






关注公众号,发现CV技术之美
多模态大模型(LVLMs)取得了快速的进展,在处理视觉信息方面展现出了很强的感知和推理能力。然而,当面对不同规模解空间的问题时,LVLMs 在相同知识点上并不总能给出一致的答案,这种答案的不一致性在 LVLMs 中普遍存在,在一定程度上会损害实际的用户体验,然而现有的多模态大模型基准测试却忽视了关于一致性的评价。
针对这一问题,北京大学计算机学院联合字节跳动提出了ConBench(Unveiling the Tapestry of Consistency in Large Vision-Language Models),弥补了这一缺陷。ConBench评测流程简洁快速,目前合并至LLaVA官方推理库lmms-eval中,欢迎大家试用。

论文链接:https://arxiv.org/abs/2405.14156
数据集与评测代码:https://github.com/foundation-multimodal-models/ConBench
第三方库:https://github.com/EvolvingLMMs-Lab/lmms-eval
ConBench 具有几个重要的亮点:
设计1K条Case,每条Case包含判断题、选择题与限制性问答题,这三类判别式问题围绕同一知识点展开
基于 ConBench,首次揭示了以下发现:
在判别式领域,问题的解空间越大,模型的准确性越低
建立了判别式和生成式之间的关系:区分性问题类型的准确性与其与标题的一致性之间呈现强烈的正相关性
与开源模型相比,闭源模型在一致性方面具有明显的Bias优势
通过基于触发器的诊断优化来改善 LVLMs 的一致性,间接提高其Caption的性能
接下来,我们一起来看看该研究的细节。
研究动机
最近,得益于大语言模型(LLMs)的显著进展,多模态大模型(LVLMs)领域经历了一次革命性的转变。这些新颖的LVLMs试图将视觉信号与文本语义结合起来,通过跨模态激发通用人工智能的认知。
虽然LVLMs可以生成高质量的回答,但是作者发现,对于回答正确的情况,简单修改prompt会导致LVLMs给出矛盾的回答。在图1(a.2)中,LLaVA-7B正确描述了图片为“一个穿着恐龙服装的男人”,但当prompt为“恐龙是由人扮演的吗?请回答是或否。”时,LLaVA-7B回答“不,它们是恐龙”。这种不一致的现象在主流LVLMs中普遍存在,但目前仅在LLMs进行初步研究。
实际上,与现有多模态基准测试中设计的固定问题模式相比,用户倾向于以任意方式提出问题。因此,有必要确保LVLMs在面对各种查询格式时能够预测出正确且“一致”的答案。

然而,目前还没有专门关注评估LVLMs回答一致性的基准测试或研究。这些基于单个提示类型的评估方法(MMBench, SeedBench, MME, MMMU)导致基准测试的准确性与真实世界用户实际体验之间存在脱节。
评测方法
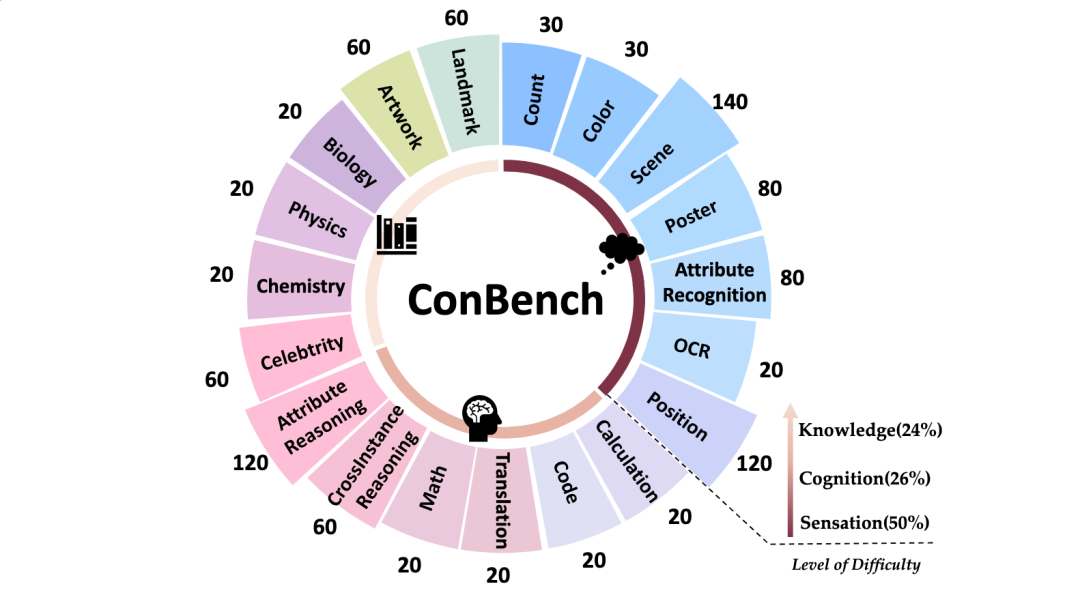
研究团队提出了一种名为ConBench的新型多模态评估流程,全面评估LVLMs的能力。ConBench共包含了1K张图片,每张图片包含3个判别式问题与1个生成式问题,保证了评估的质量和问题的多样性。
数据生成过程
我们从四个高质量的多模态基准数据集中手动选择了1K张图片:MME、SeedBench、MMBench和MMMU。其中,MME是判断题类型,而SeedBench和MMBench则是选择题,MMMU则强调知识能力。
每张图片原有1个判别式问题,我们额外构建其余两个判别式问题。因此,每个Case都有三个判别式prompt(判断题、选择题与限制性问答题),以及围绕相同知识点的生成式prompt。我们修改了那些答案可以直接从文本中推断出来而不需要图片的原始prompt,迫使LVLMs利用视觉特征的信息。最后,为了避免影响评估结果,判断题的正确和错误答案的分布比例均为50%。对于多项选择题,每个选项(如A、B、C、D)成为正确答案的概率分布均为25%。值得注意的是,为了确保评估解析器准确,问答题受到更多的限制,例如指定字数和答案格式(如分数/缩写/数字)。
层次化的核心能力
ConBench包含三个核心能力,按难度递增顺序分别是:观察能力(Sensation)、复杂推理(Reasoning)和专业知识(Knowledge)。这些能力层次的设计理念是为了逐步挑战模型在不同任务上的表现,并提供细粒度的评估指标。
多维度评估指标
ConBench分别从判别性和生成式的角度,提供两个评估指标,旨在更全面地了解LVLMs的一致性。
ConScore[D]定义如下:当同一Case的三种判别式问题都被正确回答时,模型得到一分,最高分为1000分,以百分比(%)的形式呈现。判断题、选择题与限制性问答题。
对于判断题,从答案中提取“是”和“否”。如果两者都不存在,则答案将被视为“无”。
解析选择题时,从中提取选项标签(A、B、C、D)。将其作为预测值并与真实答案进行匹配。如果失败将不继续提取答案,因为prompt已指定只需回答一个字母,进一步提取对擅长遵循指令的LVLM来说是不公平的。
对于限制性问答题,基于字符匹配ANLS进行赋分。
ConScore[C]定义如下:Caption和其他三个判别式回答之间一致性的平均分数。
由于Caption存在高度的可变性,仅通过字符匹配来计算一致性是不可行的。因此,依赖于GPT/GPT4来进行判断。判断过程和构建的提示如图3所示。作者将其定义为一个机器阅读理解任务。他们手动采样了判断结果,GPT4的准确率达到了95%,可靠可信。

评测结果
ConScore[D]

ConScore[C]

分析与可视化
基于 ConBench,首次揭示了以下发现:
在判别式领域,问题的解空间越大,模型的准确性越低
建立了判别式和生成式之间的关系:区分性问题类型的准确性与其与标题的一致性之间呈现强烈的正相关性
与开源模型相比,闭源模型在一致性方面具有明显的Bias优势

简单改进
首先让LVLM生成Caption,每个单词都伴随着其相应的logit。接下来,基于词性删除无信息的词语,只保留名词、形容词和量词。当剩下的词语的概率低于阈值(这里设定为0.85)时,低概率表示模型对此单词缺乏信心,作者制定判别式问题来使LVLM进行自我验证(例如,照片中有{猫}吗?)。自我诊断的prompt及其回答构造成新的prompt,反馈给LVLM以生成更高质量的Caption。

论文在LLaVA-NeXT-34B和MiniGemini-34B进行了实验,并在ConBench的ConScore[C]指标上进行了评估。值得注意的是,LLaVA-NeXT-34B的得分提高了9.1个点,而MiniGemini的总体提升为9.6个点。尽管我们的方法主要使用判断题进行自我验证,但在ConScore[C]上仍然有明显的改善。从理论上讲,可以进一步构建多个判别性问题来验证Caption中的多个单词。此外,这个过程可以进行多轮迭代,从而持续提升Caption的质量。本文的方法是上述方法的简化实现。


END
加入「大模型」交流群👇备注:VLM


















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









