









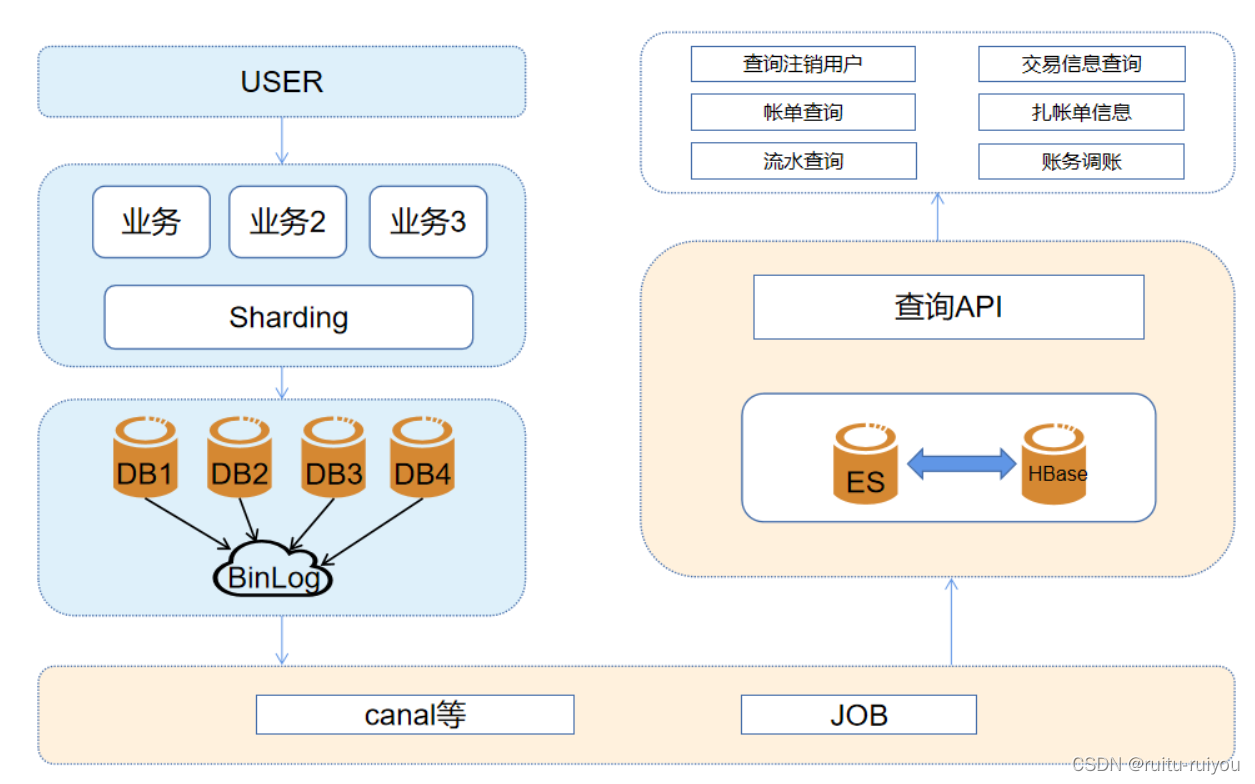
上图中淡黄色部分提供了分库分表后的数据聚合及查询功能。
问题1:为什么不选择MongoDB
- MongDB的二级索引必须全部要存储在内存中,如果内存 空间不够,会有一部分索引失效,导致查询慢;
- MongDB在数据量非常的大的时候,查询的速度没有ES快, 特别是在复杂多条件查询的时候,表现更为明显
问题2:为什么不单独使用HBASE
- HBase在没有rowKey的查询条件下,要用过滤器对HBase表所有region的进行扫描,非常耗时,效率非的低,在有大量写的情况,查询的性能会更糟糕,当前的业务需求,是有非常多的维
度查询; - HBase不包含统计的功能,除非用MapReduce Job跑后台离线任务;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









