








概述
毫无疑问,目前最受关注且不断发展的最重要的主题之一是使用人工智能生成图像、视频和文本。大型语言模型 (LLM) 已展示出其在文本生成方面的卓越能力。它们在文本生成方面的许多问题已得到解决。然而,LLM 面临的一个主要挑战是它们有时会产生幻觉反应。
最近推出的新模型(如新发布的 GPT-40)尤其令人惊叹。OpenAI 无疑正在改变游戏规则。此外,谷歌强大的模型 Gemini 1.5 Pro 极大地改变了我们的看法。因此,我们可以看到模型正在改进。轮子已经发明,现在必须加以改进。
最初,LLM 是为翻译任务而开发的。现在,我们看到它们执行各种任务,趋势是朝着多模态模型发展。Transformers 强大而重要的架构使这一切成为可能。
Transformers 可以执行的另一项任务是图像生成,如 DALL-E、Midjourney 或 Ideogram 等产品中所示。这些模型接受文本提示并生成图像。最近发布的 LlaMa 3 模型在编写文本提示时生成图像,并在我们修改文本时更改图像。
但更令人惊讶的是从文本生成视频。几个月前,OpenAI 推出了一款名为Sora的产品。它令人印象深刻,令人惊叹,能够生成高质量、高度逼真的图像,甚至可以创造其他世界。当我看到它时,我首先想到的是电影《黑客帝国》。
在本文中,我们将从头开始研究从文本生成图像和视频的想法,并追溯其演变过程。我们的目标是首先了解图像生成,然后了解视频生成,并研究用于这些任务的架构。
历史
第一批电影于 19 世纪 80 年代制作,令观众惊叹不已,为今天我们所知的强大的电影业奠定了基础。在电影制作中使用人工智能 (AI) 的概念出现于 20 世纪初,随着计算机的兴起而逐渐流行。1960 年,约翰·惠特尼 (John Whitney) 创立了 Motion Graphics Incorporated,并使用他的模拟计算机制作电影片段、电视剧名和广告,开创了计算机动画的先河。IBM于1966 年授予他第一位驻场艺术家职位,以表彰他的贡献。多年来,各种关于计算机生成的电影和动画的文章相继发表,为今天我们所知的 AI 在电影制作和表演艺术中的应用铺平了道路。21 世纪和21世纪的进步,包括深度学习算法和生成对抗网络 (GAN),进一步推动了 AI 在数字内容创作和编辑中的应用。下一节将探讨使用 Transformer 架构生成图像的可行性。
跨平台对抗网络TransGANs
生成对抗网络 (GAN) 由Ian Goodfellow及其同事于2014 年 ( Transformers 诞生之前) 提出,用于图像处理和其他任务。生成对抗网络
生成对抗网络 (GAN) 的概念早于 Transformer,涉及两个参与零和博弈的深度神经网络。第一个网络是生成器,它创建合成样本;第二个网络是鉴别器,它负责区分真实样本和合成样本。生成器的目标是生成可以欺骗鉴别器的样本,使其无法区分真实样本和合成样本。
Transformer 与 GAN 的结合(称为 TransGAN)表明,Transformer 既可以充当 GAN 中的生成器,也可以充当鉴别器。这些模型利用 Transformer 的优势来捕捉数据的复杂特征。这种方法在2021 年由Yifan Jiang、Shiyu Chang和Zhangyang Wang 发表的同名论文中进行了详细介绍。TransGAN:两个纯 Transformer 可以组成一个强大的 GAN,而且可以扩展
TransGAN 是 Transformer 生成对抗网络的缩写。该模型是一种 GAN,其生成器和鉴别器均采用 Transformer 架构。与传统 GAN 不同,TransGAN 不使用 CNN 作为生成器或鉴别器,而是同时采用 Transformer 结构。
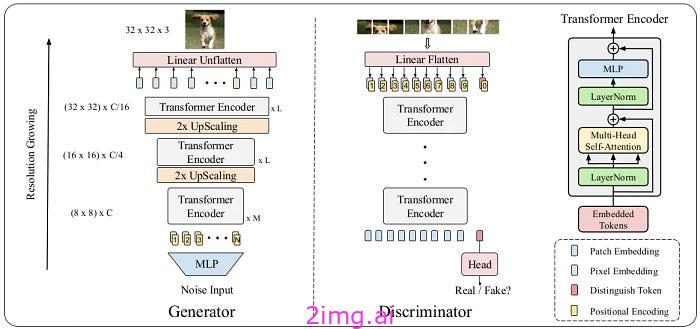
这幅图清晰地展示了 TransGAN 的架构以及生成器和鉴别器的结构。输入图像是一张 3×3 的彩色照片。来源
生成器Generator
在 TransGAN 中,生成器使用 Transformer 架构来生成数据序列。生成器从随机噪声输入开始,该输入通常是具有高斯(正态)分布的随机值的向量。此噪声输入被转换为更高维的特征空间。此阶段涉及多个前馈层和 MHA 层。
基于 Transformer 的生成器逐步生成数据序列。在每个步骤中,生成器生成一部分数据(例如,图像的一个像素),然后将此输出用作下一步的输入。注意力机制可帮助生成器对数据中存在的长期依赖关系和复杂性进行建模。
在生成完整的数据序列后,这些序列被转换成完整的样本(例如,完整的图像)。这种转换包括重建复杂的特征和最终的细节。
鉴别器Discriminator
TransGAN 中的 Discriminator 负责判断 Generator 生成的样本是真是假,它采用 Transformer 架构来分析生成的数据序列。
最初,鉴别器接收可能是真实图像或虚假图像的样本。这些样本作为图像块序列输入到模型中。每个图像块代表图像的一小部分,例如16×16像素块。每个图像块首先转换为矢量表示。此矢量表示通常通过嵌入层获得,该嵌入层将每个图像块转换为指定维度的矢量。然后将这些矢量与位置嵌入相结合,以保留每个图像块的空间信息。
然后将编码的块序列输入到多个多头注意力 (MHA) 层。这些层允许鉴别器对图像不同块之间的长期依赖关系和关系进行建模。MHA 帮助模型同时关注图像的不同特征。
注意力层的输出被输入到多个前馈层。这些层提取并处理组合特征,从而产生更复杂、更丰富的图像表示。然后,前馈层的最终输出被输入到聚合层。该层将所有提取的特征组合成一个综合表示。然后,这个综合表示连接到最后一层,例如密集层,最终决定图像是真是假。
在 GAN 中使用 T
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











