






【论文翻译】:(arxiv 2024)ReLUs Are Sufficient for Learning Implicit Neural Representations ReLU 足以学习隐式神经表示
Code:https://github.com/joeshenouda/relu-inrs
摘要
由于对采用整流线性单元(ReLU)作为其激活函数的神经网络的理论理解不断增长,我们重新审视了使用ReLU激活函数来学习隐式神经表征(inr)。受二阶b样条小波的启发,我们在深度神经网络(DNN)的每一层的ReLU神经元中加入了一组简单的约束来弥补频谱偏差。这反过来又使其能够用于各种INR任务。根据经验,我们证明,与普遍的看法相反,人们可以基于仅由ReLU神经元组成的DNN学习最先进的inr。接下来,通过利用最近描述ReLU神经网络学习的各种函数的理论工作,我们提供了一种量化学习函数的规律性的方法。这为在INR体系结构中选择超参数提供了一种有原则的方法。我们通过信号表示、超分辨率和计算机断层扫描实验证实了我们的观点,证明了我们方法的多功能性和有效性。
1. Introduction
最近,训练深度神经网络(dnn)来学习内隐神经表征(INRs)已经在各种视觉相关任务中取得了进展。这些包括但不限于计算机图形学、图像处理和信号表示。它们在生物医学成像方面也显示出巨大的前景,可以用于稀疏视图计算机断层扫描(CT)。许多INR任务涉及学习图像的连续表示,这与在高维数据上训练dnn的图像分类任务不同。inr通过在图像的低维坐标上训练DNN来学习图像的连续表示。对于这样的成像任务,INR的成功取决于深度神经网络有效近似和学习图像高频成分的能力。到目前为止,具有ReLU激活的dnn使用是收到限制的,因为它们已经显示出光谱偏差-ReLU深度神经网络的固有偏差导致它们在通过梯度下降训练时难以接近高频函数。
因此,为了规避这一问题,同时仍然利用神经网络的力量,INR社区的从业者采用了预处理技术和许多非标准激活函数。这些包括,但不限于,正弦函数、高斯函数、和复杂的Gabor小波。然而,使用这些高度非正统的激活函数对inr的理论性质提出了许多问题。因此,由于我们对神经网络的大部分理论理解都是基于标准的ReLU dnn,我们重新审视了使用ReLU激活来学习inr的事实。考虑这种形式的浅ReLU神经网络:
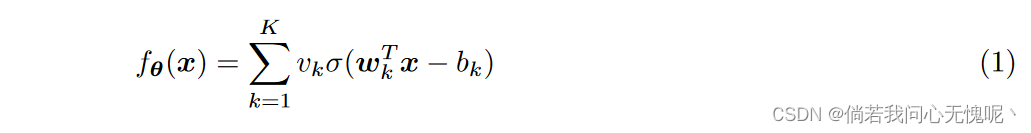
其中
σ
(
z
)
=
m
a
x
{
0
,
z
}
\sigma (z) = max \{0,z\}
σ(z)=max{0,z}。神经网络函数是一组“原子函数”的线性组合——在这种情况下是ReLU神经元。ReLU激活函数的单调递增性质意味着每个ReLU神经元都对该函数有全局贡献,并且与其他神经元高度一致。当试图将这个网络拟合到数据中时,如果一个神经元的权重发生变化,层中的所有其他神经元也必须调整以纠正该神经元的影响。这使得函数对参数的微小变化高度敏感,并导致严重的病态优化问题。当使用梯度型优化方法训练网络时,即使使用现代优化器(如Adam),这种不良条件也要求进行过多的迭代。这个问题在INR任务中更加严重,因为INR任务中的数据是密集采样的、低维的并且呈现高频率。
在这一简单见解的指导下,我们的调查采用了与以前的工作不同的方法,并且只关注于补救优化问题。这与完全取代产生我们特征的神经元的激活功能形成对比。具体而言,我们研究了基于局部relu的激活函数是否可以有效地解决和克服病态。为了做到这一点,我们建议在ReLU DNN的每个隐藏层中对ReLU神经元组进行约束。对于每一组,所有的神经元都有相同的权重。我们的约束确保隐藏层中每7个ReLU神经元都有效地应用激活函数
ψ
(
x
)
:
R
→
R
\psi(x):\R \rightarrow \R
ψ(x):R→R:
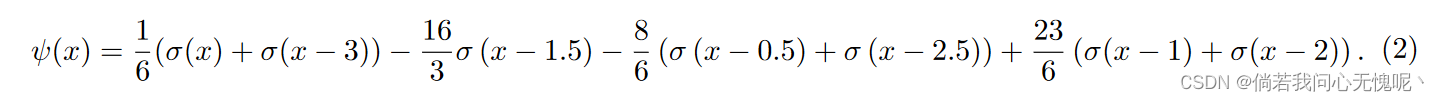
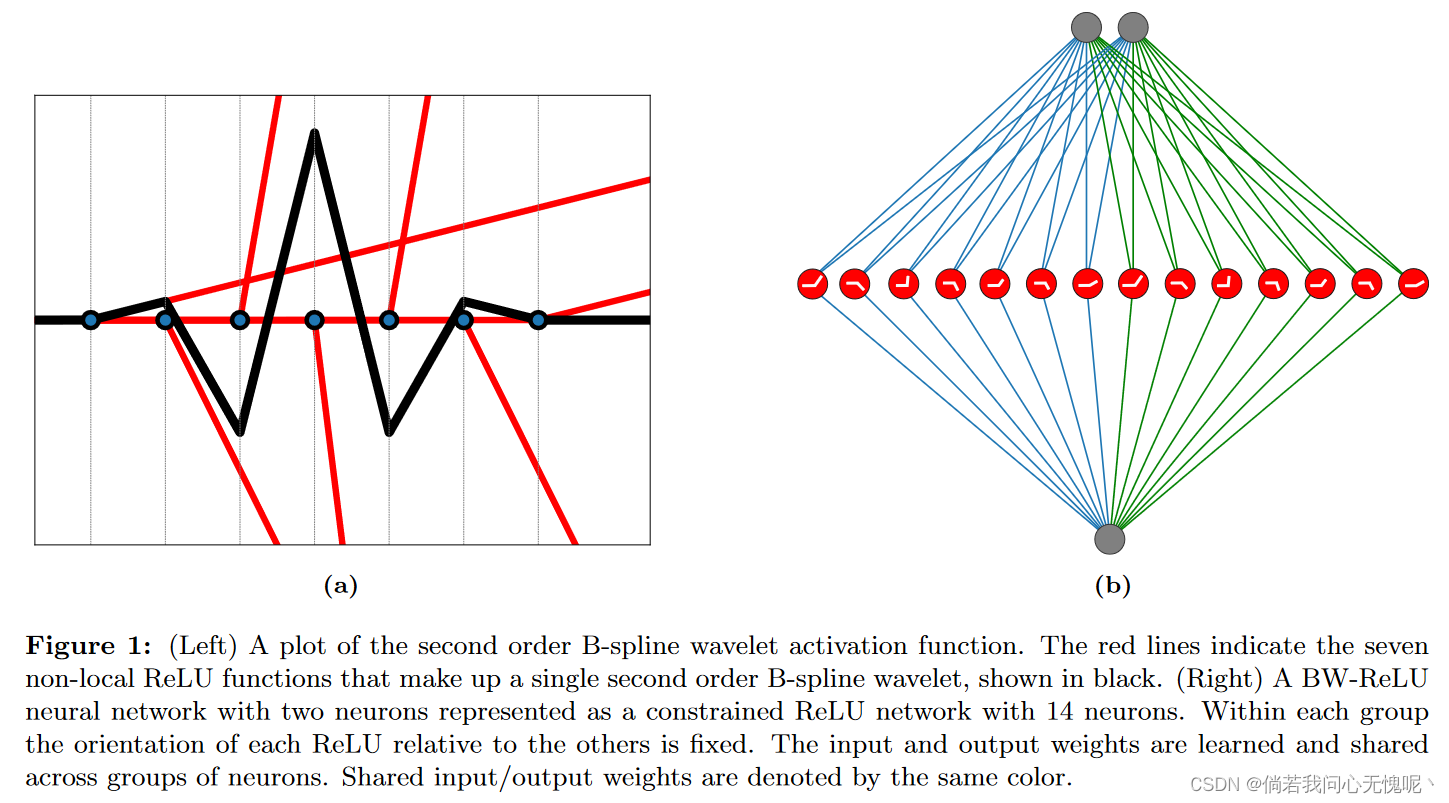
该激活函数对应于Chui和Wang(1992)引入的二阶b样条小波;Unser等人(1993)。单变量情况下的二阶b样条小波图如图1(a)所示。为了便于说明,我们将使用该激活函数的神经网络简称为BW-ReLU神经网络。
因此,在训练形式为BW-ReLU的神经网络时,表示为:
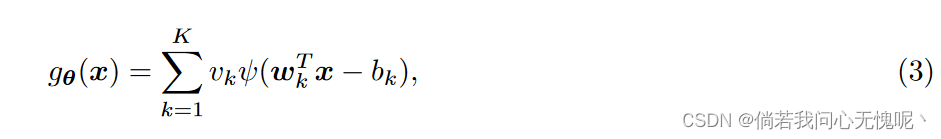
我们仍然在学习一个函数,这个函数可以用一个有7K个神经元的ReLU神经网络精确地表示,如图1b所示。在直观的层面上,这些神经元的紧凑特性允许每个神经元适应功能的不同部分,而不会影响其他神经元的贡献。 在第3节中,我们提供了一个更深入的讨论病态和如何BW-ReLU的独特性质可以补救它。我们在第5节中的实验证明了这种方法在各种INR任务上的有效性。
接下来,我们开发了一种学习基于ReLU的inr的方法,利用最近发展的理论来描述ReLU神经网络在拟合数据时学习的函数类型。我们展示了我们的BW-ReLU神经网络函数如何适应这个数学框架,以及我们如何测量这些函数的变异范数。这提供了对学习函数的规律性的度量。当我们用缩放参数 c > 0 c > 0 c>0重新参数化INR,使得神经元被定义为 v ⋅ ψ ( c ⋅ ( w T x − b ) ) v·ψ(c·(w^T x−b)) v⋅ψ(c⋅(wTx−b))时,我们还对如何影响这种规律性给出了新的见解。这种启发式方法在为inr引入的所有激活函数中都得到了应用,尽管人们对它知之甚少。此外,我们还展示了BW-ReLU神经网络的变异范数如何很好地指示了网络对未知数据的泛化能力。这建议了一种有原则的方法来调优inr,而不需要额外的验证数据集。总之,我们的贡献是:
- 一种基于ReLU的inr学习方法:通过在ReLU神经网络的神经元上加入一组简单的约束,我们可以克服ReLU网络固有的病态。我们证明了这种方法可以用于多个INR任务,并且与使用非常规激活函数的其他INR架构的性能相当。
- 关于INR泛化的见解:我们提出了一种方法来衡量BW-ReLU神经网络的规律性,通过利用最近关于ReLU神经网络学习的各种函数的理论结果。这种规律性是用变异范数来衡量的。我们讨论了这一观点如何为学习inr中使用的一些启发式方法提供见解,以及具有较低变异范数的BW-ReLU神经网络如何倾向于更好地泛化。
2. Related Works
ReLU可能是dnn中使用的最简单的激活函数。因此,最近的DNN理论大部分都集中在这个设置上。它们在实践中也很有用,因为它们诱导稀疏激活,可以用于压缩或加速推理。然而,由于其频谱偏差,具有ReLU激活的神经网络通常不用于INR任务。为了解决这个问题,预处理技术和非常规激活函数与传统的ReLU dnn一起或代替它们使用。我们的研究结果表明,基于relu的深度神经网络可以训练各种INR任务,从而对这些非正统方法的必要性提出了质疑。我们的方法受到b样条小波的启发,该小波最初由Chui和Wang(1992)开发和研究;Unser等人(1993,1992)。此外,我们的BW-ReLU神经网络与最初由Candes(1998)开发和研究的脊波概念非常相关。
3. Remedying the Spectral Bias of ReLU Neural Networks 修正ReLU神经网络的频谱偏差
在本节中,我们将更深入地讨论为什么ReLU神经网络在训练以适应低维数据集时倾向于表现出频谱偏差。我们形式化了引言中提出的直觉,并解释了ReLU神经元之间的强相干性如何导致病态优化问题,这大大减缓了收敛速度。我们还讨论了二阶b样条小波的关键性质,它纠正了这种不良条件(以及因此产生的频谱偏差),使它们适合于INR任务。考虑用形式为的单变量ReLU神经网络
f
:
D
→
R
f: D→R
f:D→R逼近单变量函数
u
:
D
→
R
u: D→R
u:D→R:
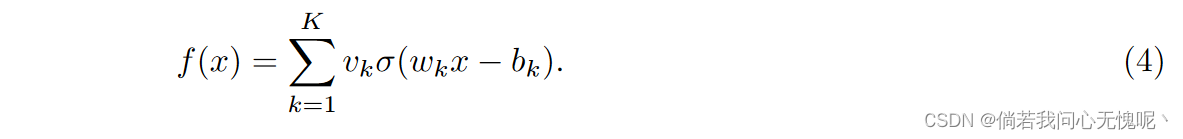
中间部分感兴趣的自己去读吧,大概内容是作者首先经过一些约束对ReLU DNN进行了形式变换,将INR低维度采样优化转变为了一个矩阵最小化问题,证明了ReLU DNN的特征矩阵条件数会随着神经元数目进行次方增长导致求解的困难。
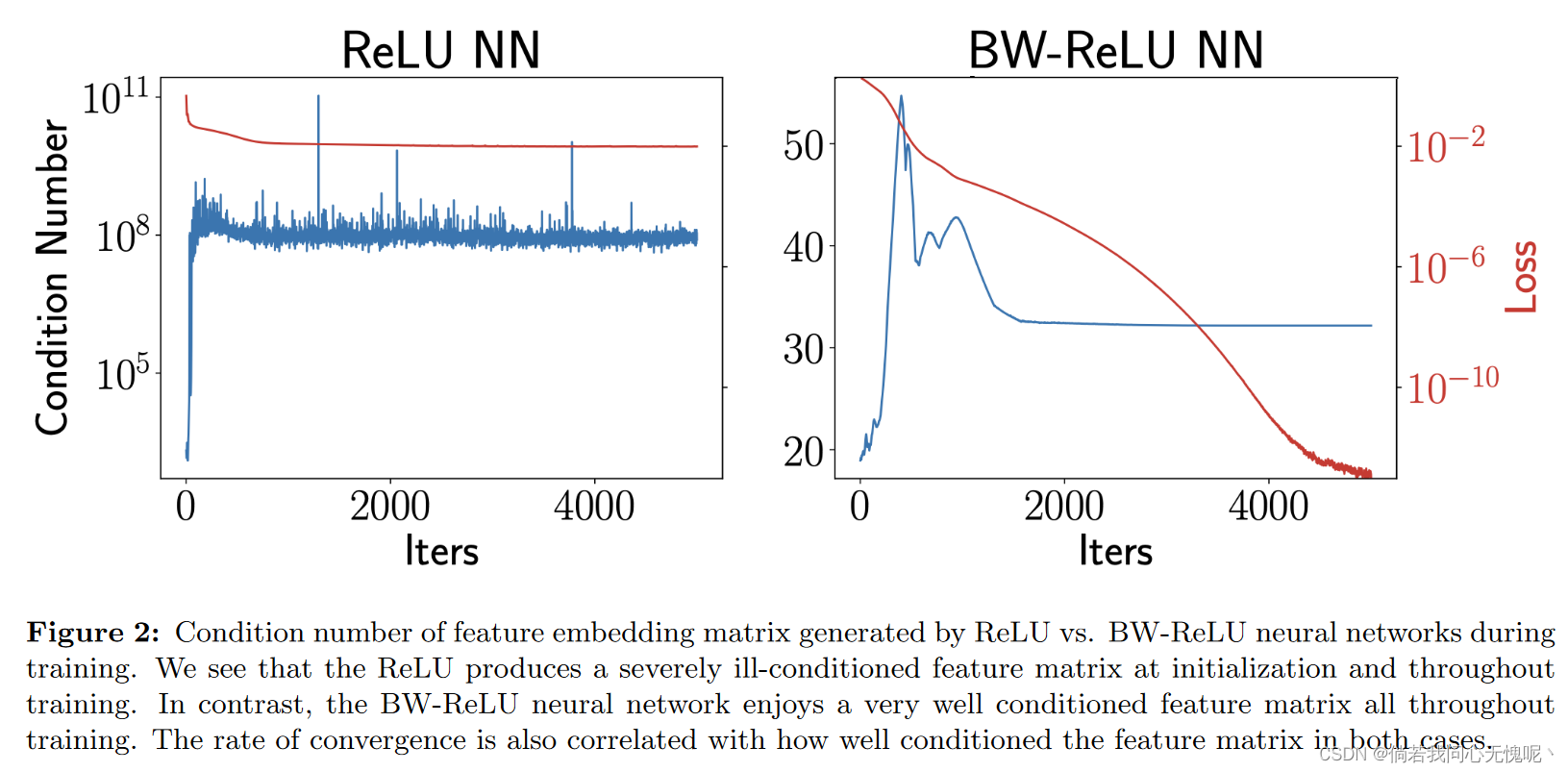
在图2中,我们给出了一个数值示例,说明了当使用ReLU或BW-ReLU神经网络拟合单变量函数时,特征嵌入矩阵的条件数在训练过程中如何变化。这说明了BW-ReLU神经网络的特征嵌入的Gram矩阵在初始化和整个训练过程中都保持良好的条件,而ReLU神经网络在整个训练过程中都受到条件差的特征嵌入矩阵的影响。我们还看到,条件良好的特征嵌入矩阵与更快的收敛速度相关。此外,我们在第5节中的实验也表明,深度BW-ReLU神经网络不容易受到这种不良条件的影响,可以用于实际的INR任务。、
高斯小波和Gabor小波也被用作INR任务的激活函数,因为它们具有局域性。然而,很少有理论描述这种网络学习的函数类型以及它们的超参数对学习函数的影响。(其实人家也通过二阶矩证明了如何挑选适合INR拟合的激活函数) 在下一节中,我们将利用我们最终学习ReLU神经网络的事实。这使我们能够利用与ReLU神经网络相关的函数空间的许多最新理论特征,从而深入了解训练inr时使用的一些启发式方法。
5. Experiments
在这里,我们展示了我们的BW-ReLU神经网络如何在三个INR任务中与其他INR架构一样有效。我们将我们的方法与SIREN、WIRE和ReLU+PE进行了比较。位置编码是一种将低维坐标映射到高维傅立叶特征的预处理技术。对每个INR体系结构的超参数进行了调优,以获得最佳结果。对于我们所有的实验,我们使用了一个三隐藏层DNN,并使用Adam优化器进行训练。所有实验的完整训练细节都可以在附录d中找到。此外,所有重现实验的代码都可以在https://github.com/joeshenouda/relu-inrs上找到。
5.1 Computed Tomography(CT) Reconstruction
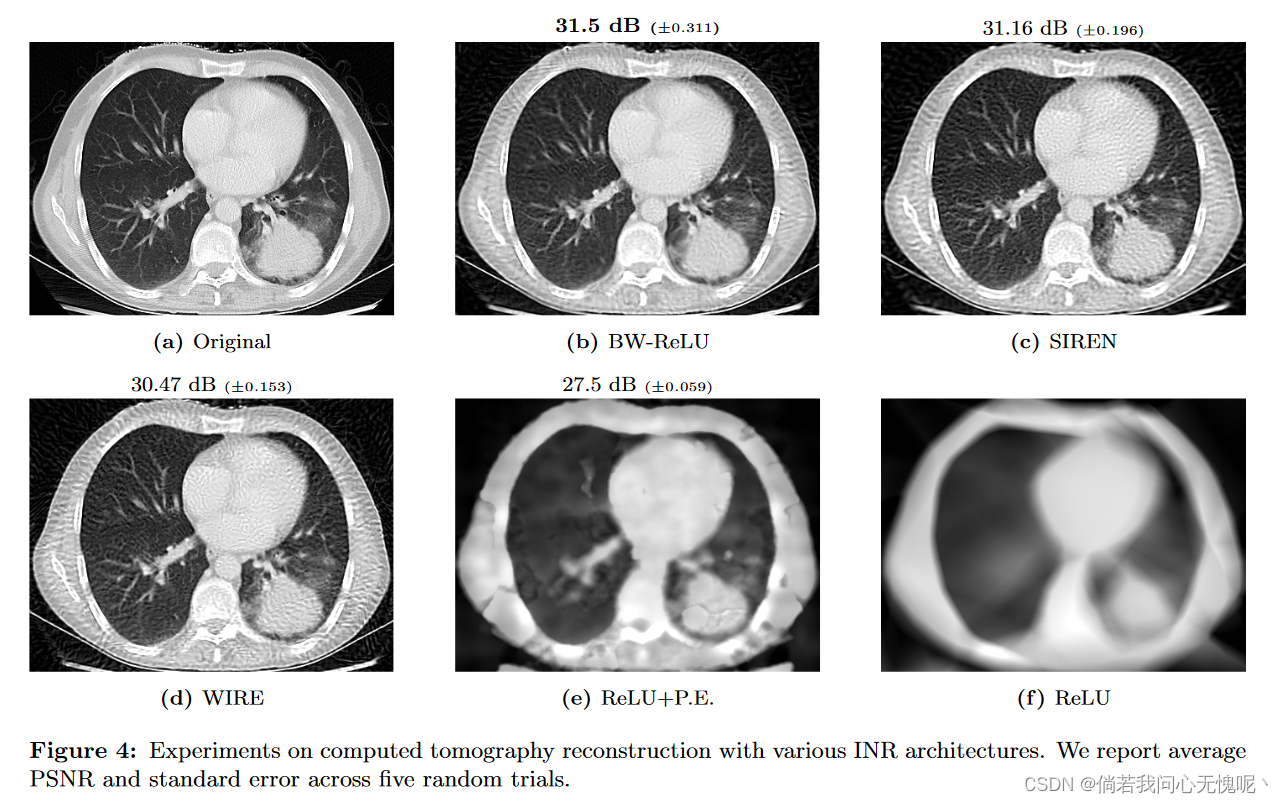
在本实验中,我们通过对326 × 435胸片图像进行100次等间隔CT测量来模拟CT重建(Clark et al., 2013)。图4显示了与其他INR体系结构相比的结果,表明我们的BW-ReLU神经网络的性能与传统的INR体系结构一样好,甚至可能略好。
5.2 Signal Representation
在这个实验中,我们将四种INR架构拟合到标准的256 × 256相机图像中。结果如图5所示,其中我们还包括使用传统ReLU DNN进行比较的情况。结果表明,我们的方法可以与新引入的INR体系结构相媲美,并且可以像其他方法一样快速实现高PSNR。

5.3 Super Resolution
我们在DIV2K图像数据集的图像上实现了4倍的超分辨率。在这种情况下,我们的BW-ReLU神经网络的表现略好于其他神经网络。所有的网络训练了2000次。图6显示了所有四种INR体系结构的结果。

5.4 Low Norm Solutions and Inverse Problems
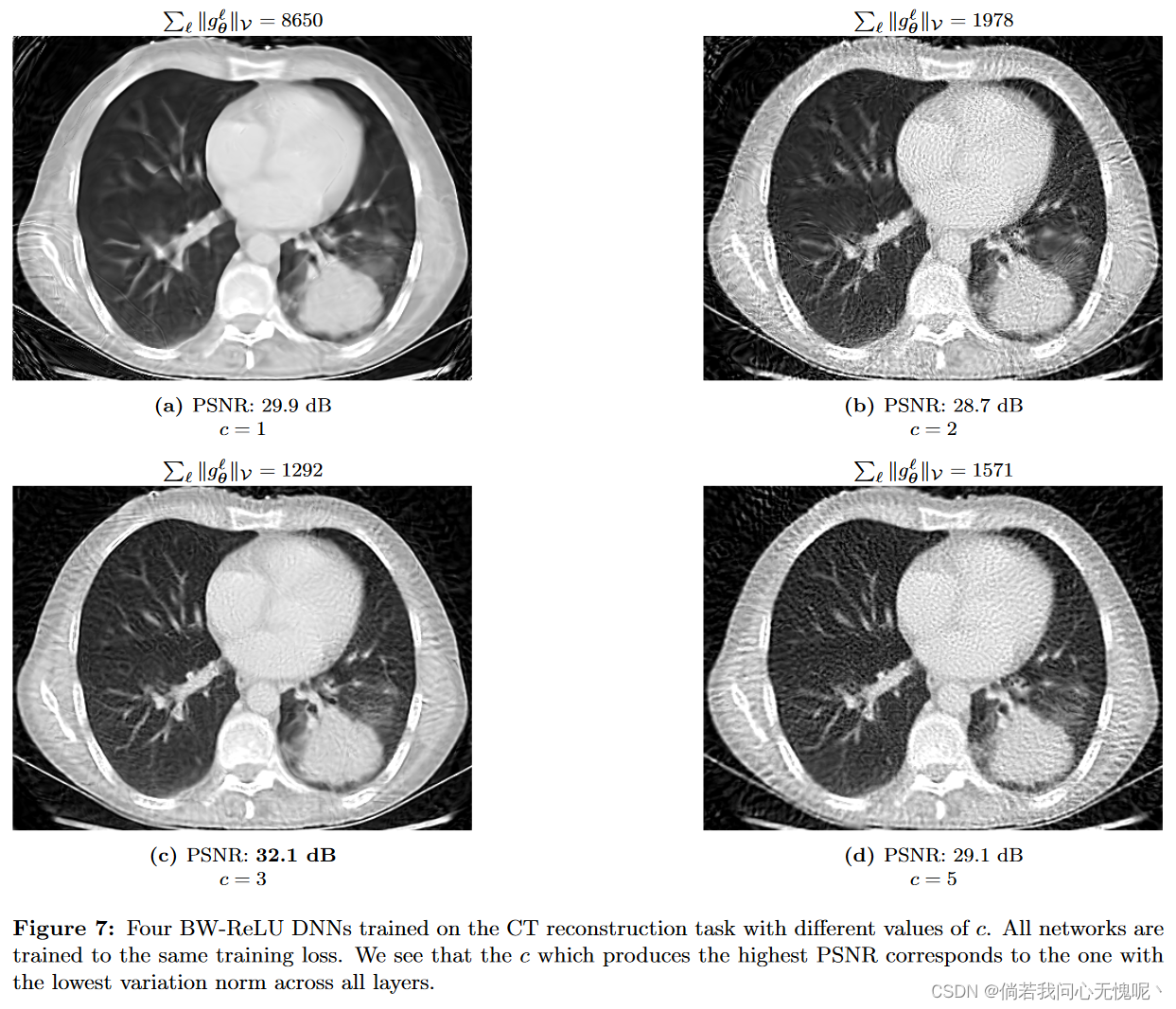
在我们的最后一个实验中,我们用三个不同的缩放参数训练了BW-ReLU神经网络来完成CT重建任务。在图7中,用于重建图像的三个BW-ReLU神经网络在CT测量数据上获得了相同的训练损失。然而,我们看到,在所有3层中变异范数最小的模型对应于最好的重建。这提出了一种在逆问题中选择尺度参数c的原则性方法。
6. Conclusion
在这项工作中,我们提出了一种简单的方法来利用ReLU DNN来完成INR任务。与以前的工作不同,我们只关注于在不牺牲ReLU的情况下通过绘制与b样条小波的连接来纠正优化问题的不良条件。然后,我们将我们的方法与与ReLU神经网络相关的函数空间联系起来,并展示了该框架如何有助于理解和量化我们的inr的规律性。这种联系建议采用一种更有原则的方法来调优inr。对于未来的工作,将这种技术应用于更多的INR任务将会很有趣。特别是神经辐射场和物理形式神经网络。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









