






 本文建立了一个基于Python的逻辑回归模型,使用NBA球员的历史和现役数据,预测球员是否能进入名人堂。通过数据预处理、特征筛选、WOE转换和模型拟合,得到了一个评分卡模型。训练集的KS值为85,AUC值为96,模型预测了现役球员的名人堂入选可能性。
本文建立了一个基于Python的逻辑回归模型,使用NBA球员的历史和现役数据,预测球员是否能进入名人堂。通过数据预处理、特征筛选、WOE转换和模型拟合,得到了一个评分卡模型。训练集的KS值为85,AUC值为96,模型预测了现役球员的名人堂入选可能性。
模型目的:
本模型将基于逻辑回归模型,对历史和现役的nba球员数据进行建模,以是否进入名人堂作为模型预测的目标值进行预测,构建评分卡。以退役的nba球员数据和作为训练集来进行模型拟合,来预测现役球员中,谁进入名人堂的可能性更高。本模型最后产出为现役球员在当前的统计数据下入选名人堂的分数。
以下为建模部分
一. 环境准备:
1.1 编程语言:
Python 3.7.0
1.2 主要依赖的第三方包:
pandas, toad, scorecardpy, nba_api
1.3 数据准备:
数据来源:
nba_api: nba_api is an API Client for www.nba.com. This package intends to make theAPIs ofNBA.comeasily accessible and provide extensive documentation about them.
本模型将使用python第三方包nba_api中的api数据,初始建模指标主要包含以下四个部分的数据:
球员常规赛各项总数据。包含:总上场时间、总得分、总投篮次数、总投篮命中数等共计21个指标;
球员季后赛各项总数据。包含:总上场时间、总得分、总投篮次数、总投篮命中数等共计21个指标;
球员历史荣誉。包含:一阵次数、二阵次数、mvp次数等共计29个指标。其中,“Hall of Fame Inductee”(是否入选名人堂)为我们这次建模的y值,入选为1,不入选为0。
球队历史荣誉。包含:球队总冠军,如果某一球员在某一球员夺冠赛季中有过效力,则为拥有总冠军,共计1个指标。
所有数据通过球员id进行数据关联,本模型将使用所有nba历史及现役的且在nba有过常规赛和季后赛数据的球员作为建模样本,共计2800位球员,即2800条建模数据。
其中,将退役球员作为训练集,共计2465位球员,在这2465位球员中,有123位球员已入选名人堂,占比4.9%。本模型不设测试集,将使用在训练集上拟合的模型直接对剩余的335位球员进行预测,返回评分情况。
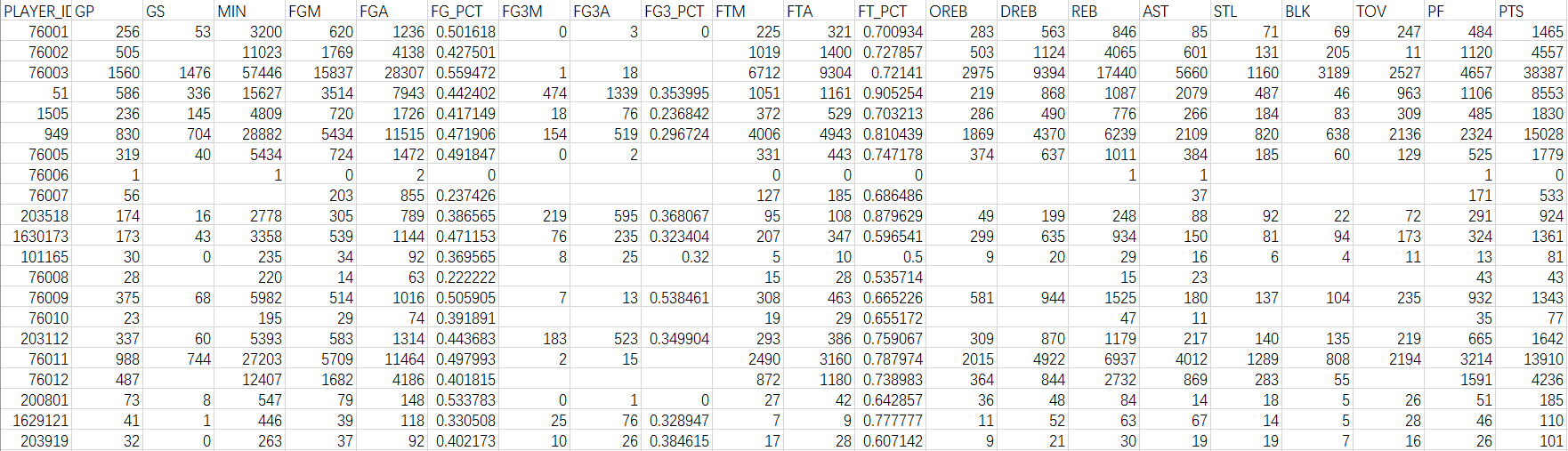
图1 常规赛数据
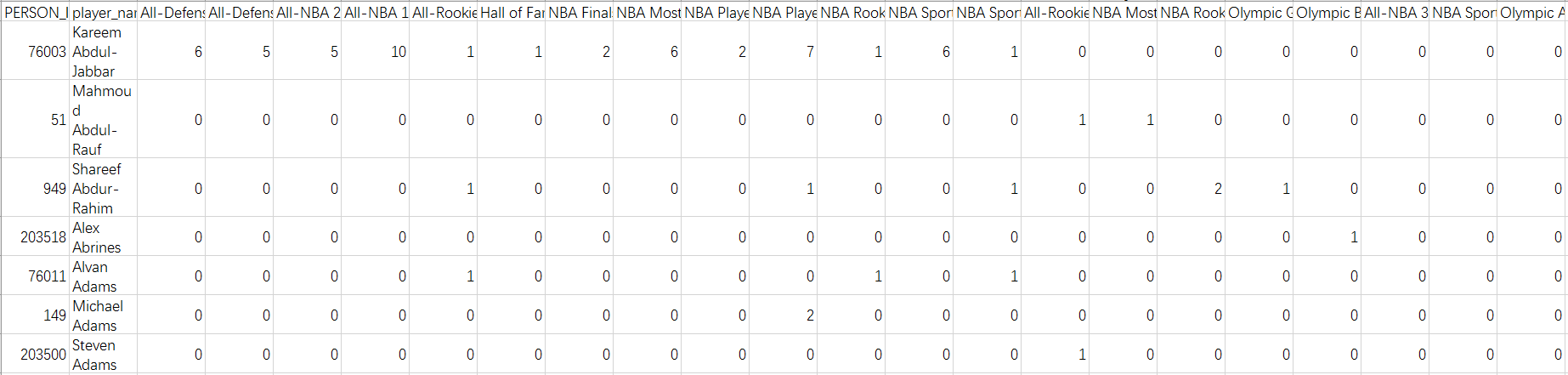
图2 个人荣誉数据
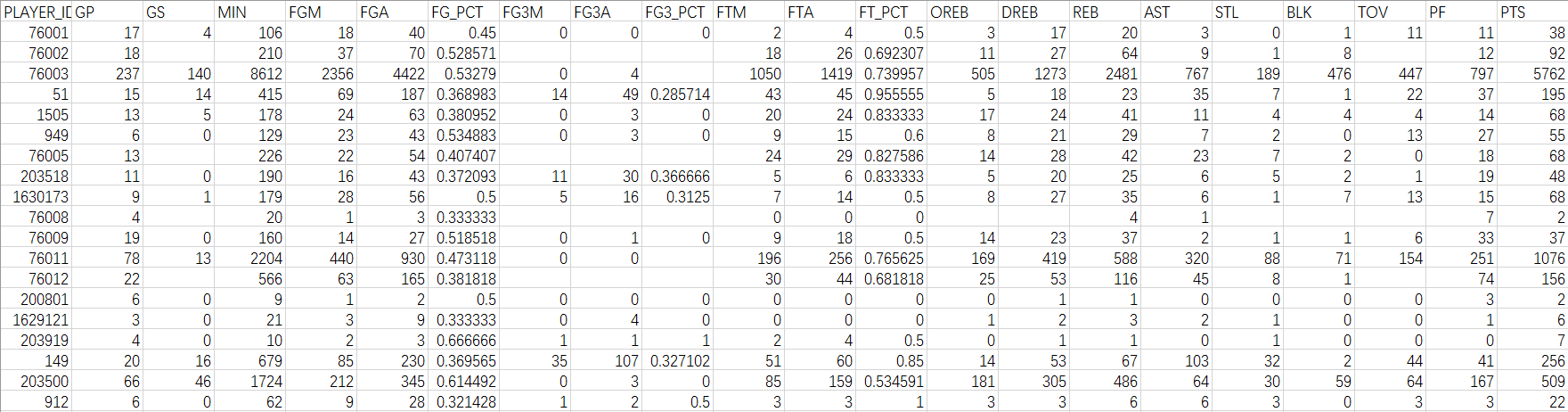
图3 模型KS和AUC值
数据获取时间为2023.03.14
二. 数据处理与特征筛选:
主要包含以下内容:
剔除缺失值高于0.9的特征(不是所有的球员都有个人荣誉信息);
剔除iv值低于0.05的特征;
剔除相关性大于0.75的特征;
对剩余的数据的缺失值进行缺失值填充;
剔除部分远古球员缺失的特征(如周最佳次数、月最佳次数等);
完成该部分后,模型还剩余35个特征。
三. 特征变换:
将上面已处理完的特征进行woe转换,将特征情况转换为woe值。本部分将使用scorecardpy的woe_bin方法进行分箱,分箱方法为卡方分箱。
此处为了使得总冠军次数等特征变得更有区分度,将对部分特征进行手动切分分箱点,提高分箱的区分性。

图4 分箱节点调整
四. 模型拟合:
使用逻辑回归建模,将转换后的建模数据进行模型拟合,得到拟合的模型,并对335条现役球员的数据进行预测,得出预测分。
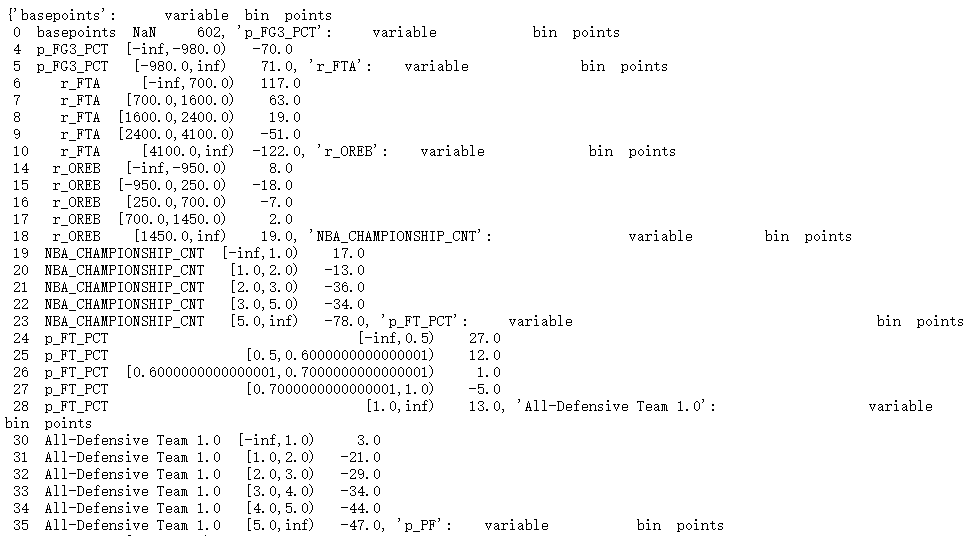
图5 评分分箱情况
五. 模型评估:
本模型训练集的ks值为85,auc值为96。
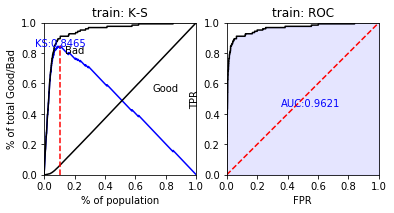
图6 模型KS和AUC值
时间仓促,跑完之后一看数据感觉还行,就没有进行多余的优化了,主要还有以下几个部分可以进行优化:
建模数据可以进一步完善。如引入球员场均数据、per36数据、高阶数据等;
划分训练集和测试集。主要用来观察模型是否过拟合,但鉴于本模型正样本比较少,且效果还行,就没有划分测试集了。本模型可能会存在一定的过拟合。
调参。模型参数调整与不同样本浓度的设定。
多种模型的拟合预测和对比。本模型直接选用了逻辑回归模型,但亦可以选用xgb、决策树等算法进行多模型之间的比较。
建模步骤并未完整。woe转换后应再进行一次变量相关性处理。
Y值的滞后性。由于球员退役后需要一定的时间才能进入到名人堂,故近期退役的球员可能够得上名人堂的入选,但由于时间还没够,暂没有入选(如文斯卡特),该部分少量数据亦会影响模型本身的效果。
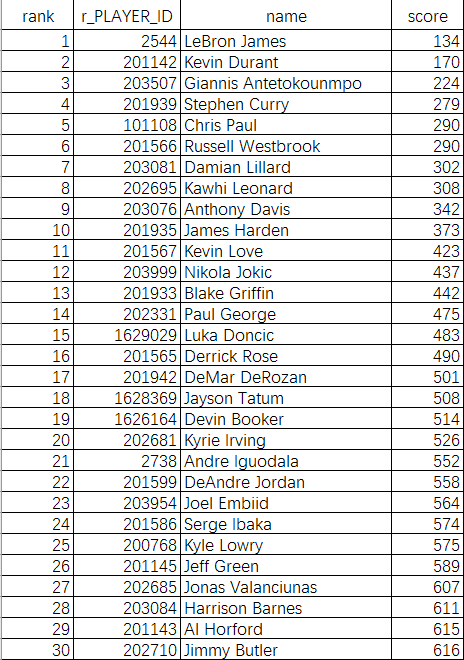
图7 模型所预测的现役入选名人堂前三十球员
写在后面:
本文是一个技术帖,不希望各球星粉丝进行battle,有什么意见和想法的可以在下面进行讨论。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











