










项目地址
https://github.com/a252937166/seimicrawler.git
只需要以maven的形式导入demo这个项目就可以了。
数据库设计
resource\comic.sql,基本注释都有。
ORM框架
我使用的是mybatis,相关配置信息请在resource\config\seimi.properties修改。
代理浏览器
我使用的是semiagent,不了解的同学请参照 :
java爬虫系列(二)——爬取动态网页
实战目标
本次实战,我所做的演示就是输入一个漫画网的首页,爬取出它某一个版块的所有漫画内容。从漫画标题开始,到漫画的所有章节,再到章节下面每一篇图片。
以此为例,如果是一个防爬虫比较弱的网站,只用时间充裕,你就可以把它的所有信息全部爬完了。
代码解读
com.ouyang.crawlers.Manhua
start()
这是一个爬虫开始的方法,从startUrls()里读取出开始爬的网站。
我们首先看//所有热门下面的代码,//单章节和//单本漫画可以先注释掉。
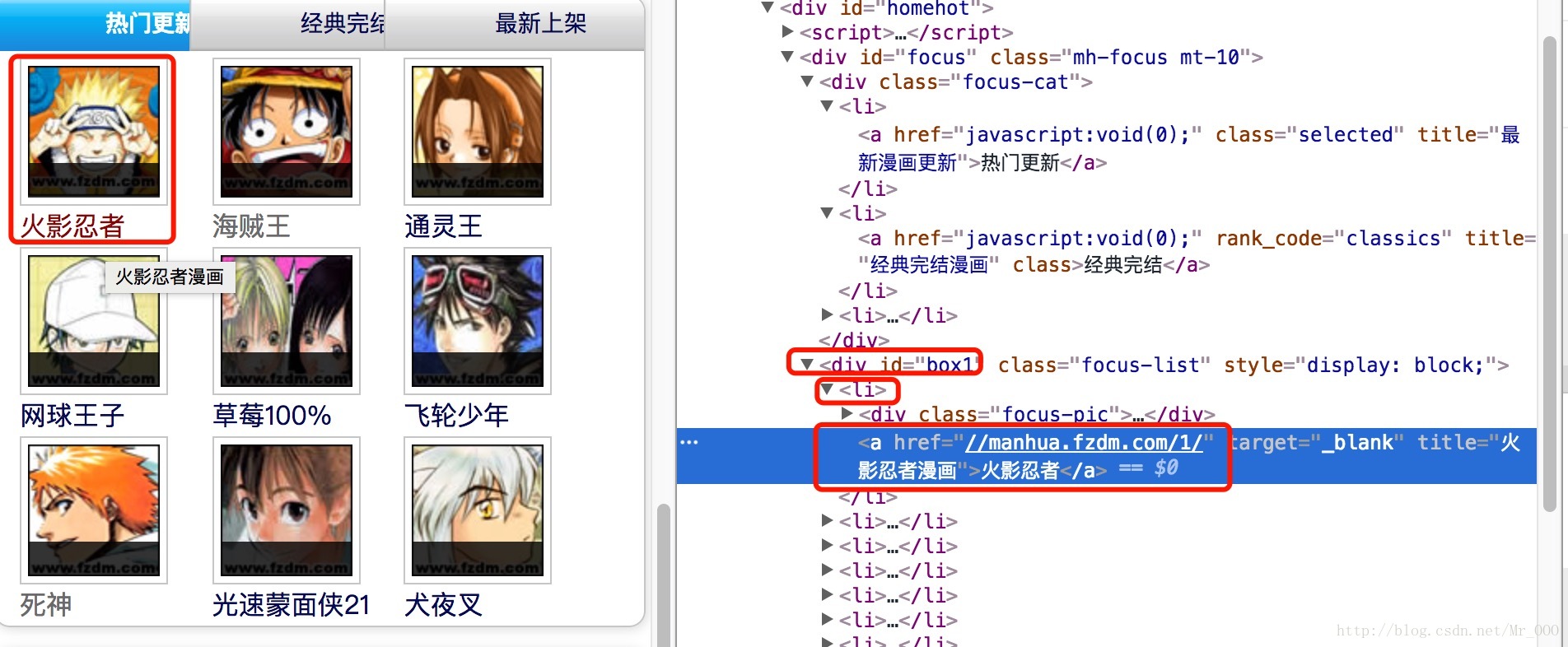
List<Object> urls = doc.sel("//div[@id='box1']/li/a");这段代码查出了所有热门漫画的连接。
for (Object s : urls)循环处理每本漫画。
push(Request.build(chapterUrl, "chapterBean").setParams(params));拼接出每本漫画章节的详情页chapterUrl,把返回信息交chapterBean()处理,需要传递的参数加入setParams(params),给这里不需要使用seimiagent。
chapterBean()
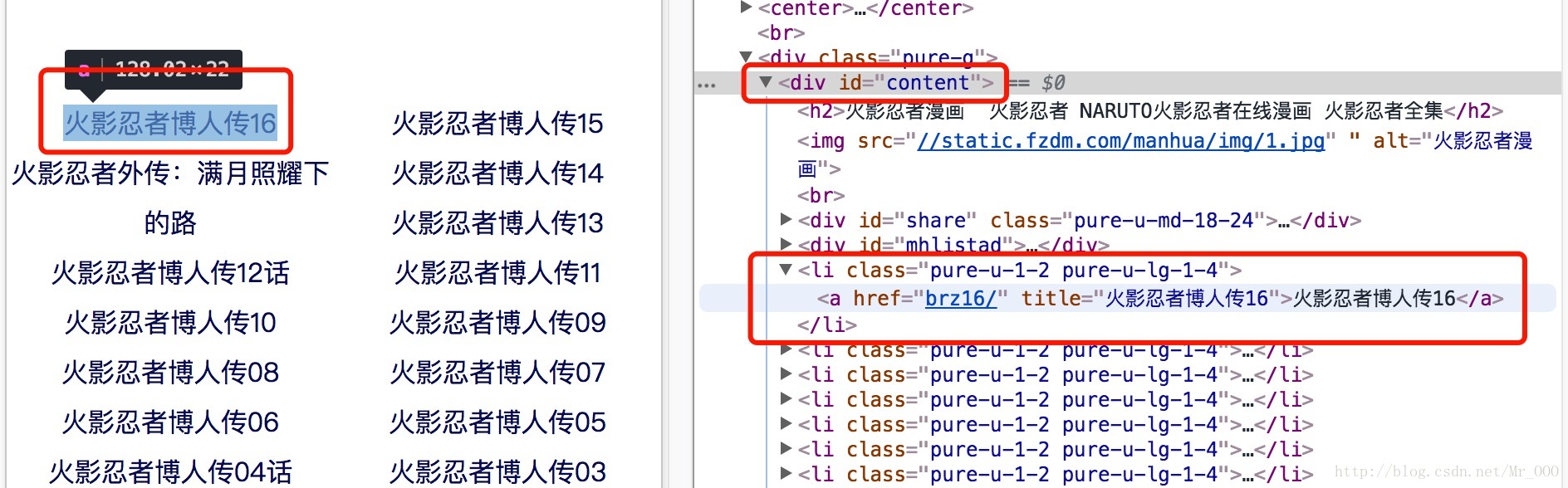
List<Object> urls = doc.sel("//div[@id='content']/li/a");
总体逻辑和start()差不多,找到每个章节详情的url,循环处理,把返回内容交个下个函数就行了。
comicName = HttpUtil.paramDecode(comicName);这里需要注意一下,如果参数是中文,需要解码。
push(Request.build(contentUrl, "contentBean").setMeta(param).useSeimiAgent().setSeimiAgentRenderTime(6000)
useSeimiAgent()使用浏览器代理解析动态网页,setSeimiAgentRenderTime(6000)设置解析时间6秒,setMeta(param)我这里把参数设置到meta里,因为我发现useSeimiAgent()设置param会出错,无法解析,具体原因不明,因为这个浏览器代理的源码我也没看。
contentBean()
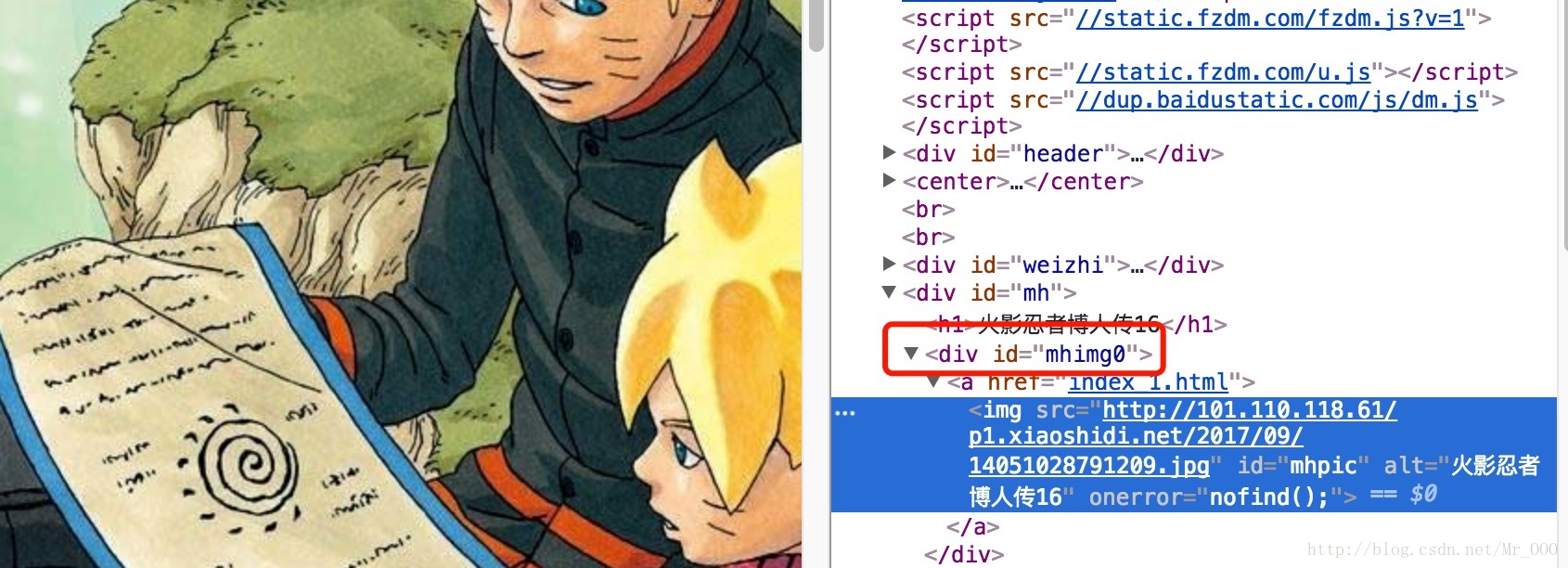
List<Object> imgUrlList = doc.sel("//img[@id='mhpic']/@src");漫画的每一张图片都在这里面处理。
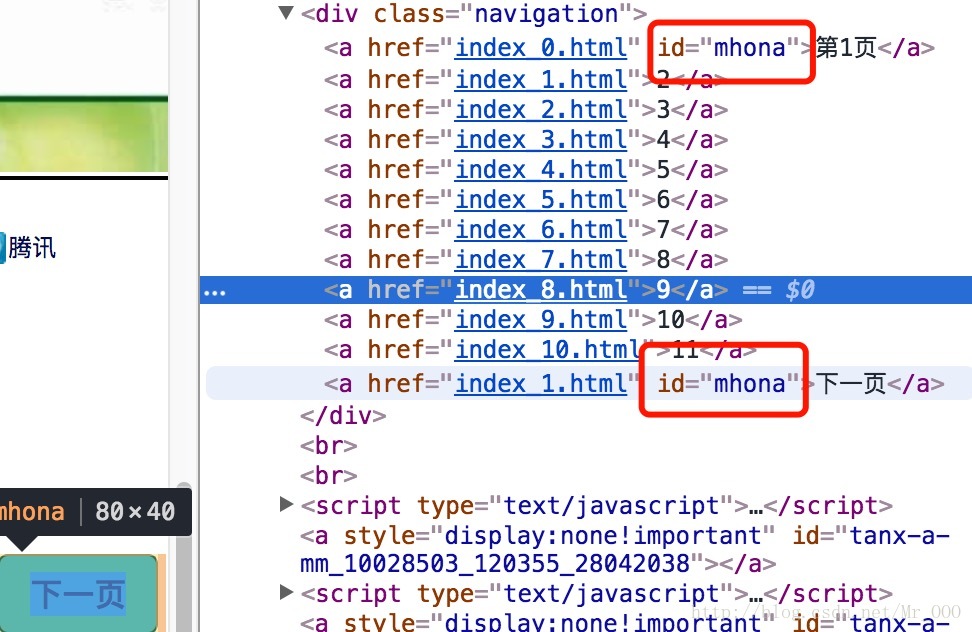
List<Object> elements = doc.sel("//a[@id='mhona']");这里有点奇怪,当前页和下一页的id都叫mhona,只能用文字匹配来分辨了。
if (mhonaMap.containsKey("下一页")) {
Map<String, String> param = new HashMap<>();
String currentUrl = response.getUrl();
if (currentUrl.endsWith("html")) {
currentUrl = currentUrl.substring(0, currentUrl.lastIndexOf("/"));
}
String contentUrl = currentUrl + "/" + mhonaMap.get("下一页");
param.put("chapterName", HttpUtil.paramEncode(chapterName));
param.put("comicName", HttpUtil.paramEncode(comicName));
push(Request.build(contentUrl, "contentBean")
.setMeta(param)
.useSeimiAgent()
.setSeimiAgentRenderTime(6000)
);
}这是处理分页的代码,如果有下一页,就把下一页的url同样用contentBean()处理就行了。
qiniuUtil.getPrivateImage(qiniuUtil.uploadImg(fileName, fileBytes))我这里是把图片重新上传到了我的七牛云上面,如果没有七牛云的同学,可以直接使用imgUrl,或者自己怎么处理都行。
if (CollectionUtils.isEmpty(imgUrlList)) {
ComicErrorContent comicErrorContent = new ComicErrorContent();
comicErrorContent.setChapterId(chapterId);
comicErrorContent.setCreateDate(new Date());
comicErrorContent.setImgUrl(response.getUrl());
comicErrorContentService.insert(comicErrorContent);
return;
}这是以防万一解析失败,把解析失败的内容单独存放一张表,以便之后处理。
实测
理论差不多就这样,现在演示一下实测情况。
启动seimiagnent

如上图,浏览器代理已经成功在8000端口启动。
启动项目
public class StartWorkers {
public static void main(String[] args){
Seimi s = new Seimi();
s.goRun("manhua");
}
}在main函数里面直接启动就行了。
给一些启动大概一分钟后截图,简单展示一下效果。
项目控制台:
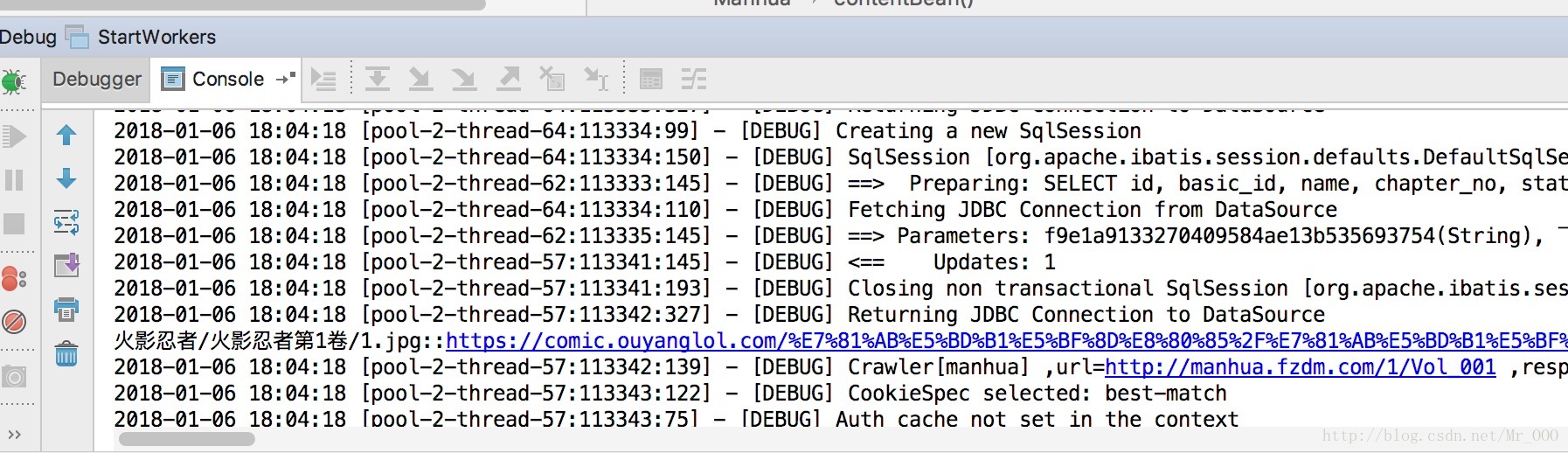
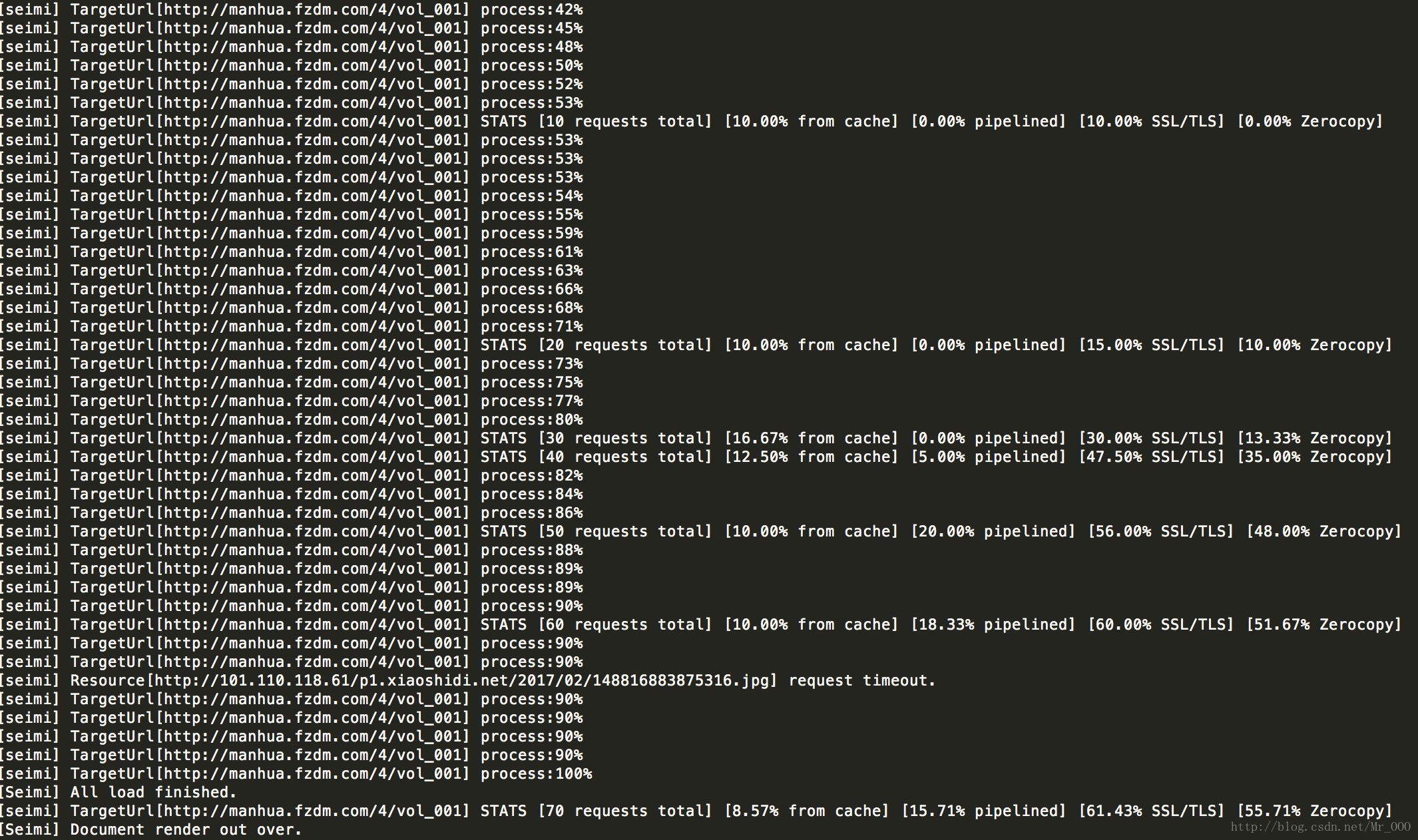
seimiagent:
数据库:
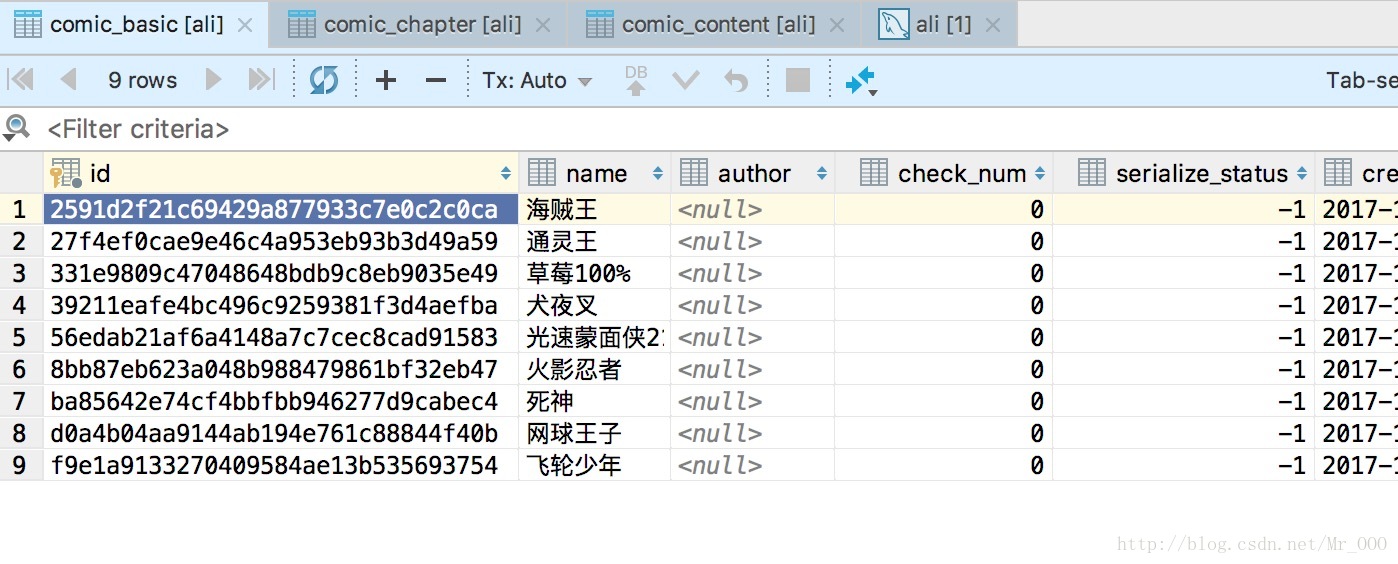
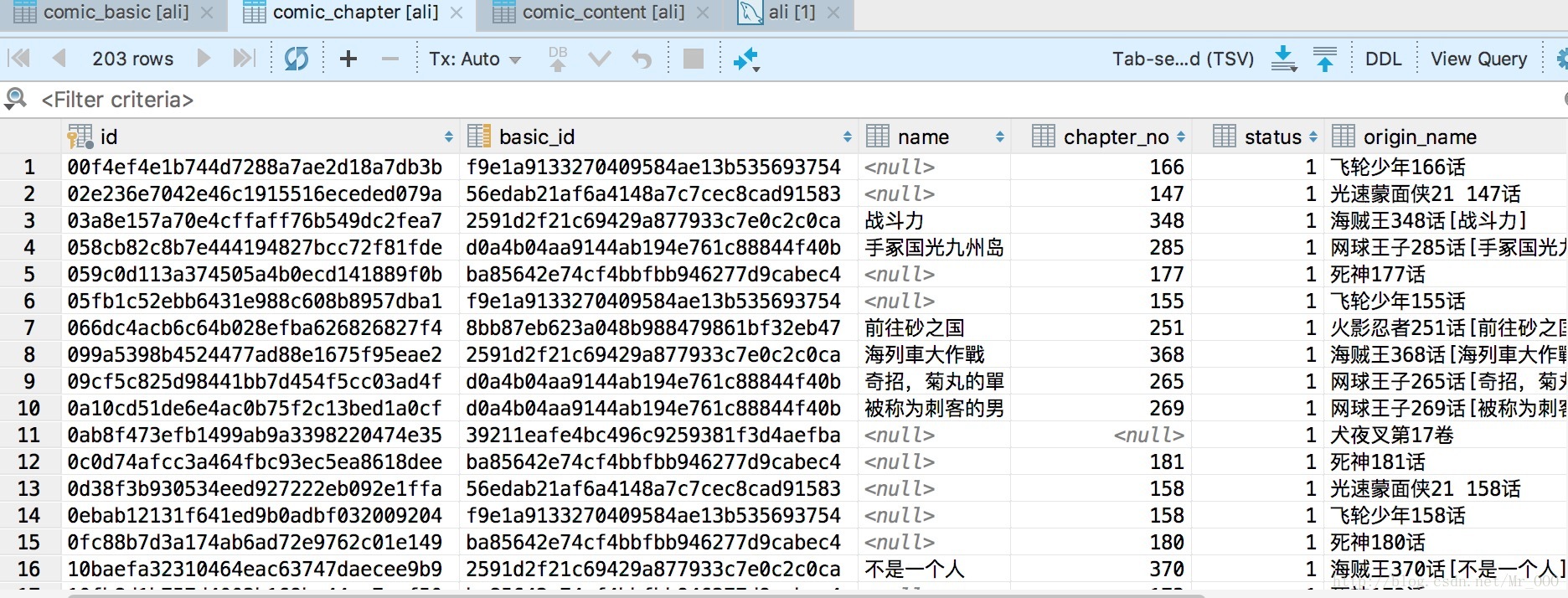
因为漫画图片在流程最后一步,而且涉及到上传七牛云,所以内容增加是最慢的。
综上,整个过程没有什么问题,如要测试分页,可以直接用//单章节下面的代码,这里就不多说了,代码都在GitHub上,有兴趣大家可以慢慢看。
同系列文章
java爬虫系列(一)——爬虫入门
java爬虫系列(二)——爬取动态网页
java爬虫系列(四)——动态网页爬虫升级版
java爬虫系列(五)——今日头条文章爬虫实战














 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









