






一 前言
前面的文章聊到bpftrace,这是个强大简洁的编写bpf程序的利器,内部的语法看起来比较容易,功能一点也不弱,比如
我们想查看现在系统中谁在执行什么程序:
[root@localhost ~]# bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s-->%s\n",comm,str(args->filename));}'
Attaching 1 probe...
bash-->/usr/bin/cat
bash-->/usr/bin/more系统中程序执行的系统调用次数统计:
[root@localhost ~]# bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid,comm]=count();}'
Attaching 1 probe...
^C
@[894, rpcbind]: 1
@[897, sedispatch]: 2
@[929, gmain]: 4
@[1004, sssd_be]: 5
@[931, HangDetector]: 8
@[730, systemd-journal]: 9
@[1106, systemd-logind]: 14
@[1, systemd]: 15
@[3936, sshd]: 17二 bpftrace 基础语法
提供一个快速上手指南,并不讲究面面俱到,只说明重要内容。
2.1 执行形式
一句话命令 执行
bpftrace -e '命令'有些单行命令只有结束,按ctrl+c结束了才会输出内容。文件形式,文件开头写上
#!/usr/bin/bpftrace如果用到system函数需要加上--unsafe命令形式:probe[,probe,...] /filter/ { action } 即探测事件,过滤器和执行语句,多个语句的话用逗号分隔,最简单的:
bpftrace -e 'BEGIN { printf("Hello eBPF!\n"); }'2.2 分析实际例子说明语法
1 #!/usr/bin/bpftrace
2
3
4 kprobe:vfs_read
5 {
6 @start[tid] = nsecs;
7 }
8
9 kretprobe:vfs_read
10 /@start[tid]/
11 {
12 $duration_us = (nsecs - @start[tid]) / 1000;
13 @us = hist($duration_us);
14 delete(@start[tid]);
15 }这是一个统计read系统掉哦那个耗时的脚本, 第四行,kprobe说明插桩为内核动态函数插桩;@start 说明定义一个名字为start的映射表变量,是用来保存bpftrace的临时数据,也会在程序结束的时候自动输出,@start的映射表为map类型,它的key为tid,这个tid为内部变量,具体说明见下面,nsecs是当前时间,纳秒为单位。这样我们在map中为每个线程在进入read函数的时候,保存各自的纳秒级别的时间戳了。第九行,kretprobe为内核动态函数返回的插桩,第10行为匹配条件,即要存在这个线程的进入read函数的开始时间戳,不然这个值为0,计算的结果就有问题了。第12行,$duration_us即为一个自定义变量,值为这个函数的执行时间,计算方法用当前函数返回时候的时间戳减去进入函数时候的时间戳,单位转成微秒;第13行,定义一个名字为@us的映射表变量,保存的是耗时时间为值的2的幂次方的直方图(看输出结果就明白了),hist为生成直方图的内置函数;第14行,delete函数删除@start映射表里面,key为tid的对象,为什么要删除那,是因为不删除的话,这个脚本结束的时候,凡是映射表的内容都会输出,影响结果查看。
执行下:(执行结果不符合预期,多打印了@start 映射,按道理是已经删除了)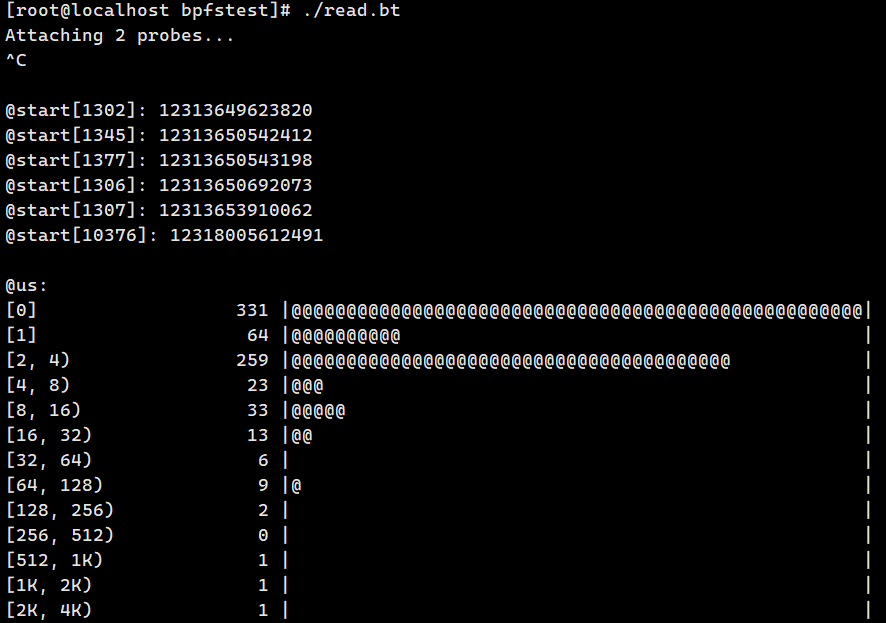
为了更实用点,我们可以打印出不同的线程调用read的返回值分布情况,只要改下第13行,改成:
@us[comm,tid] = hist($duration_us);结果就如下图: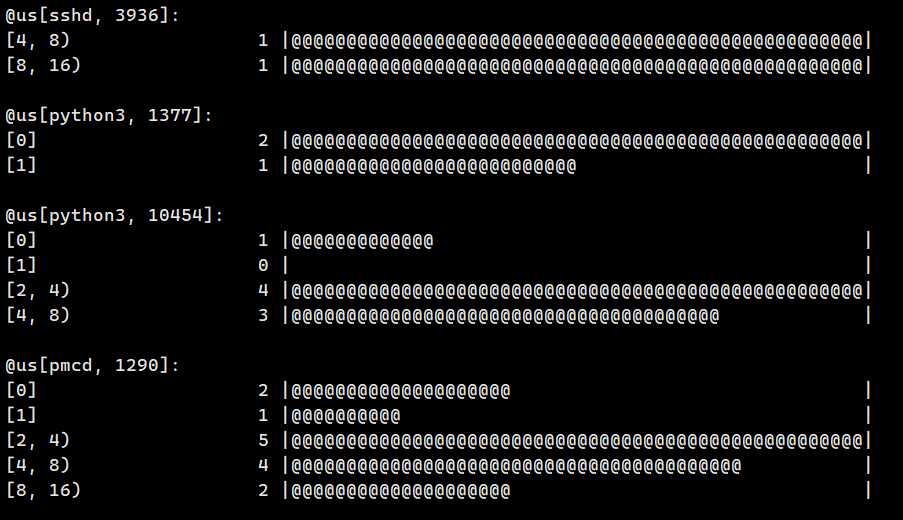 说明下直方图,[ 表示大于等于,)表示小于,比如第一行sshd这个进程名,线程id为3936,它执行耗时在大于等于4微秒到小于等于8微秒中的情况有一条,耗时在大于等于8微秒,小于16微秒的数量有一条。
说明下直方图,[ 表示大于等于,)表示小于,比如第一行sshd这个进程名,线程id为3936,它执行耗时在大于等于4微秒到小于等于8微秒中的情况有一条,耗时在大于等于8微秒,小于16微秒的数量有一条。
2.3 自己写的代码动态追踪
随便写个小程序,如下代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int fun1(int a) {
return a+10;
}
int fun2(int a, int b) {
return a*b;
}
int fun3(int a, int b){
return a+b;
}
int main(int argc,char * argv[])
{
int a = 2,b=4;
printf("a*b=%d\n",fun2(a,b));
getchar();
printf("a+b=%d\n",fun3(a,b));
getchar();
printf("a+10=%d\n",fun1(a));
}查看可以进行用户级动态函数:
[root@localhost ctest]# bpftrace -l 'uprobe:/root/ctest/a.out:*'
uprobe:/root/ctest/a.out:__do_global_dtors_aux
uprobe:/root/ctest/a.out:__libc_csu_fini
uprobe:/root/ctest/a.out:__libc_csu_init
uprobe:/root/ctest/a.out:_dl_relocate_static_pie
uprobe:/root/ctest/a.out:_fini
uprobe:/root/ctest/a.out:_init
uprobe:/root/ctest/a.out:_start
uprobe:/root/ctest/a.out:deregister_tm_clones
uprobe:/root/ctest/a.out:frame_dummy
uprobe:/root/ctest/a.out:fun1
uprobe:/root/ctest/a.out:fun2
uprobe:/root/ctest/a.out:fun3
uprobe:/root/ctest/a.out:main
uprobe:/root/ctest/a.out:register_tm_clones写了个追踪脚本:
#!/usr/bin/bpftrace
uprobe:/root/ctest/a.out:fun2
{
@start[comm,tid] = nsecs;
}
uretprobe:/root/ctest/a.out:fun2
/@start[comm,tid]/
{
$duration_us = (nsecs - @start[comm,tid]) / 1000;
if ($duration_us >100) {
printf("func2 cost too long:%d\n",$duration_us);
}else {
printf("func2 cost normal:%d ret:%d\n",$duration_us,retval);
}
}执行./user.bt 然后执行a.out结果如下:
[root@localhost bpfstest]# ./user.bt
Attaching 2 probes...
func2 cost normal:9 ret:8
^C
@start[a.out, 12459]: 16150154585278是不是觉得很棒,不用改任何代码,就知道函数执行的耗时,对于耗时情况我们可以灵活设置策略,比如告警啥的。
三 bpftrace建立个后门
在写前几篇文章的时候,飞哥联系我说,这玩意不完全,容易建后面,刚好看到一篇用bpftrace建立后面的文章(有不少变动),刚好测试下。原理比较简单,就是对监听的端口进行跟踪,收到远程的连接信息,分析下,如果是发送的秘密字符串,那就执行一个命令,返回执行命令的结果。
3.1 环境建立
随便下载个web容器运行,如下:
yum install nginx
nginx -c /etc/nginx/nginx.conf确认启动如下:
[root@localhost ~]# curl http://127.0.0.1
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
<head>
<title>Test Page for the Nginx HTTP Server on Red Hat Enterprise Linux</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<style type="text/css">
/*<![CDATA[*/
body {
background-color: #fff;
color: #000;
font-size: 0.9em;
...确保程序是ok的。
3.2 编写跟踪程序
这个简单就不介绍了,直接上代码:
#!/usr/bin/bpftrace --unsafe
#include <net/sock.h>
#include <linux/in.h>
#include <linux/in6.h>
BEGIN
{
printf("Welcome to Offensive BPF... Use Ctrl-C to exit.\n");
}
tracepoint:syscalls:sys_enter_accept*
{
@sk[tid] = args->upeer_sockaddr;
}
tracepoint:syscalls:sys_exit_accept*
/ @sk[tid] /
{
@sys_accepted[tid] = @sk[tid];
$sa = (struct sockaddr *) @sk[tid];
if ($sa->sa_family == AF_INET) {
$s = (struct sockaddr_in *) @sk[tid];
$port = ($s->sin_port>>8) | (($s->sin_port<<8) &0xff00);
printf("%-16s %-5d \n",ntop(AF_INET,$s->sin_addr.s_addr),$port);
}
}
tracepoint:syscalls:sys_enter_recvfrom
/ @sys_accepted[tid] /
{
@fds[tid]=args->fd;
@sys_read[tid] = args->ubuf;
}
tracepoint:syscalls:sys_exit_recvfrom
{
$len = args->ret;
if ((@sys_read[tid] != 0) && ($len > 5))
{
xxxxxxxxxxxxxxxxxxxxxx
}
}
tracepoint:syscalls:sys_enter_writev,tracepoint:syscalls:sys_enter_write
/ @exec[tid] == 1 /
{
printf("write to client:");
xxxxxxxxxxxxxxxxxxxxxxx
}
END
{
clear(@cmds);
clear(@fds);
clear(@exec);
clear(@sk);
clear(@sys_read);
clear(@sys_accepted);
printf("Exiting. Bye.\n");
}这段代码有些部分我做了模糊处理,主要是有点敏感,如果想获取完整版本的代码关注TSparks发送”代码“,来获取吧。代码比较简单,在accept的地方可以获取连接的客户端的ip和端口信息,保存起来,我们再接收消息或发送消息的地方,可以判断下这个ip是不是我们控制ip,如果是我们控制ip,就分析下请求的消息,根据请求的消息执行命令,然后把结果发送给我们控制主机。
3.3 如何检查这种后门那
其实也比较简单,首先我们可以查看系统中是否有bpf程序在运行,比如通过bpftool查看:
[root@localhost ~]# bpftool prog
617: tracepoint name sys_enter_accep tag 26c093d1d907ce74 gpl
loaded_at 2022-03-12T20:41:02-0500 uid 0
xlated 128B jited 80B memlock 4096B map_ids 406
618: tracepoint name sys_enter_accep tag 26c093d1d907ce74 gpl
loaded_at 2022-03-12T20:41:02-0500 uid 0
xlated 128B jited 80B memlock 4096B map_ids 406
619: tracepoint name sys_exit_accept tag 0dbf07b51d6729c4 gpl
loaded_at 2022-03-12T20:41:02-0500 uid 0
xlated 1040B jited 577B memlock 4096B map_ids 406,407,409
620: tracepoint name sys_exit_accept tag 0dbf07b51d6729c4 gpl还可以通过sysctl -a|grep bpf 查看内核选项,关闭一些选项:
sysctl -w kernel.unprivileged_bpf_disabled=1还有就比较简单了,如果是bpftrace写的脚本检查unsafe选项。
四 bpftrace 的一些说明
4.1 内置变量表
uid:用户id。
tid:线程id
pid:进程id。
cpu:cpu id。
cgroup:cgroup id.
probe:当前的trace点。
comm:进程名字。
nsecs:纳秒级别的时间戳。
kstack:内核栈描述
curtask:当前进程的task_struct地址。
args:获取该kprobe或者tracepoint的参数列表
arg0:获取该kprobe的第一个变量,tracepoint不可用
arg1:获取该kprobe的第二个变量,tracepoint不可用
arg2:获取该kprobe的第三个变量,tracepoint不可用
retval: kretprobe中获取函数返回值
args->ret: kretprobe中获取函数返回值
BEGIN :bpftrace开始
END:bpftrace 结束4.2 探针类型表
Alias Type Description
t tracepoint Kernel static instrumentation points
U usdt User-level statically defined tracing
k kprobe Kernel dynamic function instrumentation (standard)
kr kretprobe Kernel dynamic function return instrumentation (standard)
f kfunc Kernel dynamic function instrumentation (BPF based)
fr kretfunc Kernel dynamic function return instrumentation (BPF based)
u uprobe User-level dynamic function instrumentation
ur uretprobe User-level dynamic function return instrumentation
s software Kernel software-based events
h hardware Hardware counter-based instrumentation
w watchpoint Memory watchpoint events
p profile Timed sampling across all CPUs
i interval Timed reporting (from one CPU)
iter Iterator tracing over kernel objects
BEGIN Start of bpftrace
END End of bpftrace4.3 内置函数
Function Description
printf("...") Print formatted string
time("...") Print formatted time
join(char *arr[]) Join array of strings with a space
str(char *s [, int length]) Return string from s pointer
buf(void *p [, int length]) Return a hexadecimal string from p pointer
strncmp(char *s1, char *s2, int length) Compares two strings up to length
sizeof(expression) Returns the size of the expression
kstack([limit]) Kernel stack trace up to limit frames
ustack([limit]) User-level stack trace up to limit frames
ksym(void *p) Resolve kernel address to symbol
usym(void *p) Resolve user-space address to symbol
kaddr(char *name) Resolve kernel symbol name to address
uaddr(char *name) Resolve user-space symbol name to address
ntop([int af,]int|char[4:16] addr) Convert IP address data to text
reg(char *name) Return register value
cgroupid(char *path) Return cgroupid for /sys/fs/cgroup/... path
time("...") Print formatted time
system("...") Run shell command
cat(char *filename) Print file content
signal(char[] sig | int sig) Send a signal to the current task
override(u64 rc) Override a kernel function return value
exit() Exits bpftrace
@ = count() Count events
@ = sum(x) Sum the value
@ = hist(x) Power-of-2 histogram for x
@ = lhist(x, min, max, step) Linear histogram for x
@ = min(x) Record the minimum value seen
@ = max(x) Record the maximum value seen
@ = stats(x) Return the count, average, and total for this value
delete(@x[key]) Delete the map element
clear(@x) Delete all keys from the map五 参考网址
bpftrace 语法简单介绍: [bpftrace Cheat Sheet (brendangregg.com)](https://www.brendangregg.com/BPF/bpftrace-cheat-sheet.html)
bpftrace 做的后门 [进攻性 BPF:使用 bpftrace 托管后门 ·拥抱红色 (embracethered.com)](https://embracethered.com/blog/posts/2021/offensive-bpf-bpftrace-message-based/)














 768
768











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









