






Word2vec的出现改变了OneHot的高维稀疏的困境,自此之后各种xxx2vec如雨后春笋般冒了出来,用来解决各种嵌入式编码,包括后来的各种Embedding方式其实很多本质上都是Word2vec的延伸和优化。
本主题文章将会分为三部分介绍,每部分的主题为:
-
word2vec的前奏-统计语言模型(点击阅读)
-
word2vec详解-风华不减
-
其他xxx2vec论文和应用介绍
1、背景介绍
word2vec 是Google 2013年提出的用于计算词向量的工具,在论文Efficient Estimation of Word Representations in Vector Space中,作者提出了Word2vec计算工具,并通过对比NNLM、RNNLM语言模型验证了word2vec的有效性。
word2vec工具中包含两种模型:CBOW和skip-gram。论文中介绍的比较简单,如下图所示,CBOW是通过上下文的词预测中心词,Skip-gram则是通过输入词预测上下文的词。
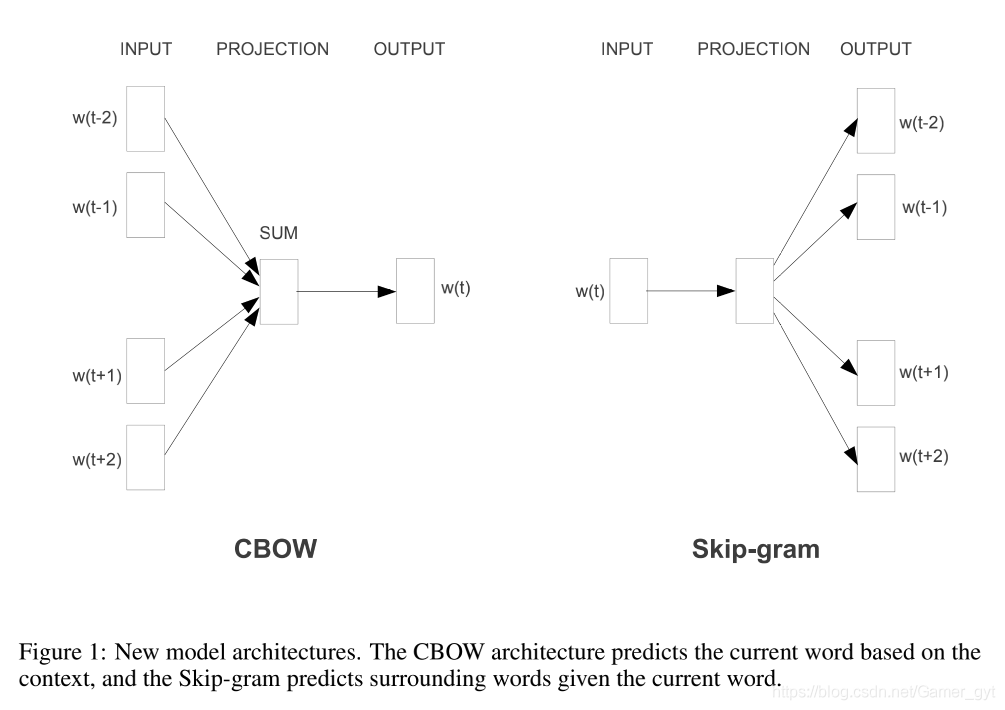
CBOW和skip-gram
2、CBOW 和 Skip-gram
原论文对这两种模型的介绍比较粗略,在论文《word2vec Parameter Learning Explained》中进行了详细的解释和说明,接下来我们详细看下CBOW和Skip-gram。
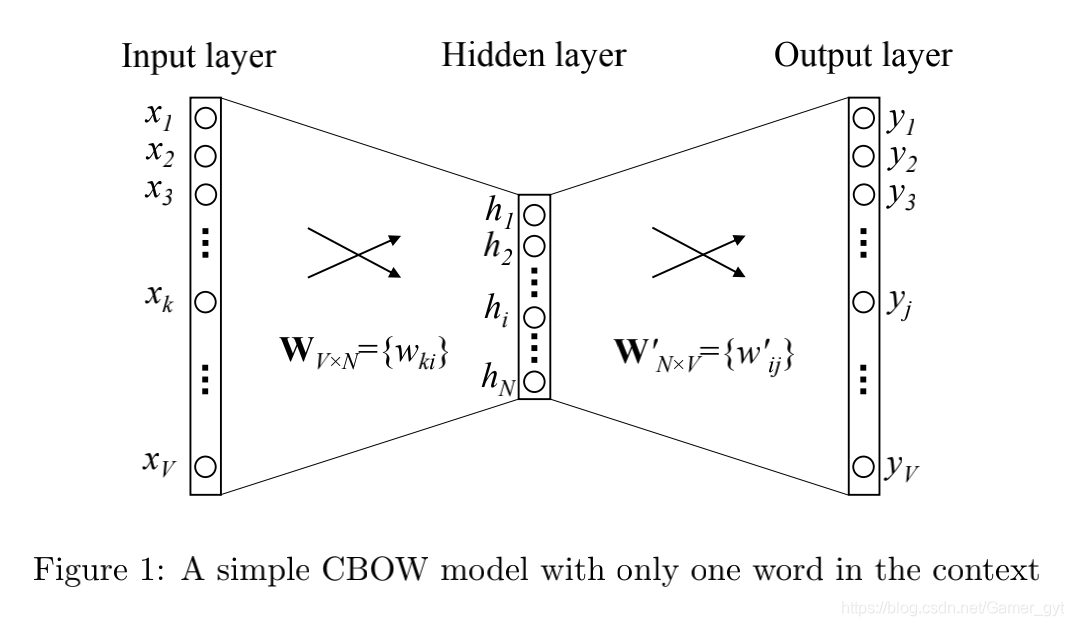
a)CBOW
One-word context


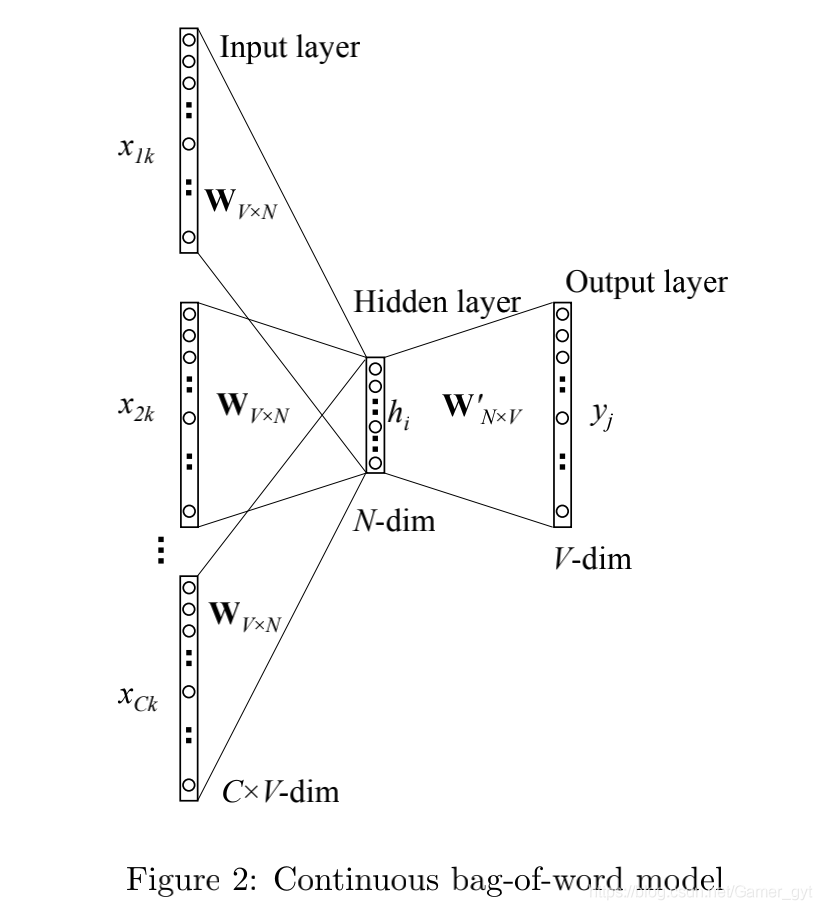
multi-word context

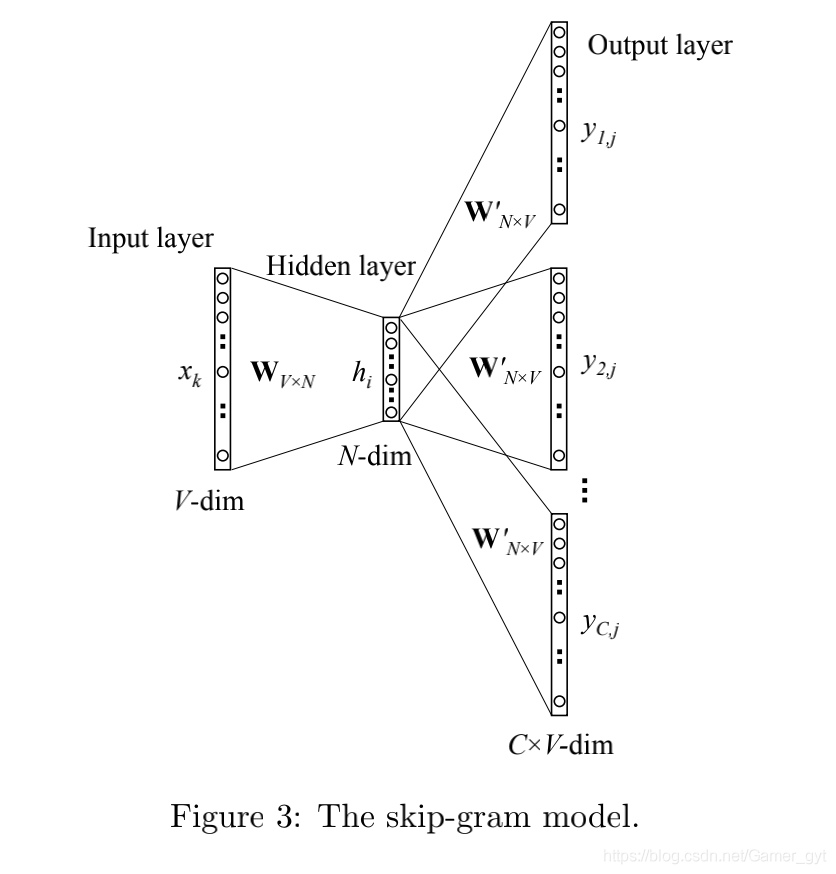
b)Skip-gram

注意⚠️
-
经验上一般选择使用skip-gram模型,因为效果较好
-
在Word2vec模型中,如果选择使用CBOW时,最终产出的word embedding为 单词的输出向量()表示,如果选择使用skip-gram时,最终产出的word embedding为单词的输入向量()表示,因为更倾向于选择靠近中心词一端的权重矩阵。
3、hierarchical softmax 和negative sampling
因为基于word2vec框架进行模型训练要求语料库非常大,这样才能保证结果的准确性,但随着预料库的增大,随之而来的就是计算的耗时和资源的消耗。那么有没有优化的余地呢?比如可以牺牲一定的准确性来加快训练速度,答案就是 hierarchical softmax 和 negative sampling。
在论文《Distributed Representations of Words and Phrases and their Compositionality》中介绍了训练word2vec的两个技(同样在论文《word2vec Parameter Learning Explained》中进行了详细的解释和说明),下面来具体看一下。
a)霍夫曼树和霍夫曼编码

例如一组数据其对应的权重为:[9,11,13,8,4,5],其生成的霍夫曼树为(图来源于百度经验):
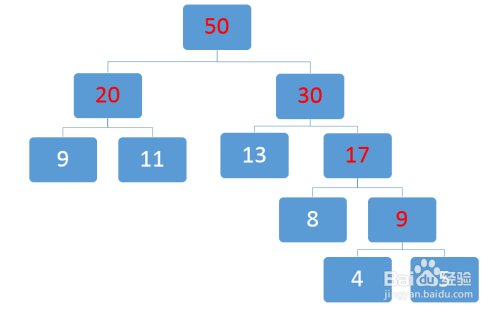
霍夫曼树构建示例
注意⚠️:
-
在构造哈夫曼树时,叶子节点无左右之分,只需约定好一个规则,从头到尾遵守这个规则执行即可。习惯上左节点比右节点小。
那什么又是霍夫曼编码呢?霍夫曼编码是一种基于霍夫曼树的编码方式,是可变长编码的一种。
对于构造好的霍夫曼树进行0/1编码,左子树为0,右子树为1,则针对上图构造好的霍夫曼树,其各个叶子节点的霍夫曼编码分别为:
-
9 -> 00
-
11 -> 01
-
13 -> 10
-
8 -> 110
-
4 -> 1110
-
5 -> 1111
注意⚠️:
-
同样针对霍夫曼树的编码也没有明确规定说左子树为1或者左子树为0
-
在word2vec中,针对霍夫曼树的构建和编码和上边说的相反,即约定左子树编码为1,右子树编码为0(论文中说的是-1,含义一致),同时约定左子树的权重不小于右子树的权重
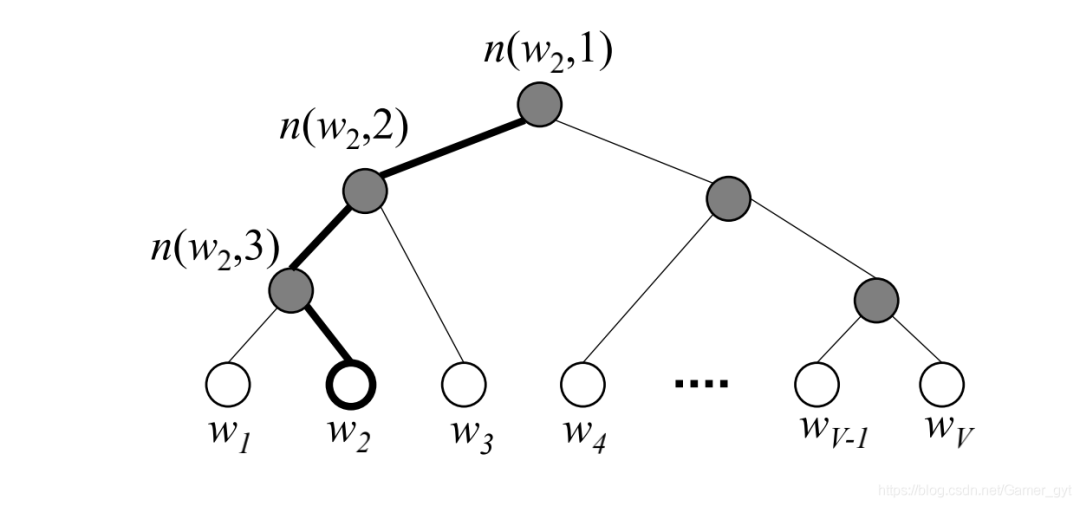
b)hierarchical softmax


c)negative sampling
除了hierarchical softmax,另外一种优化方法是Noise Contrasive Estimation(NCE),在论文《Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics》中有详细的解释和说明,但因为NCE的逻辑有些复杂,所以这里使用的是简化版的,称之为:Negative Sampling。

注意⚠️:
-
基于层次softmax或者negative sampling优化的cbow或者skip-gram模型,输出的词向量应该是输入层到隐藏层之间的词向量(之所以说应该,是因为论文中没有进行特意说明,也没有在公开的资料中看到,可能是我看的不够认真)
-
猜想:能否根据最短路径节点的平均向量来表示叶子结点,即词向量?
-
以上两个问题有读者明白了可以在评论区进行留言,感谢!
4、Gensim中Word2vec的使用
关于gensim的文档可以参考:https://radimrehurek.com/gensim/auto_examples/index.html#documentation
使用之前需要先引入对应的模型类
from gensim.models.word2vec import Word2Vec
创建一个模型
model = Word2Vec(sentences=topics_list, iter=5, size=128, window=5, min_count=0, workers=10, sg=1, hs=1, negative=1, seed=128, compute_loss=True)
其对应的模型参数有很多,主要的有:
-
sentences:训练模型的语料,是一个可迭代的序列
-
corpus_file:表示从文件中加载数据,和sentences互斥
-
size:word的维度,默认为100,通常取64、128、256等
-
window:滑动窗口的大小,默认值为5
-
min_count:word次数小于该值被忽略掉,默认值为5
-
seed:用于随机数发生器
-
workers:使用多少线程进行模型训练,默认为3
-
min_alpha=0.0001
-
sg:1 表示 Skip-gram 0 表示 CBOW,默认为0
-
hs:1 表示 hierarchical softmax 0 且 negative 参数不为0 的话 negative sampling 会被启用,默认为0
-
negative:0 表示不采用,1 表示采用,建议值在 5-20 表示噪音词的个数,默认为5
更多参数可以参考模型中的注释
保存模型
model.save(model_path)
加载模型
model = Word2Vec.load(model_path)
输出loss值
model.get_latest_training_loss()
计算相似度
model.wv.similarity(word1, word2)














 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









