




 本文详细探讨了Spring框架如何处理循环依赖问题,包括提前暴露机制、一级和二级缓存的使用,以及三级缓存在解决并发延迟加载时的作用。通过实例分析了构造函数和setter方式的循环依赖,并解释了Spring如何通过判断Bean创建状态来避免循环引用。此外,还介绍了AOP在循环依赖中的处理策略和缓存查找流程。
本文详细探讨了Spring框架如何处理循环依赖问题,包括提前暴露机制、一级和二级缓存的使用,以及三级缓存在解决并发延迟加载时的作用。通过实例分析了构造函数和setter方式的循环依赖,并解释了Spring如何通过判断Bean创建状态来避免循环引用。此外,还介绍了AOP在循环依赖中的处理策略和缓存查找流程。
文章目录
Spring解决循环依赖的方法
灵魂画手图解Spring循环依赖
Spring源码最难问题《当Spring AOP遇上循环依赖》
什么是循环依赖
public class A {
@Autowired
private B b;
// getter setter
}
public class B {
@Autowired
private A a;
// getter setter
}
Spring 生产单例 Bean, 一定需要一个缓存将生产好的完整的 Bean 缓存起来, 需要的时候直接根据 BeanName 来取到同一个 Bean, 这就是 Spring 的一级缓存(单例池), 存放的是完整的 Bean
生产 Bean 分为 实例化 - 填充属性 - 初始化 3个步骤, 在填充属性的时候, 会调用 getBean 来获取依赖的实例, 以完成自动注入, 在经过这三个步骤之后, 一个 Bean 才是一个完整的 Bean, 该有的东西都有了, 该走的流程也都走了
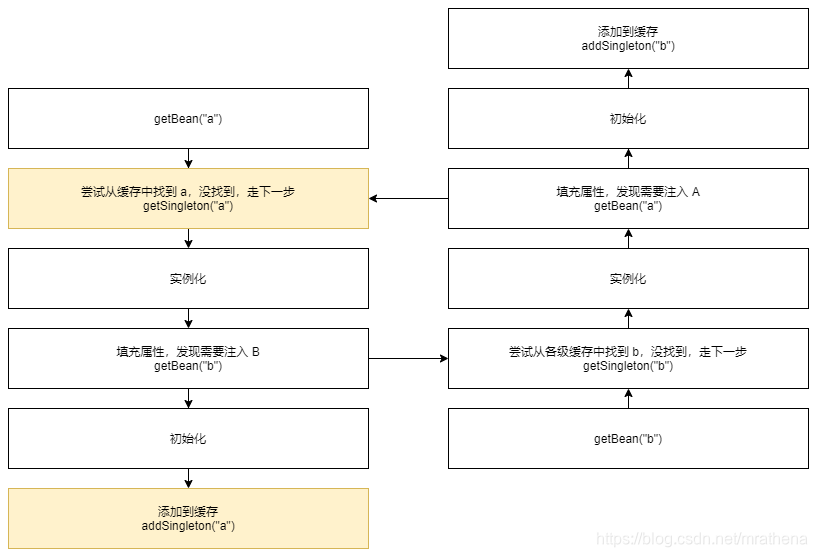
以上面的 AB 为例, 假如先生产的是 A, 调用 getBean(“a”). 在给 a 填充属性时发现 a 依赖 b, 调用 getBean(“b”). 在给 b 填充属性是又发现 b 依赖 a, 再调用 getBean(“a”), 然后无限循环 getBean(“a”) 和 getBean(“b”), 造成循环依赖问题
以下简单模拟循环依赖问题. 因为是在 Bean 初始化完成之后才添加缓存, 而循环依赖却发生在填充属性的过程中, 即还没有走到添加缓存, 循环依赖就已经发生了, 然后从缓存里面取 Bean 当然是找不到的, 陷入无限循环
循环依赖的类型
实例之间可以通过两种方式来引用对方, 一种是构造函数传参, 一种是 setter, 两者的区别是前者建立引用在实例化前, 后者建立引用在实例化之后. 循环依赖本质上也是引用其他实例, 所以有构造函数和 setter 两种类型
- 单例循环依赖
- setter: 依赖注入在实例化之后. 以 AB 为例, 先实例化 A, 发现需要注入 B, 就去实例化 B, 发现需要注入 A, 又来实例化 A, 陷入死循环
- 构造函数: 依赖注入在实例化之前. 在调用构造函数实例化一个对象时, 需要传入依赖的实例, 同样以 AB 为例, 要想实例化 A, 就得传入一个已经实例化的 B, 而要想实例化 B, 就得传入一个已经实例化的 A, 陷入死循环
- 多例循环依赖: 不像单例创建时有从缓存中获取的流程, 多例的创建都是直接创建新实例, 同样是有构造函数和 setter 两种
- setter: 待完善
- 构造函数: 待完善
循环依赖的解决方案 - 提前暴露机制
如何解决这种问题呢, 自然而然地想到了把添加到缓存的步骤往前挪到实例化之后填充属性之前, 将还不完整的 bean 提前暴露出来 (通过 getSingleton 可以拿到不完整的 Bean). 这样在填充属性时, 就可以从缓存中拿到循环依赖的实例了
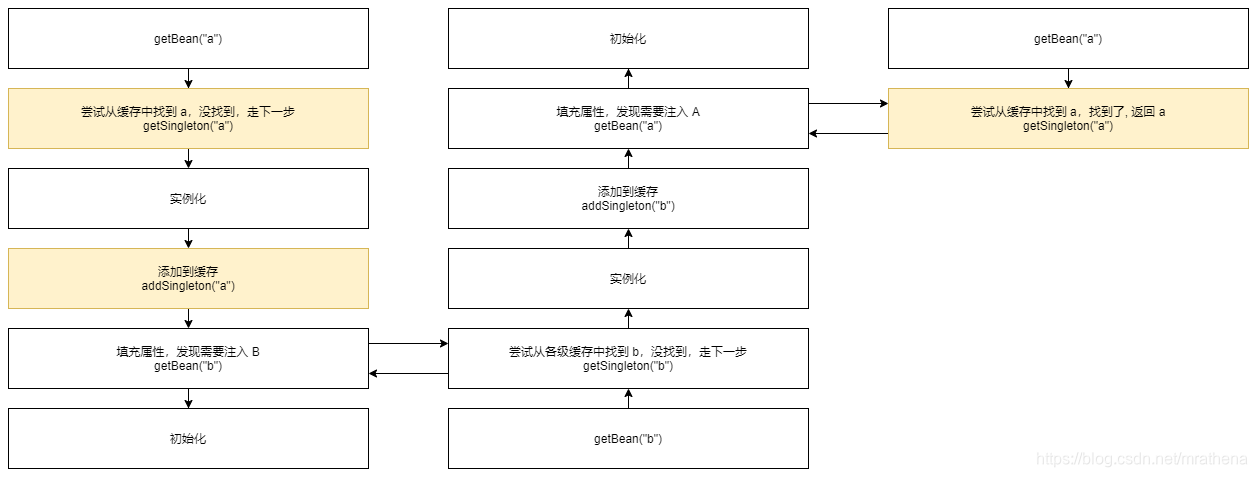
将添加到缓存这个步骤挪到实例化之后属性填充之前, 解决了循环依赖问题, 在第二次调用 getBean(“a”) 的时候从缓存中就可以找到 a 了, 然后成功注入 b 中, b 的创建过程得以继续, 待 b 完成创建后注入到 a 中, a 的创建过程得以继续, 最终成功创建 Bean a
如果 a 被配置了 AOP, 那么在实例化之后添加到缓存之前需要创建原始 a 的代理 a, 代理 a 替代原始 a 在填充属性的时候被其他 Bean 引用. 同时代理 a 也需要依赖原始 a, 以便原始 a 在走完填充属性和初始化的流程变得完整后, 代理 a 还能拿到原始 a 的所有数据
只使用一个缓存是否足够解决循环依赖问题? 能解决 Spring 启动时的循环依赖问题, 但是在启动后并发获取延迟 Bean 时还是存在问题的, 虽然 Spring 启动过程是单线程的, 但是 Spring 中有延迟加载的概念, 当两个互相依赖的 Bean 被配置成延迟加载时, Spring 启动流程是不会主动生产这两个 Bean 的, 当 Spring 启动后, 我们可以人为地并发获取并调用延迟加载 Bean 的方法时, 就有可能出现问题, 如: 线程 1 实例化了 Bean 并添加到缓存(还没有填充属性和初始化), 这时线程 2 进来了, 直接从缓存里读取了不完整的 Bean, 然后就去调用 Bean 的方法, 因为不完整, 所以可能会出问题
循环依赖解决方案的优化 - 完整 Bean 和不完整 Bean 分开缓存
现在的情况是, 循环依赖虽然解决了, 但是没有循环依赖问题的完整的 Bean 和有循环依赖问题的不完整的 Bean 完全混在了同一个缓存中, 谁都有可能从缓存中拿到不完整的 Bean, 导致 Spring 启动后, 我们并发获取延迟 Bean 并调用其方法的时候可能会出问题
该怎么办呢? 只需要确保一个问题, 就是 除了加载容器过程中循环依赖情况下互相注入属性时可以从缓存中获取到提前暴露的不完整的 Bean, 其他任何时候从缓存中取 Bean, 要么没有, 要么拿到经过了实例化, 填充属性, 初始化全套流程的完整的 Bean. 这样就可以保证调用 Bean 方法的安全性
看样子是需要把完整的 Bean 和提前暴露的不完整的 Bean 分开缓存了, 我们重新定义这个两个缓存为一级缓存和二级缓存
- 一级缓存: 经过了实例化, 填充属性, 初始化等创建 Bean 整套流程的完整的 Bean
- 二级缓存: 存在循环依赖问题的需要提前暴露的不完整的 Bean, 在实例化之后, 判断是循环依赖, 就添加到二级缓存中
这样, 内部解决循环依赖时从二级缓存中找, 其他时候都从一级缓存中找, 即可实现目的
那么什么时候可以把 Bean 添加到缓存中呢? 一级缓存的添加毫无疑问是在实例化, 填充属性, 初始化之后, 二级缓存则在实例化之后且存在循环依赖时添加. 很清晰, 但是有问题
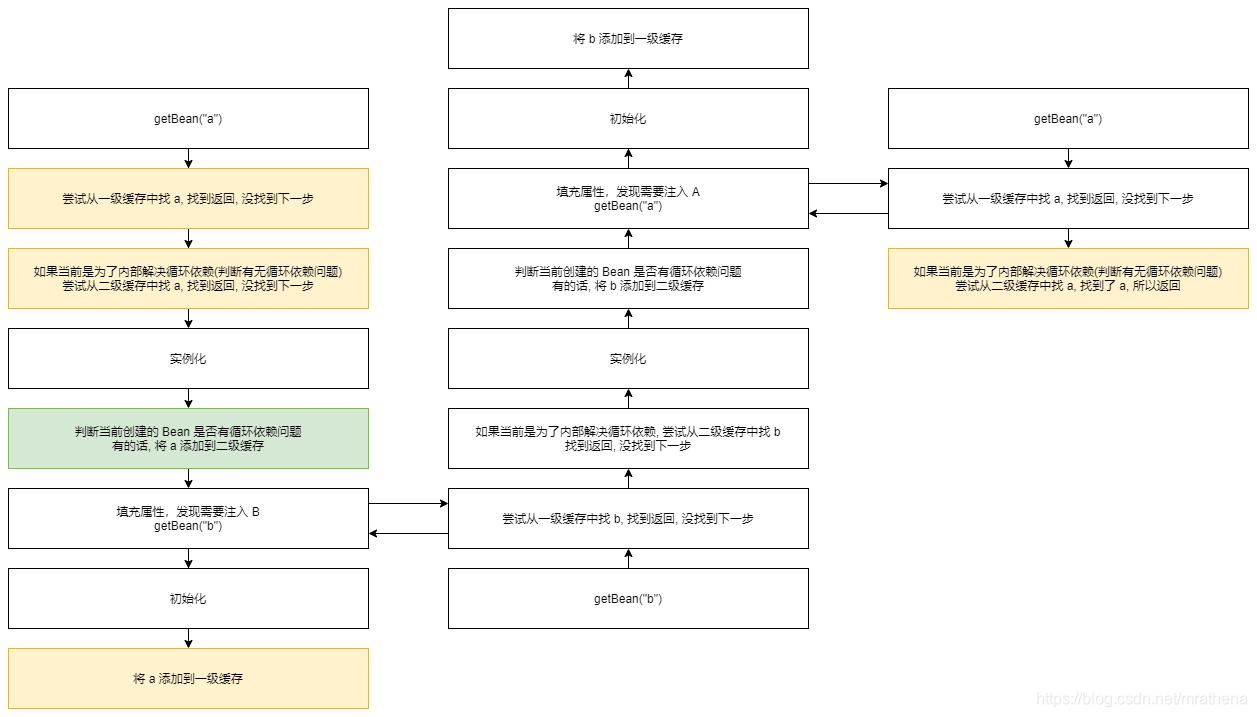
如何在 Bean 实例化之后判断当前创建的 Bean 是否有循环依赖问题? 看下面例子来理解判断的时机(绿色), 我们希望达到下面流程的效果
循环依赖解决方案的优化 - 判断当前创建中的 Bean 是否存在循环依赖问题
如何在 Bean 实例化之后判断当前创建的 Bean 是否有循环依赖问题? 以便于我们依此来判断是否需要将 Bean 添加到二级缓存中
我们希望在步骤一二三都能判断当前 a 是否存在循环依赖问题. 如果在步骤一判断 a 有循环依赖问题, 因为是首次进来, 所以二级缓存中没有数据. 如果在步骤二判断 a 有循环依赖问题, 所以将 a 存入了二级缓存. 如果在步骤三判断 a 有循环依赖问题, 因为步骤二已经添加过二级缓存了, 所以步骤三能拿到提前暴露的不完整的 a, 并完成 b 的属性注入, 进而完成 a 的属性注入, 进而完成 a 的生产
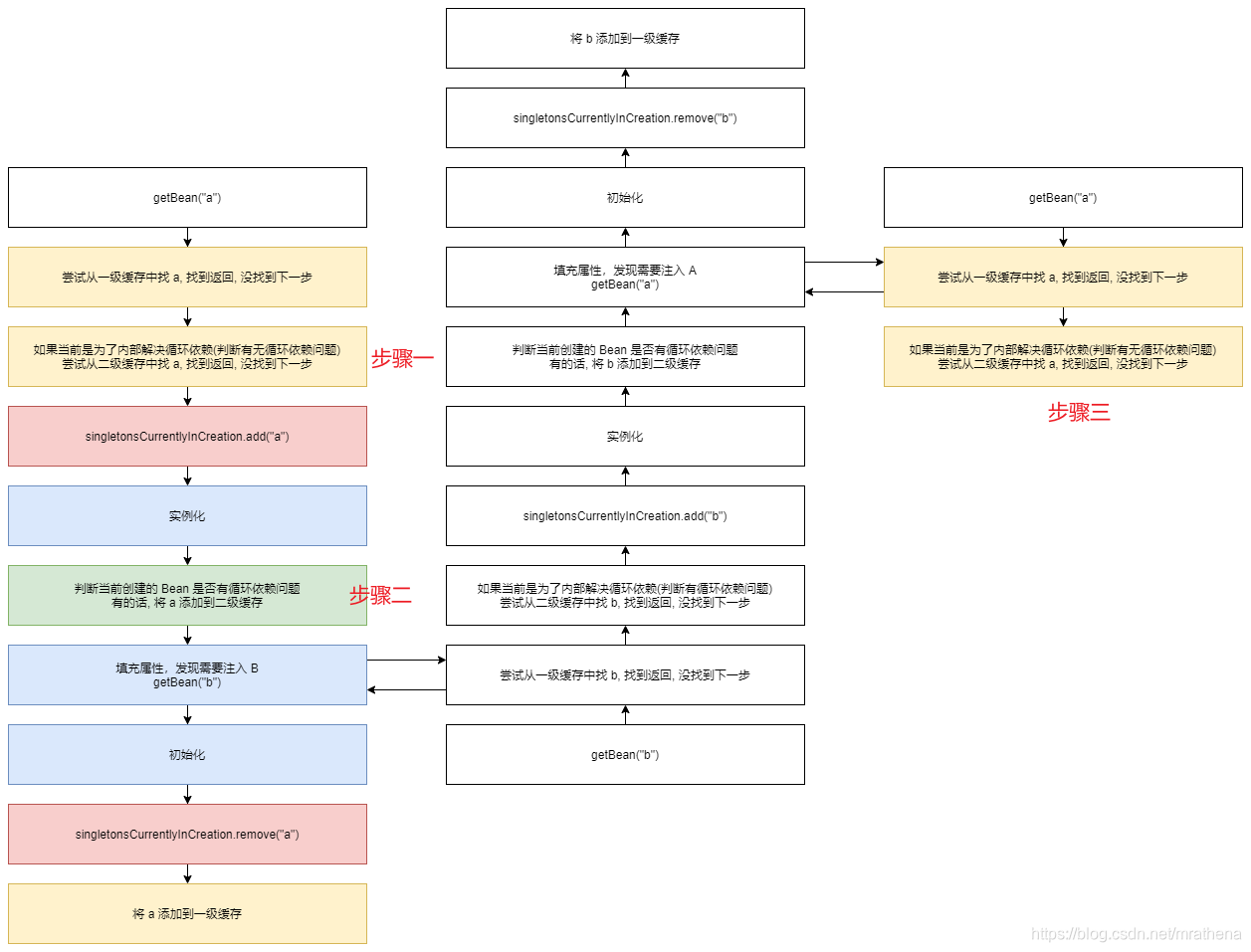
Spring 的解决方案是这样的, 定义一个集合叫做 singletonsCurrentlyInCreation, 存储正在创建过程中的 Bean 的名字, Bean 在实例化之前添加到该集合中, 初始化之后从该集合中移除, 通过调用 isSingletonCurrentlyInCreation 来判断某个 BeanName 是否在创建流程中
我们希望在步骤一二三都能准确判断是否有循环依赖问题, 但是依靠是否在创建中这个标记能做到吗? 答案是不能, 只有在步骤三中才能准确判断是否有循环依赖问题. 步骤三本质上是第二次走步骤一, 第一次的时候已经将 a 标记为正在创建了, 现在又跑过来要创建 a, 由此断定第二次创建 a 发生了循环依赖, 即 a 存在循环依赖问题
所以最终结论是, 在 Spring 的设计下, 只有在第二次调用某个 Bean 的 getBean 方法的添加标记前才能判断该 Bean 是否有循环依赖问题, 比如查找二级缓存的时候. 在第一次 getBean 的过程中无法判断是否有循环依赖问题, 从而无法决定是否需要将创建中的 Bean 添加到二级缓存
循环依赖解决方案的优化 - 调整添加二级缓存的时机到获取二级缓存前
将 a 添加到二级缓存放在实例化之后是最容易理解的, 但实际上, 从 a 实例化到为了解决 b 对 a 的依赖从二级缓存中获取到 a 实例, 这是一个很长的步骤, 只要是在这个阶段内将 a 实例添加到二级缓存中, 就能保证 b 可以正确依赖到 a, 完成属性填充
再加上我们可以在步骤三的地方正确判断是否需还依赖, 那我们是否可以把 添加实例到二级缓存 这个操作挪一下位置, 从实例化后挪到查找二级缓存前? 当然是可以的, JDK8 的函数式接口就提供了封装一段代码在合适时机才触发执行的操作
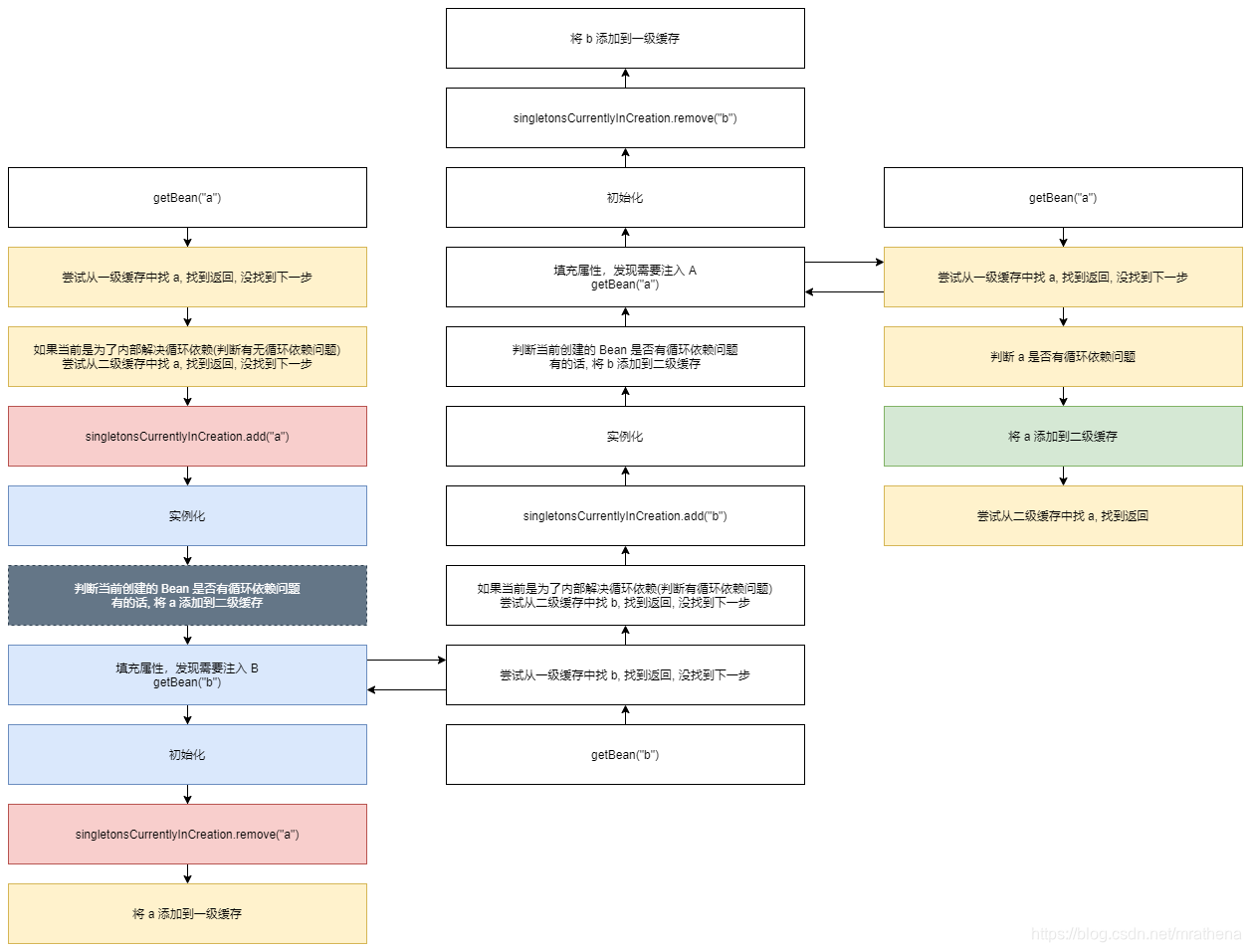
将步骤三的判断是否有循环依赖问题和从二级缓存中查找拆分开, 然后把步骤二挪到步骤三的两步中间, 即可实现只有存在循环依赖问题的 提前暴露的不完整的 Bean 才会被添加到二级缓存中这个目的
这里有个问题, 函数式接口是 JDK8 提供的, 那么 JDK7 及以前, Spring 是如何处理循环依赖的?
循环依赖解决方案的优化 - 后置添加二级缓存时机的实现方案
第一次调用 getBean(“a”) 创建了 a 的实例对象, 第二次调用 getBean(“a”) 将之前创建的 a 的实例对象添加到二级缓存, 这个该如何实现?
我们已经有了思路, 使用函数式接口传递一段代码, 在合适的时机触发执行. Spring 采用如下方式实现这一目的
// 定义一个集合用于存储 BeanName 和 要在指定时机执行的代码 的容器, 也就是三级缓存
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
// 在实例化后, 将 Bean 封装成为一段未执行的代码, 将在合适时机执行该方法, 并返回该 Bean
protected Object getEarlyBeanReference(Object bean) {
return bean;
}
// 在实例化后, 将已经封装好的未执行代码添加到三级缓存中
this.singletonFactories.put(beanName, () -> getEarlyBeanReference(bean));
// 在第二次 getBean 的时候(存在循环依赖问题), 触发封装的代码, 获取到之前实例化的 a, 并将其添加到二级缓存中
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 触发调用封装的代码的 getEarlyBeanReference 方法拿到 a
singletonObject = singletonFactory.getObject();
// 将 a 添加到二级缓存中
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
至此, Spring 解决循环依赖的方式已经得到了大体上的答案(还有一些 AOP 相关的情况需要补充)
循环依赖的解决方案 - Spring 三级缓存
Spring 使用一级缓存存放完整的 Bean (Spring 称之为 Full Singleton), 使用二级缓存存放存在循环依赖问题的需要提前暴露的不完整的 Bean. 如果不存在循环依赖, 在 Bean 经过 实例化, 填充属性, 初始化 流程后, 添加到一级缓存中即可. 只有循环依赖才需要使用二级缓存来提前暴露 Bean 的引用
Spring 解决循环依赖使用了三个缓存
一级缓存存放 完整的 Bean, 在一个 Bean 经过完整的生产流程(实例化, 填充属性, 初始化)后, 才会添加到这个缓存中
二级缓存存放 存在循环依赖问题的需要提前暴露的不完整的 Bean, 在实例化后, 判断得出某个 Bean 存在循环依赖问题, 则会把该 Bean 添加到二级缓存中. 只不过实现方式有点绕, 但最终就是这么个效果
三级缓存为二级缓存服务, 依靠三级缓存实现了延迟添加 Bean 到二级缓存的时机的目的, 因为实例化后不能立马判断 Bean 是否有循环依赖问题, 将其挪到能正确判断的地方, 即循环依赖中第二次调用同一个 BeanName 的 getBean 方法时判断缓存的位置
三级缓存是为了 AOP 服务?
我不这么认为, 三级缓存目的就是延迟添加 Bean 到二级缓存的时机, 虽然在 getEarlyBeanReference 方法中确实有做判断并做 AOP 的代理的流程, 但这只是顺便的
在实例化后添加三级缓存前, 即可判断 Bean 是否需要做代理, 需要的话直接由原始 Bean 生成代理 Bean, 把代理 Bean 封装成为一段代码并添加到三级缓存中, 这样也是可以的, 所以三级缓存的主要目的是延迟添加 Bean 到二级缓存的时机
循环依赖加 AOP 怎么理解?
Spring 期望 Bean 在完成了完整的创建流程后再做 AOP 代理, 所以在 Bean 初始化后有一个处理代理的入口. 但是这还不够, 因为用来处理循环依赖的二级缓存中的 Bean 如果被配置了 AOP, 则必须提前做代理, 不然注入到循环依赖中的 Bean 就不是代理 Bean 而是原始 Bean, 不符合要求. 所以如果一个 Bean 有循环依赖问题, 且这个 Bean 被配置了 AOP, 则该 Bean 需要在添加到二级缓存前做好早期代理, 在初始化后判断如果已经是代理对象, 则无需再次走后期代理
- 循环依赖添加到二级缓存前需要做早期代理
- 循环依赖在完成 Bean 生产后做后期代理
查找缓存的方式
public Object getSingleton(String beanName) {
return getSingleton(beanName, true);
}
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
// 尝试从一级缓存中找
Object singletonObject = this.singletonObjects.get(beanName);
// 如果一级缓存中不存在, 且当前 Bean 有循环依赖
// 在没有标记当前 Bean 正在创建中前判断当前 Bean 正在创建中了, 说明当前 Bean 一定处在第一次 getBean 的创建过程还没结束又触发了第二次 getBean 的情形中
// 即存在循环依赖问题, 在有循环依赖问题的情况下才会去查二三级缓存, 没有循环依赖问题的话, 只查一级缓存
// AB循环依赖, 先执行 getBean("a"), 发现需要 getBean("b"), 又发现需要 getBean("a"), 后面的 a 发现前面的 a 在创建中了
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
// 尝试从二级缓存中找
singletonObject = this.earlySingletonObjects.get(beanName);
// 如果二级缓存中不存在且允许提前引用(不完善的 Bean 可以被其他 Bean 注入, 传入的允许)
if (singletonObject == null && allowEarlyReference) {
// 对一级缓存加锁 (类似单例模式-双重检查锁实现方式?)
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
// 对一级缓存加锁后, 再次尝试从一级缓存中找
singletonObject = this.singletonObjects.get(beanName);
// 一级缓存中还是没有
if (singletonObject == null) {
// 再次尝试从二级缓存中找
singletonObject = this.earlySingletonObjects.get(beanName);
// 二级缓存中还是没有
if (singletonObject == null) {
// 首次尝试从三级缓存中找
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
// 如果从三级缓存中找到了
if (singletonFactory != null) {
// 如果允许循环引用, 在 Bean 实例化后, 就会走添加到三级缓存的 addSingletonFactory 方法(必走)
// 三级缓存中存的不是 Bean 本身, 而是对这个 Bean 的一套操作(通过函数式接口实现通过参数传入一段代码)
// 在合适时机(就是创建 Bean 查找缓存时)通过调用该函数式接口的 getObject 方法来触发这套代码的执行
// 这套代码是什么内容呢, 就是给 Bean 走一波 SmartInstantiationAwareBeanPostProcessor 这个后置处理器定义的 getEarlyBeanReference 操作
// 普通的 Bean 走这个方法其实都是没有任何对 Bean 的特殊修饰, 只有在 AOP 的情况下, 才会拿到 AbstractAutoProxyCreator 实例, 并会给 Bean 创建代理并返回代理对象
// 这是 Spring AOP 的入口点之一, 在 Bean 实例化之后, 立刻创建代理, 引用原始 Bean, 当原始 Bean 完善后, 代理也可拿到原始 Bean 注入的参数
// org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean
// org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.getEarlyBeanReference
singletonObject = singletonFactory.getObject();
// 保存到二级缓存中
this.earlySingletonObjects.put(beanName, singletonObject);
// 已经保存到二级缓存中了, 三级缓存中的就没用了, 可以删掉了
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









