









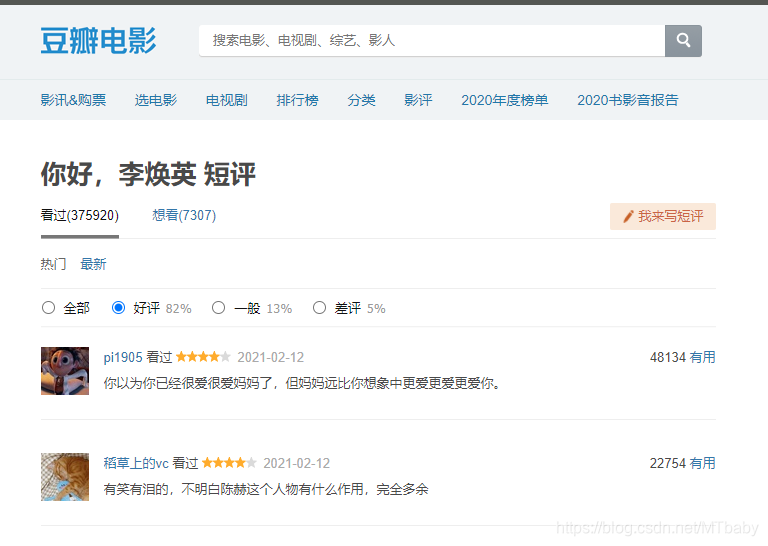
最近比较火的电影《你好,李焕英》莫名戳中了大家的泪点,应用评论中的一句“妈妈永远比想象中的要爱我们”
虽然我没哭,但看大家都哭了,说明电影不在于多有深意,而是能引起大家共鸣的电影,才是好电影。
(完全瞎编的)
下面我们就来看一下《你好,李焕英》在豆瓣影评中都有哪些优质的评论以及出现最多的词是哪些。
1.确定数据所在的url
https://movie.douban.com/subject/34841067/comments?percent_type=h&limit=20&status=P&sort=new_score
2.发送网络请求
使用requests库发送网络请求,并看下他的文本内容。
url = 'https://movie.douban.com/subject/34841067/comments?status=P'
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"}
response = requests.get(url=url,headers=headers)
print(response.text)
看一下抓取到的网页源码:
3.分析数据
使用xpath点位到你想要的数据,可以看到所有评论的定位为//span[@class='short']
备注:关于Google使用xpath定位的方法,可以参考这篇文章《谷歌Xpath-helper插件安装及使用》,特别方便哈哈。
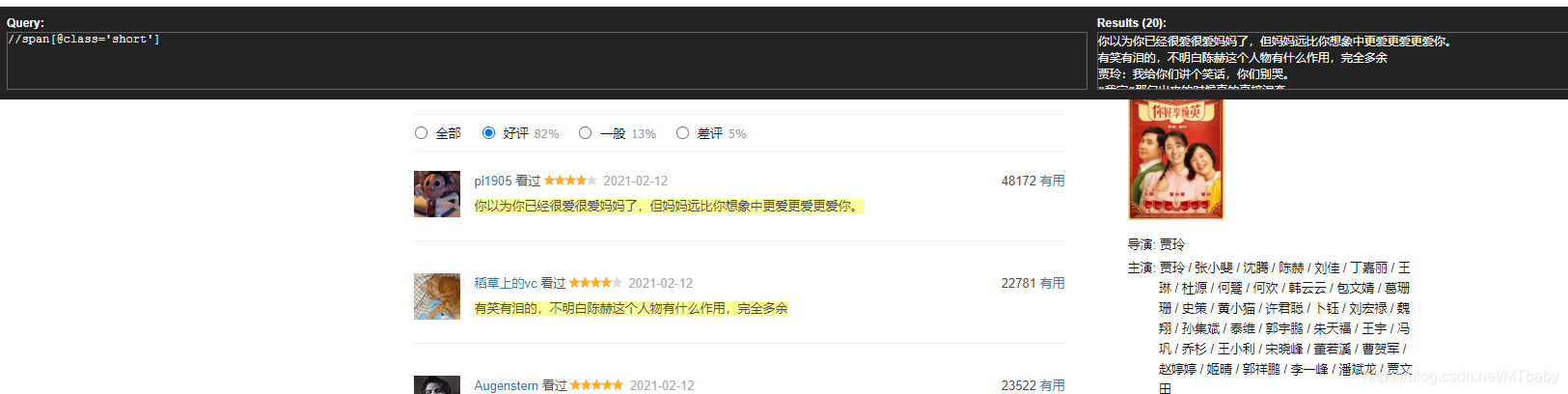
于是,我们获取每条评论文本,使用text(),并获取所有影评,使用getall()函数。
html_data = response.text
selector = parsel.Selector(html_data) # 转换数据类型
comments_list = selector.xpath("//span[@class = 'short']/text()").getall()
print(comments_list)
4.数据存储
将数据保存到txt中,注意把原始数据中的换行符替换掉,并且输入完一条评论后加个换行符。
with open('《你好!李焕英!》.txt',mode = 'a',encoding='utf-8') as f:
for comment in comments_list:
f.write(comment.replace('\n',''))
f.write('\n')
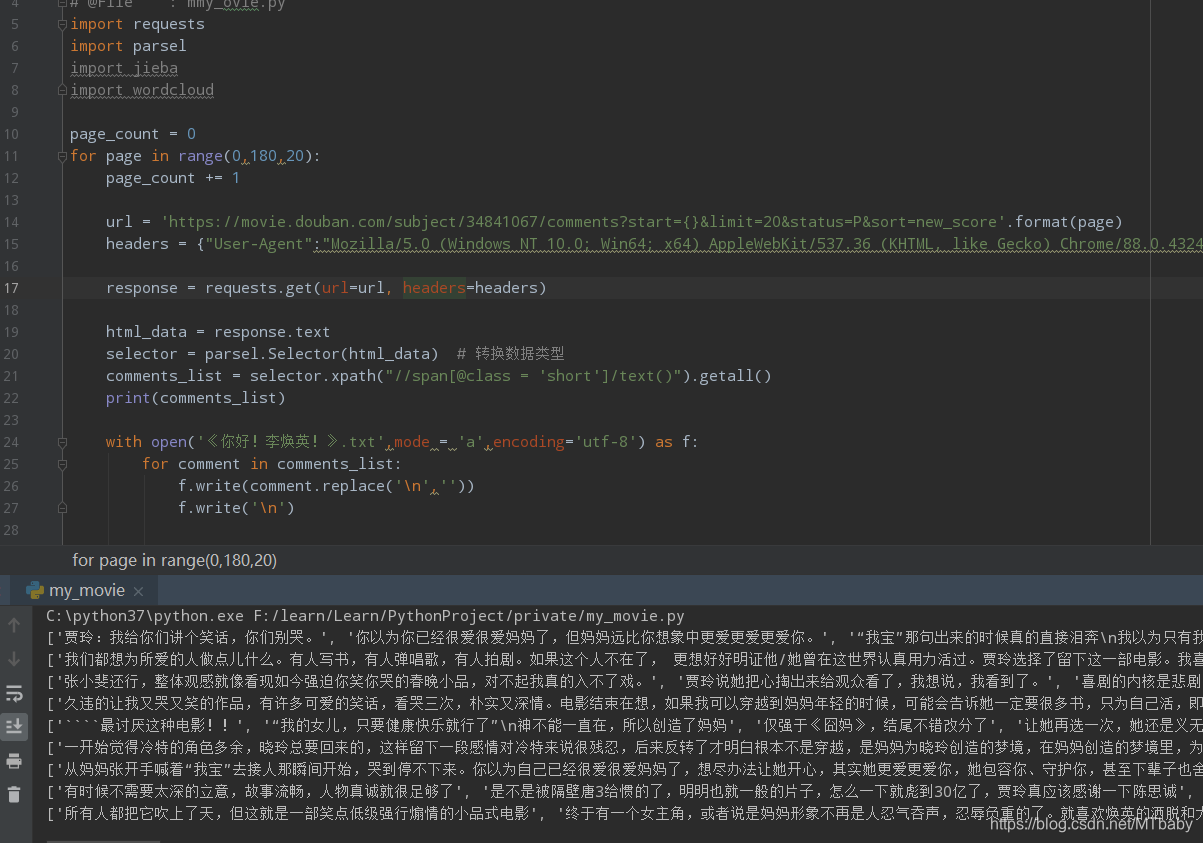
5.爬取10页影评数据
通过分析发现每一页的地址只是start不一样且呈规律出现
https://movie.douban.com/subject/34841067/comments?percent_type=h&start=20&limit=20&status=P&sort=new_score
https://movie.douban.com/subject/34841067/comments?percent_type=h&start=40&limit=20&status=P&sort=new_score
https://movie.douban.com/subject/34841067/comments?percent_type=h&start=60&limit=20&status=P&sort=new_score
于是,我们写一个for循环来爬取10页影评
page_count = 0
for page in range(0,180,20):
page_count += 1
url = 'https://movie.douban.com/subject/34841067/comments?start={}&limit=20&status=P&sort=new_score'.format(page)
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"}
response = requests.get(url=url, headers=headers)
html_data = response.text
selector = parsel.Selector(html_data) # 转换数据类型
comments_list = selector.xpath("//span[@class = 'short']/text()").getall()
print(comments_list)
with open('《你好!李焕英!》.txt',mode = 'a',encoding='utf-8') as f:
for comment in comments_list:
f.write(comment.replace('\n',''))
f.write('\n')
看一下效果,你也可以看到同级目录生成一个“《你好!李焕英!》.txt ” 文件。
6.生成词云库
打开刚才的txt,并使用jiaba库进行分词。这里需要现导入jiaba库,如果没有,就安装一下,pip install jiaba 很简单的
f = open('《你好!李焕英!》.txt',mode = 'r',encoding = 'utf-8')
txt = f.read()
txt_list = jieba.lcut(txt)
string1 = " ".join(txt_list)
设置词云图并制作,这里需要安装并导入wordcloud库
#词云图设置
wc = wordcloud.WordCloud(width= 1000,
height = 800,
background_color = 'white',
font_path ='msyh.ttc',
scale = 15,
stopwords = set([line.strip() for line in open('cn_stopwords.txt',mode='r',encoding='utf-8').readlines()]))
#给词云图输入文字
wc.generate(string1)
#保存词云图
wc.to_file('output.png')
完整代码如下:
# -*- coding:utf-8 -*-
# @Time : 2021/3/15 15:27
# @Author : MTbaby
# @File : my_movie.py
import requests
import parsel
import jieba
import wordcloud
page_count = 0
for page in range(0,181,20):
page_count += 1
print("======================正在爬取第{}页数据========================".format(page_count))
url = 'https://movie.douban.com/subject/34841067/comments?start={}&limit=20&status=P&sort=new_score'.format(page)
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36"}
response = requests.get(url=url,headers = headers)
html_data = response.text
selector = parsel.Selector(html_data) #转换数据类型
comments_list = selector.xpath("//span[@class = 'short']/text()").getall()
with open('《你好!李焕英!》.txt',mode = 'a',encoding='utf-8') as f:
for comment in comments_list:
f.write(comment.replace('\n',''))
f.write('\n')
f = open('《你好!李焕英!》.txt',mode = 'r',encoding = 'utf-8')
txt = f.read()
txt_list = jieba.lcut(txt)
string1 = " ".join(txt_list)
wc = wordcloud.WordCloud(width= 1000,
height = 800,
background_color = 'white',
font_path ='msyh.ttc',
scale = 15,
stopwords = set([line.strip() for line in open('《你好!李焕英!》.txt',mode='r',encoding='utf-8').readlines()]))
#给词云图输入文字
wc.generate(string1)
#保存词云图
wc.to_file('output.png')
查看生成的云图:

创作不易,留下点爱心吧~~















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









