







 本文探讨SharePoint咨询师如何提供解决方案,重点分析设计前的体系结构,包括容量管理、规模和角色定义。文章详细阐述了SharePoint Server 2013的物理体系结构,如Web服务器、爬网服务器、管理服务器、应用服务程序服务器、数据库服务器等角色,以及适用于不同规模的服务器场部署策略,如单服务器场、小型场、中型场和大型场的架构特点。
本文探讨SharePoint咨询师如何提供解决方案,重点分析设计前的体系结构,包括容量管理、规模和角色定义。文章详细阐述了SharePoint Server 2013的物理体系结构,如Web服务器、爬网服务器、管理服务器、应用服务程序服务器、数据库服务器等角色,以及适用于不同规模的服务器场部署策略,如单服务器场、小型场、中型场和大型场的架构特点。
提示:本系列只是一个学习笔记系列,大部分内容都可以从微软官方网站找到,本人只是按照自己的学习路径来学习和呈现这些知识。有些内容是自己的经验和积累,如果有不当之处,请指正。
咨询师更多的时候是解决方案提供者,那么他们如何能够提供有效的SharePoint解决方案呢?他们做出解决方案的依据是哪些呢?这就是我们需要了解的设计之前的那些事。
它通常包括:
定义:
体系结构就是定义一组元素以及元素间的联系。SharePoint Server的体系结构包括:根据位置划分的物理结构和根据功能划分的逻辑结构。
本篇文章主要分析SharePoint Server 2013的物理体系结构。大部分资料都是从一个整体的SharePoint服务器场结构开始,然后一步步分析服务器场内个服务器的作用来介绍服务器场的体系结构。这里我们却采用不同的方法, 我们先来分析SharePoint服务器场内可能存在的服务器角色, 通过对服务器角色和功能的了解,然后进行组合成不同规模的服务器场。
注:角色的区分不是必须的,而是是根据服务器场的规模、客户对性能要求而划分的。比如对于用于研究和开发的服务器场,所有的角色都可以集中在同一台服务器上。
- Web服务器
- Web 服务器: SharePoint 自带的页面, web服务,Web Parts的宿主服务器; 负责所有的用户请求
- 爬网专用web服务器 : 不用于处理用户需求,专门用来爬网,这样保证了爬网的压力不会被分配到其他web服务器, 从而提高web服务器响应用户请求的能力。
- 管理专用web服务器:部署SharePoint管理中心的web服务器
- 应用服务程序服务器
- Query,Index专用服务器:由于SharePoint的搜索功能会占用大量的资源,一本情况下建议用专门服务器部署搜索相关的服务
- Crawl专用服务器
- Sandbox专用服务器
- User Profile 服务器:当用户站点被启用并被在企业内部大量使用时,建议用专门服务器部署User Profile服务
- Workflow 服务器:工作流服务器
- 其他特殊的专用服务器如:Excel caculation, performancepoint, project….
- 数据库服务器
- Search 专用数据库服务器:用专门数据库服务器存储与搜索相关的数据
- Content/configuration数据库服务器:内容数据库以及SharePoint自身的配置数据库
- 其他SharePoint数据库服务器如 User Profile, Managed Metadata….
- 其他服务器
- Dedicated distributed cache service: SharePoint 2013新的应用程序:http://www.jeremytaylor.net/2013/04/22/sharepoint-2013-distrbuted-cache-service/
- 硬件负载均衡服务器
SharePoint服务器场还可能包含其他功能性的服务器,但是这里主要列举了可能被经常用到的功能性服务器。
体系结构
了解完SharePoint 服务器场中服务器的角色,就能很容易的通过组合这些不同的角色服务器而得到所需服务器场的体系结构。
单服务器SharePoint场
单一服务器部署体系结构就是在一台机器(可以是虚拟机)安装SharePoint Server和SQL Server,所有的应用程序服务都运行在一台服务器。 此体系可用于评估,开发或者只有少数用户的使用的情况。

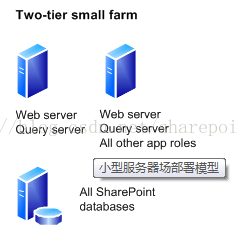
小型SharePoint场
小型服务器场是由一台数据库(2)与一台或者两台基于SharePoint Server 的计算机组成。 主要体系结构特征包括有限的冗余和故障转移,并启用了最基本的应用程序服务比如:User Profile, Secure Store. 此体系结构只要勇于较小的用户群、相对较低的使用负载(每分钟几个/每秒钟几个)以及相对较少的数据量(一般几十GB)。
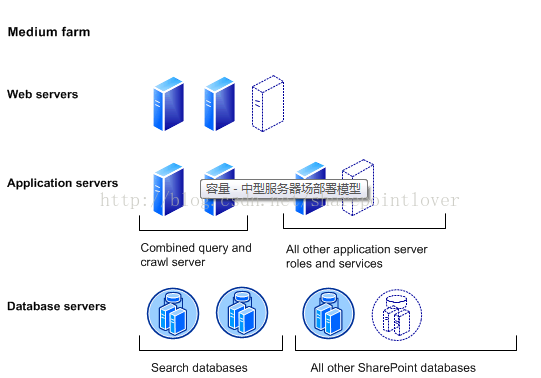
中型SharePoint场
此体系结构的特征一本是分为三层:专用的web服务器,专用的应用程序服务器以及一个或者多个数据库服务器或者集群。根据公司常用功能不同进行部署应用程序服务。 比如公司偏重数据的检索,就需要把搜索数据库以及搜索应用程序服务分别部署到不同的服务器。
此体系的服务器场可以满足一下需求:
- 支持用户群为数万用户
- 负载为每秒10-50个
- 数据存储为1/2TB(如果采用RBS,可以支持更多)
- 易扩展
大型SharePoint场
对于超大型服务器场,没有实际经验,只能从微软官方网站获得一些信息。当你需求是如下之一时,你就需要考虑大型服务器场了。
- 用户群是10万级别
- 负载范围是每秒数百
- 数据量时10TB















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









