







效果:
将n多个xlsx文件所有xlsx都取Sheet1表格 抽取指定得行列 并排列到新的Sheet1表格当中
如 表格1内容如下

表格2内容如下

表格数量不限制。都是要取
期望拿到坐标b2-c3的所有数据并放入表格0当中

参数 如果不是从b2 到c3可以自己配置下这个开始坐标和结束坐标坐标概念如下。
# 开始坐标点
start = [1, 1]
# 结束坐标点
end = [2, 2]
# 1,1 1,2 1,3 1,4
# 1,1 1a1 1b1 1c1
# 1,2 1a2 1b2 1c2
# 1,3 1a3 1b3 1c3
直接贴代码
针对 excel 2017 既是 0.xlsx
excel_xlsx.py
import os
# 读写2007 excel
import openpyxl
def readExcel(path, outputFiles):
# 选中开始
# 开始坐标点
start = [1, 1]
# 结束坐标点
end = [2, 2]
# 1,1 1,2 1,3 1,4
# 1,1 1a1 1b1 1c1
# 1,2 1a2 1b2 1c2
# 1,3 1a3 1b3 1c3
wb = openpyxl.load_workbook(path)
outWb = openpyxl.load_workbook(outputFiles)
sheet = wb['Sheet1']
outSheet = outWb['Sheet1']
rows = sheet.max_row
columns = sheet.max_column
outSheetMaxRows = outSheet.max_row
if (outSheetMaxRows == 1):
outSheetMaxRows = 0;
for i in range(rows):
if (i < start[0] or i > end[0]):
continue
for j in range(columns):
if (j < start[1] or j > end[1]):
continue
cellvalue = sheet.cell(row=i + 1, column=j + 1).value
outSheet.cell(row=i + 1 - start[0] + outSheetMaxRows, column=j + 1 - start[1], value=cellvalue)
print(cellvalue, "\t", end="")
print()
outWb.save(outputFiles)
def main():
outputFiles = r"fileslist\0.xlsx"
for root, dirs, files in os.walk("fileslist"):
for file in files:
fileName = os.path.join(root, file)
if (fileName.endswith(outputFiles)):
continue
print("当前表格:" + fileName)
readExcel(fileName, outputFiles)
print()
pass
if __name__ == '__main__':
main()如何使用
1、在main.py同级目录下新建fileslist文件目录

在目录中新建一个空白的xlsx 命名为 0.xlsx 这个是最后要导出的文件夹

将其他要处理的数据全部复制进来。如1.xlsx,2.xlsx(名字不做限制,这里面所有的文件都会被遍历然后写进0.xlsx)
2、安装 python
下载地址:Python Releases for Windows | Python.org

下载后安装即可
安装成功 将安装目录的路径配置到环境变量当中
在 Windows 设置环境变量
在环境变量中添加Python目录:
在命令提示框中(cmd) : 输入
path=%path%;C:\Python 按下 Enter。
注意: C:\Python 是Python的安装目录。
也可以通过以下方式设置:
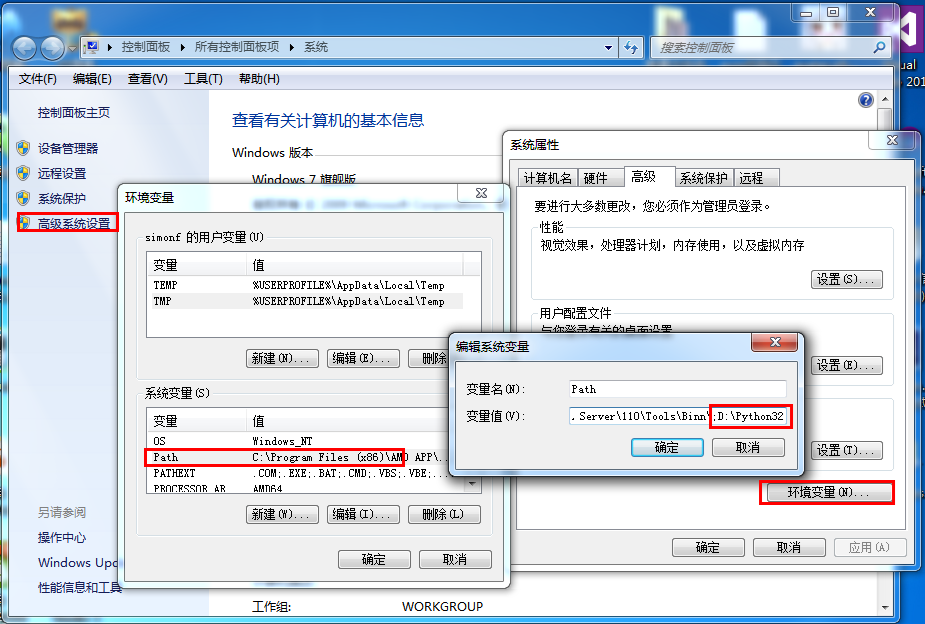
- 右键点击"计算机",然后点击"属性"
- 然后点击"高级系统设置"
- 选择"系统变量"窗口下面的"Path",双击即可!
- 然后在"Path"行,添加python安装路径即可(我的D:\Python32),所以在后面,添加该路径即可。 ps:记住,路径直接用分号";"隔开!
- 最后设置成功以后,在cmd命令行,输入命令"python",就可以有相关显示。
3、安装 openpyxl
直接cmd执行
pip install openpyxl4 执行脚本
python excel_xlsx.py针对xls仍然做了一个适配。但是没有合并到一起。合并的话工作量就大了得加钱
5 适配xls文件
excel_xls.py文件
import os
# 读写2007 excel
import xlrd
import xlwt
from xlutils.copy import copy
def readExcel(path, outputFiles):
# 选中开始
# 开始坐标点
start = [1, 1]
# 结束坐标点
end = [2, 2]
# 1,1 1,2 1,3 1,4
# 1,1 1a1 1b1 1c1
# 1,2 1a2 1b2 1c2
# 1,3 1a3 1b3
workbook = xlrd.open_workbook(filename=path)
sheets = workbook.sheet_names()
worksheet = workbook.sheet_by_name(sheets[0])
outWorkbook = xlrd.open_workbook(outputFiles)
outSheets = outWorkbook.sheet_names()
outWorksheet = outWorkbook.sheet_by_name(outSheets[0])
rows = worksheet.nrows
columns = worksheet.ncols
outSheetMaxRows = outWorksheet.nrows
outExcel = copy(outWorkbook)
outWorksheet =outExcel.get_sheet(0)
if (outSheetMaxRows == 1):
outSheetMaxRows = 0;
for i in range(rows):
if (i < start[0] or i > end[0]):
continue
for j in range(columns):
if (j < start[1] or j > end[1]):
continue
cellvalue = worksheet.cell_value(rowx=i, colx=j)
outWorksheet.write(i - start[0] + outSheetMaxRows, j - start[1], cellvalue)
print(cellvalue, "\t", end="")
print()
outExcel.save(outputFiles)
def main():
output_files = r"fileslist\0.xls"
for root, dirs, files in os.walk("fileslist"):
for file in files:
fileName = os.path.join(root, file)
if fileName.endswith(output_files):
continue
print("当前表格:" + fileName)
readExcel(fileName, output_files)
print()
pass
if __name__ == '__main__':
main()
要额外安装三个库
pip install xlutils
pip install xlwt
pip install xlrd装好了可以执行下面命令
python excel_xlsx.py















 1648
1648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











