






一 前言
对于第一次BPF的介绍,只是简单介绍了BPF,写了一个没啥用的例子,如何利用BCC写一个有点用的程序以及BCC中有哪些牛逼的工具,是本篇需要介绍的。
二 BPF程序开发一般流程
再来回忆下,BPF开发程序,加载和运行过程,如下图, 从用户程序角度看分为三个部分:
BPF代码,即内核事件发生时候调用的代码,下图中的bpf_prog.c,通过LLVM和clang编译器,将代码转成BPF字节码。
加载BPF代码的用户代码,即负责进行系统调用将编写的BPF代码编译后的字节码,加载到内核中探针上(kprobe)。
用户程序通过读取映射表内容,来获取BPF代码的输出,即bpf_prog.c这个模块输出。内核的角度:
字节码被传递到内核后,内核通过校验器进行校验;
校验通过后,事件被启动,BPF程序被挂载到事件上。
将数据输出到映射表中。
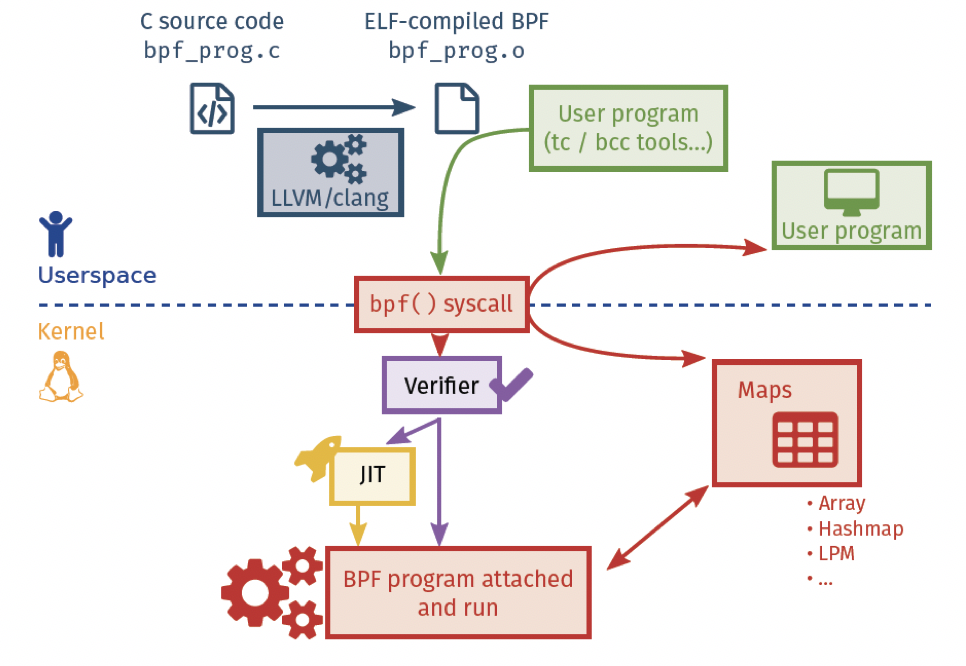
需要说明的是,内核会判断bpf_jit_enabled是否开启,这个可以在内核源码编译的时候开启,开启后,即时编译器(JIT)会将eBPF字节码编译成本地机器指令,执行起来效率更高。
我们知道BPF程序和事件关联的,这个里面的事件不止内核态的事件,还包括用户态的事件,最重要的是三类:
动态插桩,内核态(kprobes的BPF支持 )
动态插桩,用户态(uprobes的BPF支持)
静态跟踪,内核态(tracepoint)
时间采样事件(BPF,使用perf_event_open()) 还有很多,都不列出来了,根据挂载事件的不同,BPF的程序类型不同,每种eBPF程序挂载到不同的内核函数,内核跟踪点,用户态插桩点,性能事件上,当这些内核函数,内核跟踪点,用户态插桩点,性能事件被调用的时候,挂载在上面的BPF程序自动执行。
2.1 利用BCC编写C代码
2.1.1 BPF内核运行的代码
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
#include <bpf/bpf_tracing.h>
#include <bpf/bpf_core_read.h>
#include <linux/ptrace.h>
// 内核的动态插桩位置:do_sys_openat2 即打开文件函数
SEC("kprobe/do_sys_openat2")
int hello(struct pt_regs *ctx) {
const int dirfd = PT_REGS_PARM1(ctx);
const char *pathname = (char *)PT_REGS_PARM2(ctx);
char fmt[] = "@dirfd='%d' @pathname='%s'";
char msg[256];
bpf_probe_read_user_str(msg, sizeof(msg), pathname);
bpf_trace_printk(fmt, sizeof(fmt), dirfd, msg);
return 0;
}
char _license[] SEC("license") = "GPL";说明:
BPF的代码在内核的动态插桩位置为:openat2,此函数在glibc2.32时候,所有的打开文件的操作都是openat2,具体的参数声明如下:
int openat2(int dirfd, const char *pathname,
const struct open_how *how, size_t size);
详情参考:[open(2) - Linux manual page (man7.org)](https://man7.org/linux/man-pages/man2/openat.2.html)获取第一个参数和第二个参数值 PT_REGS_PARM1 和PT_REGS_PARM2 是获取openat2的前两个参数
bpf_probe_read_user_str(msg, sizeof(msg), pathname);bpf的辅助函数,从用户空间读取字符串,这里面不复制下面也可以打印,只是通过这个调用后,就可以把用户空间的路径名复制到eBPF程序中。
bpf_trace_printk 即向调试系统文件写入调试信息,输出位置是: /sys/kernel/debug/tracing/trace_pipe 不是标准输出。
SEC("license") 宏,定义在头文件bpf/bpf_helpers.h 为:attribute((section(NAME), used)) 即把变量,函数,放在ELF文件中名为license的段中,_license 定义了eBPF程序的license类型,eBPF程序会校验此license是否为GPL兼容的。
2.1.1 编译BPF程序
我们用安装的clang编译器,结合llvm工具将c写的BPF程序编译成bpf字节码,指令如下:
clang -O2 -target bpf -c open_file.c -o open_file.o如果采用两步编译就是:
# 前端编译生成LLVM IR文件
clang -O2 -Wall -emit-llvm -S open_file.c
# 使用LLVM 后端生成BPF字节码
llc open_file.ll -march=bpf -filetype=obj -o open_file.o过程:
clang 把 eBPF 程序翻译为中间语言(IR)是 LLVM 的 object (参数 -c -emit-llvm),再通过 llc 编译、链接成 target 为 bpf 的 ELF 程序(参数 -march=bpf -filetype=obj)
bpf 表示目标为bpf字节码格式,可以通过以下命令看下详细的bpf字节码:
[root@localhost hello-openat2]# llvm-objdump -d open_file.o
open_file.o: file format elf64-bpf
Disassembly of section kprobe/do_sys_openat2:
0000000000000000 <hello>:
0: bf 17 00 00 00 00 00 00 r7 = r1
1: 85 10 00 00 ff ff ff ff call -1
2: bf 06 00 00 00 00 00 00 r6 = r0
3: bf 71 00 00 00 00 00 00 r1 = r7
4: 85 10 00 00 ff ff ff ff call -1
5: b7 01 00 00 73 27 00 00 r1 = 10099
6: 6b 1a f8 ff 00 00 00 00 *(u16 *)(r10 - 8) = r1
7: 18 01 00 00 68 6e 61 6d 00 00 00 00 65 3d 27 25 r1 = 2677176009331142248 ll
9: 7b 1a f0 ff 00 00 00 00 *(u64 *)(r10 - 16) = r1
10: 18 01 00 00 25 64 27 20 00 00 00 00 40 70 61 74 r1 = 8386107401860244517 ll
12: 7b 1a e8 ff 00 00 00 00 *(u64 *)(r10 - 24) = r1
13: 18 01 00 00 40 64 69 72 00 00 00 00 66 64 3d 27 r1 = 2827526532227490880 ll
15: 7b 1a e0 ff 00 00 00 00 *(u64 *)(r10 - 32) = r1
16: b7 01 00 00 00 00 00 00 r1 = 0
17: 73 1a fa ff 00 00 00 00 *(u8 *)(r10 - 6) = r1
18: 67 00 00 00 20 00 00 00 r0 <<= 32
19: c7 00 00 00 20 00 00 00 r0 s>>= 32
20: bf a7 00 00 00 00 00 00 r7 = r10
21: 07 07 00 00 e0 fe ff ff r7 += -288
22: bf 71 00 00 00 00 00 00 r1 = r7
23: b7 02 00 00 00 01 00 00 r2 = 256
24: bf 03 00 00 00 00 00 00 r3 = r0
25: 85 00 00 00 72 00 00 00 call 114
26: bf a1 00 00 00 00 00 00 r1 = r10
27: 07 01 00 00 e0 ff ff ff r1 += -32
28: b7 02 00 00 1b 00 00 00 r2 = 27
29: bf 63 00 00 00 00 00 00 r3 = r6
30: bf 74 00 00 00 00 00 00 r4 = r7
31: 85 00 00 00 06 00 00 00 call 6
32: b7 00 00 00 00 00 00 00 r0 = 0
33: 95 00 00 00 00 00 00 00 exit2.1.1 编译用户端加载BPF程序
BPF程序需要用户端程序加载到内核上,并读取ebpf的输出,如下代码:
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
#include "bpf_load.h"
#define MAX_FILENAME_LEN 256
void read_msg(void);
int main(int argc, char *argv[]) {
int ch;
if (argc != 2) {
fprintf(stdout, "Usage: %s <eBPF program>\n", argv[0]);
return 0;
}
if (access(argv[1], R_OK) != 0) {
fprintf(stderr, "ERROR: access('%s'): %s\n",
argv[0], strerror(errno));
return 1;
}
if (load_bpf_file(argv[1])) {
fprintf(stdout, "%s", bpf_log_buf);
return 1;
}
fprintf(stdout, ">>> begin to read trace_pipe...\n");
read_msg();
return 0;
}
void read_msg(void) {
FILE *fp;
char filename[MAX_FILENAME_LEN];
char *line = NULL;
size_t len = 0;
snprintf(filename, sizeof(filename), DEBUGFS "trace_pipe");
fp = fopen(filename, "r");
if (fp == NULL) {
fprintf(stderr, "ERROR: fopen('%s'): %s\n",
filename, strerror(errno));
return;
}
while (getline(&line, &len, fp) != -1) {
fprintf(stdout, "%s", line);
continue;
}
return;
}编译也比较简单:
cc -c -o bpf_load.o bpf_load.c
cc -c -o open_file_user.o open_file_user.c
cc -o bpfopen open_file_user.o -lbpf -lelf bpf_load.o都编译好了,那么来运行下:
./bpfopen open_file.o
[root@localhost hello-openat2]# ./bpfopen open_file.o
bpf_load: section 1:.strtab data 0x3462d50 size 102 link 0 flags 0
bpf_load: section 3:kprobe/do_sys_openat2 data 0x34631d0 size 224 link 0 flags 6
bpf_load: section 4:.rodata.str1.16 data 0x34632c0 size 27 link 0 flags 50
bpf_load: section 5:license data 0x34632f0 size 4 link 0 flags 3
bpf_load: section 6:.eh_frame data 0x3463310 size 48 link 0 flags 2
bpf_load: section 7:.rel.eh_frame data 0x3463350 size 16 link 8 flags 0
bpf_load: section 8:.symtab data 0x3463370 size 120 link 1 flags 0
>>> begin to read trace_pipe...
<...>-231725 [006] d..31 219376.128743: bpf_trace_printk: @dirfd='-100' @pathname='/sys/kernel/debug/tracing/trace_pipe'
irqbalance-928 [006] d..31 219376.546195: bpf_trace_printk: @dirfd='-100' @pathname='/proc/interrupts'
irqbalance-928 [006] d..31 219376.546387: bpf_trace_printk: @dirfd='-100' @pathname='/proc/stat'
pmdalinux-1326 [006] d..31 219378.265136: bpf_trace_printk: @dirfd='-100' @pathname='/proc/net/dev'
pmdalinux-1326 [006] d..31 219378.265198: bpf_trace_printk: @dirfd='-100' @pathname='/proc/net/netstat'
....输出的关键内容解释:irqbalance-928 为进程名和进程id,[006] 表示cpu编号,d..31表示一系列选项, 219376.546195 表示时间戳, bpf_trace_printk:表示函数名,@dirfd='-100' @pathname='/proc/interrupts' 表示输出内容。
三 查看BPF程序
利用bpftool工具查看正在运行的BPF程序
[root@localhost bpfstest]# bpftool prog show
[root@localhost bpfstest]# bpftool prog show
34: kprobe tag b43a500aac124eef gpl
loaded_at 2022-02-26T04:01:15-0500 uid 0
xlated 224B jited 139B memlock 4096B查看bpf字节码内容
root@localhost bpfstest]# bpftool prog dump xlated id 34
0: (79) r6 = *(u64 *)(r1 +112)
1: (79) r3 = *(u64 *)(r1 +104)
2: (b7) r1 = 10099
3: (6b) *(u16 *)(r10 -8) = r1
4: (18) r1 = 0x25273d656d616e68
6: (7b) *(u64 *)(r10 -16) = r1
7: (18) r1 = 0x7461704020276425
9: (7b) *(u64 *)(r10 -24) = r1
10: (18) r1 = 0x273d646672696440
12: (7b) *(u64 *)(r10 -32) = r1
13: (b7) r1 = 0
14: (73) *(u8 *)(r10 -6) = r1
15: (bf) r7 = r10
16: (07) r7 += -288
17: (bf) r1 = r7
18: (b7) r2 = 256
19: (85) call bpf_probe_read_user_str#-62976
20: (bf) r1 = r10
21: (07) r1 += -32
22: (b7) r2 = 27
23: (bf) r3 = r6
24: (bf) r4 = r7
25: (85) call bpf_trace_printk#-54672
26: (b7) r0 = 0
27: (95) exit四 BCC中牛逼的工具
其实我们刚开发的工具在BCC中已经存在类似的,BCC不管有高级语言的接口还有一些牛逼的工具,非常方便,在解决一些麻烦问题的时候很有用:
4.1 execsnoop
这个工具通过追踪execve系统调用,来查看新创建的进程信息,如果我们遇到执行很短的进程,通过top命令看不到用它排查很有帮助,top命令是周期运行的,如果程序很快停止是无法查到的:
#execsnoop
PCOMM PID PPID RET ARGS
ls 232501 230335 0 /usr/bin/ls --color=auto
ls 232502 230335 0 /usr/bin/ls --color=auto
make 232504 230335 0 /usr/bin/make
cc 232505 232504 0 /usr/bin/cc -print-file-name=include
sh 232506 232504 0 /bin/sh -c pkg-config --exists libbpf; echo $?
pkg-config 232507 232506 0 /usr/bin/pkg-config --exists libbpf
sh 232508 232504 0 /bin/sh -c pkg-config --exists libelf; echo $?
pkg-config 232509 232508 0 /usr/bin/pkg-config --exists libelf4.2 opensnoop
这个类似我们上面开发的工具,在每次进行open调用的时候执行,打印打开文件的路径,程序名,进程号,成功还是失败(ERR 为2 表示失败)等信息,如下:
PID COMM FD ERR PATH
928 irqbalance 6 0 /proc/interrupts
928 irqbalance 6 0 /proc/stat
944 vmtoolsd 10 0 /proc/meminfo
944 vmtoolsd 10 0 /proc/vmstat
944 vmtoolsd 10 0 /proc/stat
944 vmtoolsd 10 0 /proc/zoneinfo4.3 io相关
# 直方图的形式来跟踪磁盘IO延迟,会显示磁盘的IO延迟的分布情况不过在我机器上执行失败,估计是事件挂载点发生了变化不兼容导致
biolatency -m
#打印每次io请求延迟大小,磁盘,进程名等信息
biosnoop4.3 cachestat
打印文件缓存的命中情况,用于排查缓存命中过低问题。
4.4 tcpconnect
每次调用tcp的connect时候打印一行信息,包括源地址,目标地址,端口,进程名,和进程id信息,用户发现非法的外连信息。打印信息是对外连接的信息。
4.5 tcpaccept
每次tcp监听接受被动连接的时候打印进程id,进程名,源地址,目标地址,端口信息。
4.6 tcpretrans
每次tcp重传时候会打印一条信息,包括源地址,目标地址,源端口,目标端口,以及连接状态,用于排查tcp网络慢问题。
4.7 runqlat
打印进程等待cpu运行时间的直方图,定位超出预期的cpu时间,可能是cpu包和调度等原因导致。
4.8 profile
cpu执行分析,用于判断cpu的时间主要耗费在哪些代码路径上了,不过我觉得用perf top结合火焰图来的更好些。















 2131
2131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









