







原文转自机器学习算法之线性模型
线性方程与非线性方程
线性方程:代数方程如y = 2x + 5,其中任何一个变量都为1次幂,这种方程的图像为一条直线(平面),所以称为线性方程
非线性方程:y**2 = 2x + 5,因变量和自变量之间不是线性关系,如平方关系、对数关系、指数关系和三角函数关系等
线性模型(线性回归;逻辑回归——对数几率回归)
目录
1、基本形式
给定有d个属性描述的示例; 线性模型试图学得一个通过属性的线性组合来进行预测的函数 ,即:
许多功能强大的非线性模型可以在线性模型的基础上通过引入层级结构或高维映射而得。 值的大小反映了某个属性的重要程度。
值的大小反映了某个属性的重要程度。
本部分共介绍三部分:1、回归问题,2、分类问题,3、多分类问题。
2、线性回归
线性模型试图学得f(x) = w*x + b,使得f(x)约等于y,如何确定w和b呢?这是一个组合问题,已知一些数据,如何求里面的未知参数,给出一个最优解。这是一个线性矩阵方程,直接求解很可能无法求解,有唯一解的数据集更是微乎其微,基本上都是解不存在的超定方程组。在这种情况下,我们将参数求解问题转化为误差最小化问题,求出一个最接近的解,这就是一个松弛求解。
均方误差作为回归任务中最常用的性能度量,因此我们可以试图让均方误差最小化
线性回归(Linear Regression)问题就是试图学到一个线性模型尽可能准确地预测新样本的输出值。均方误差是回归任务中最常用的性能度量,因此优化目标是最小化均方误差。基于均方误差最小化来进行模型求解的方法称为“最小二乘法”(least square method)。在线性回归中,最小二乘法就是试图找到一条直线,使得所有样本到直线上的欧式距离之和最小。求解w和b使均方误差最小化的过程,称为线性回归模型的最小二乘“参数估计(parameterestimation)”。更一般的样本由d个属性描述,此时称为多元线性回归
(1)当输入属性只有一个的时候,就是最简单的情形,也就是我们高中时最熟悉的“最小二乘法”(Euclidean distance),算法如下:1、首先计算出每个样本预测值与真实值之间的误差并求和,通过最小化均方误差MSE;2、分别对和b求偏导,另起等于0,计算出拟合直线y=wx+b的两个参数w和b,计算过程如下图所示:

(2)当输入属性有多个的时候,例如对于一个样本有d个属性,则y=wx+b需要写成:

通常对于多元问题,常常使用矩阵的形式来表示数据。在本问题中,将具有m个样本的数据集表示成矩阵X,将系数w与b合并成一个列向量,这样每个样本的预测值以及所有样本的均方误差最小化就可以写成下面的形式:



同样地,我们使用最小二乘法对w和b进行估计,令均方误差的求导等于0,需要注意的是,当一个矩阵的行列式不等于0时,我们才可能对其求逆,因此对于下式,我们需要考虑矩阵(X的转置*X)的行列式是否为0,若不为0,则可以求出其解,若为0,则需要使用其它的方法进行计算,书中提到了引入正则化,此处不进行深入。

另一方面,有时像上面这种原始的线性回归可能并不能满足需求,例如:y值并不是线性变化,而是在指数尺度上变化。这时我们可以采用线性模型来逼近y的衍生物,例如lny,这时衍生的线性模型如下所示,实际上就是相当于将指数曲线投影在一条直线上,如下图所示:

更一般地,考虑所有y的衍生物的情形,就得到了“广义的线性模型”(generalized linear model),其中,g(*)称为联系函数(link function)。

3、对数几率回归(逻辑回归)
3.1、极大释然估计
3.1.1、似然函数
似然(likelihood,可能性的意思),描述的是事件发生可能性的大小。
似然函数的定义:
设数据D=X1,…,XN为独立同分布(IID),其概率密度函数(pdf)为p(x|Ɵ),则似然函数定义为:

即为在给定数据D的情况下,参数为Ɵ的函数。
3.1.2、极大似然估计(MLE)
定义:使得似然函数L(Ɵ)最大的Ɵ的估计:

3.1.3、log似然函数
定义:
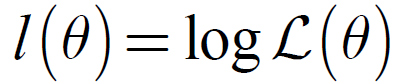
即:
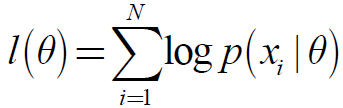
性质:
(1) 它和似然函数在相同的位置取极大值
(2) 在不引起混淆的情况下,有时记log似然函数为似然函数
(3) 相差常数倍也不影响似然函数取极大值的位置,因此似然函数中的常数项也可以抛弃
(4) 在分类中log似然有时亦称为交叉熵 (cross-entropy)
3.2、逻辑回归
回归就是通过输入的属性值得到一个预测值。针对分类任务:只需找一个单调可微函数将分类任务的真实标记y与线性回归模型的预测值z联系起来。

单位阶跃函数与对数几率函数

若将y看做样本为正例的概率,(1-y)看做样本为反例的概率,则上式实际上使用线性回归模型的预测结果器逼近真实标记的对数几率。因此这个模型称为“对数几率回归”(logistic regression),也有一些书籍称之为“逻辑回归”。下面使用最大似然估计的方法来计算出w和b两个参数的取值,下面只列出求解的思路,不列出具体的计算过程。


4、线性判别分析
线性判别分析(Linear Discriminant Analysis,简称LDA),其基本思想是:将训练样本投影到一条直线上,使得同类的样例尽可能近,不同类的样例尽可能远。如图所示:

 想让同类样本点的投影点尽可能接近,不同类样本点投影之间尽可能远,即:让各类的协方差之和尽可能小,不用类之间中心的距离尽可能大。基于这样的考虑,LDA定义了两个散度矩阵。
想让同类样本点的投影点尽可能接近,不同类样本点投影之间尽可能远,即:让各类的协方差之和尽可能小,不用类之间中心的距离尽可能大。基于这样的考虑,LDA定义了两个散度矩阵。
类内散度矩阵(within-class scatter matrix)

类间散度矩阵(between-class scaltter matrix)

因此得到了LDA的最大化目标:“广义瑞利商”(generalized Rayleigh quotient)。

从而分类问题转化为最优化求解w的问题,当求解出w后,对新的样本进行分类时,只需将该样本点投影到这条直线上,根据与各个类别的中心值进行比较,从而判定出新样本与哪个类别距离最近。求解w的方法如下所示,使用的方法为λ乘子。

若将w看做一个投影矩阵,类似PCA的思想,则LDA可将样本投影到N-1维空间(N为类簇数),投影的过程使用了类别信息(标记信息),因此LDA也常被视为一种经典的监督降维技术。
5、多分类学习问题
现实中我们经常遇到不只两个类别的分类问题,即多分类问题,在这种情形下,我们常常运用“拆分”的策略,通过多个二分类学习器来解决多分类问题,即将多分类问题拆解为多个二分类问题,训练出多个二分类学习器,最后将多个分类结果进行集成得出结论。最为经典的拆分策略有三种:“一对一”(OvO)、“一对其余”(OvR)和“多对多”(MvM),核心思想与示意图如下所示。
- OvO:给定数据集D,假定其中有N个真实类别,将这N个类别进行两两配对(一个正类/一个反类),从而产生N(N-1)/2个二分类学习器,在测试阶段,将新样本放入所有的二分类学习器中测试,得出N(N-1)个结果,最终通过投票产生最终的分类结果。
- OvM:给定数据集D,假定其中有N个真实类别,每次取出一个类作为正类,剩余的所有类别作为一个新的反类,从而产生N个二分类学习器,在测试阶段,得出N个结果,若仅有一个学习器预测为正类,则对应的类标作为最终分类结果。
- MvM:给定数据集D,假定其中有N个真实类别,每次取若干个类作为正类,若干个类作为反类(通过ECOC码给出,编码),若进行了M次划分,则生成了M个二分类学习器,在测试阶段(解码),得出M个结果组成一个新的码,最终通过计算海明/欧式距离选择距离最小的类别作为最终分类结果。


6、类别不平衡问题
类别不平衡(class-imbanlance)就是指分类问题中不同类别的训练样本相差悬殊的情况,例如反例有900个,而正例只有100个,这个时候我们就需要进行相应的处理来平衡这个问题。常见的做法有三种:
- 在训练样本较多的类别中进行“欠采样”(undersampling),即直接对训练集里面的反例去除一部分,使得正反例数目相当;比如从正例中采出100个,常见的算法有:EasyEnsemble。优点:时间开销较小。
- 在训练样本较少的类别中进行“过采样”(oversampling),例如通过对反例中的数据进行插值,来产生额外的反例,常见的算法有SMOTE。缺点,时间开销较大。
- 直接基于原数据集进行学习,对预测值进行“再缩放”处理。其中再缩放也是代价敏感学习的基础。

其中 反映了正例可能性与反例可能性之比值,阈值常设置为0.5(y的值)恰表明分类器认为真实正、反例可能性相同。然而训练集中正、反例数目不同时,令
反映了正例可能性与反例可能性之比值,阈值常设置为0.5(y的值)恰表明分类器认为真实正、反例可能性相同。然而训练集中正、反例数目不同时,令 ![]() 表示正例数目,
表示正例数目,![]() 表示反例数目,则观测几率为
表示反例数目,则观测几率为 。公式的意义在于正例
。公式的意义在于正例![]() 很小,反例
很小,反例![]() 很大,因此需要增大阈值,使得预测值很大时才有可能是正例。
很大,因此需要增大阈值,使得预测值很大时才有可能是正例。

















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









