语句块内所定义的变量。
甚至可以随便拿一对大括号来定义变量。
2.程序运行进入这个块之前,其中的变量不存在,进入时才会被创建,离开这个块,其中的变量就消失。
3.块外面定义的变量在里面仍然有效。
4.块内外面定义了同名变量,块内将使用块内新定义的变量。
5.不能在同一个块里定义同名变量。
6.本地变量默认不会被初始化。
7.参数在进入函数的时候就会被初始化。
static修饰符
static是c语言中的关键字,是静态的意思可以用来修饰局部变量、全局变量、函数。
函数内当变量被static修饰后,变量就不会随着函数调用的结束而销毁。
void test() //自定义一个测试函数。
{
static int i =0; //使用static修饰局部变量i
i++;
printf("%d\n",i); //i的值随着每次调用有累加效果。
}
int main()
{
test(); //调用函数
test(); //调用函数
test(); //调用函数
return 0;
}
static修饰局部变量改变了变量的生命周期,而生命周期的改变本质上是改变了变量的存储类型。
局部变量在内存中是存储在栈区的。被static修饰后存储到了静态区。存储在静态区的变量和全局变量是一样的,只有程序结束,变量才会销毁。但是作用域不变。
什么是表达式
对c语言来说表达式是一个非常宽的术语,很多东西都可以看作是表达式,单一的字面量,单一的变量,计算的结果,赋值,函数调用本身也是表达式。
表达式是由运算符、操作数以及标点符号组合而成的式子,经计算后会得到一个值。
常量本身就是固定的值,无需额外运算,所以是一种最简单的表达式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









