







-
用到的类库
- lucene3.6
-
paoding
代码部分
此类是paoding的一个用法的测试类,可以调用main方法执行看结果:
package com.fengss.paoding;
import java.io.File;
import java.io.IOException;
import net.paoding.analysis.analyzer.PaodingAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Index;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.queryParser.MultiFieldQueryParser;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.TopScoreDocCollector;
import org.apache.lucene.search.highlight.Formatter;
import org.apache.lucene.search.highlight.Fragmenter;
import org.apache.lucene.search.highlight.Highlighter;
import org.apache.lucene.search.highlight.QueryScorer;
import org.apache.lucene.search.highlight.Scorer;
import org.apache.lucene.search.highlight.SimpleFragmenter;
import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.store.LockObtainFailedException;
import org.apache.lucene.util.Version;
import com.fengss.plat.util.TFile;
public class LuceneIndex {
public static void main(String[] args) {
TFile.del("E:/lucpaoding/index");
TFile.del("D:/dev/project/lucene/bin/paoding/dic/.compiled");//测试中先删除原来的字典编译信息,此信息只在第一次运行时生成
LuceneIndex li = new LuceneIndex();
li.createIndex("1", "大形式", " 首先简单介绍一下中文分词器,lucene默认的中文分词器有:单字分词StandardAnalyzer 、 二分法分词 CJKAnalyzer。另外就是外部的词典分词了修改而来,用它写毛博客,将会带来全新的体验哦");
li.createIndex("2", "军方", "跟一位有军方背景的朋友聊天他说对日战争肯定要打,早打比晚打好,这是国际大环境,亚洲小环境所决定的! 战争不以我们意志为转移,虽然我们爱好和平,但我们不畏惧战争!!");
li.createIndex("3", "国际", "在开罗开会的代表们深入讨论了北京百<论持久战>长厂长等文章,美国代表罗斯福表示要在全军开展向张思德学习的大讨论");
li.createIndex("4", "网民", "我自己拍的电影,小小丁丁进度条长长长厂长爱放谁就放谁,银河老师等等,陆续放上去呀急什么真是的!");
li.closeWriter();
li.search(0, "毛","content" );
}
public static String INDEXPATH = "E:/lucpaoding/index";
// 使用庖丁分词器
private PaodingAnalyzer analyzer = null;
private IndexWriter idxwriter = null;
private Document doc = null;
private IndexWriter indexWriter = null;
private IndexReader indexReader = null;
private Object lock_writer = new Object();
private Object lock_reader = new Object();
public LuceneIndex(){
analyzer = new PaodingAnalyzer();
analyzer.setMode(PaodingAnalyzer.MOST_WORDS_MODE);
}
//创建问题答案索引
public void createIndex(String id,String title,String content){
try {
if(idxwriter==null){
idxwriter = getWriter(INDEXPATH);
}
doc = new Document();
doc.add(new Field("id", id , Store.YES, Index.NO));//不分词,把整个内容作为一个记建立索引
doc.add(new Field("title", title, Store.YES, Index.ANALYZED));//分词后并建立索引
doc.add(new Field("content", content, Store.YES, Index.ANALYZED));
//添加到索引中去
idxwriter.addDocument(doc);
} catch (Exception e) {
e.printStackTrace();
}
}
//更新文件索引
public void updateIndex(String id,String title,String content) {
try {
if(idxwriter==null){
idxwriter = getWriter(INDEXPATH);
}
doc = new Document();
doc.add(new Field("id", id , Store.YES, Index.NOT_ANALYZED));//不分词,把整个内容作为一个记建立索引
doc.add(new Field("title", title, Store.YES, Index.ANALYZED));//分词后并建立索引
doc.add(new Field("content", content, Store.YES, Index.ANALYZED));
Term term = new Term("id",id);
indexWriter.updateDocument(term, doc);
} catch (Exception e) {
e.printStackTrace();
}
}
public void search(Integer start,String keyword,String... fields ) {
Directory directory = null;
int pageSize = 10;
IndexSearcher indexSearcher = null;
try {
// 创建索引搜索器且只读
if(indexReader==null){
indexReader = getReader(INDEXPATH);
}
indexSearcher = new IndexSearcher(indexReader);
// 多字段搜索
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_36, fields, analyzer);
Query query = queryParser.parse(keyword.trim());
//取100行数据
TopScoreDocCollector res = TopScoreDocCollector.create(100, false);
//根据关键字搜索整个索引库,然后对所有结果进行排序,然后取前50条结果
indexSearcher.search(query, res);
// 关键字高亮设置
Formatter formatter = new SimpleHTMLFormatter("<font color=red>", "</font>");
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter, scorer);
TopDocs topDocs = res.topDocs(start, pageSize);
ScoreDoc[] hits = topDocs.scoreDocs;
System.out.println("找到【" + topDocs.totalHits + "】条匹配记录");
// 设置摘取字符的长度,默认为100个字符
Fragmenter fragmenter = new SimpleFragmenter();
highlighter.setTextFragmenter(fragmenter);
for (ScoreDoc scoreDoc : hits) {
Document doc = indexReader.document(scoreDoc.doc);
// 关键字高亮显示
String title = highlighter.getBestFragment(analyzer, "title", doc.get("title"));
title = title==null ? doc.get("title") : title;
String content = highlighter.getBestFragment(analyzer, "content", doc.get("content"));
content = content==null ? doc.get("content") : content;
System.out.println("id:"+doc.get("id")+"\t title:"+title+"\t content:"+doc.get("content") );
}
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
try {
if(indexSearcher != null){
indexSearcher.close();
}
if(directory != null){
directory.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
//关闭writer
public void closeWriter() {
synchronized (idxwriter) {
try {
if(idxwriter != null){
idxwriter.close();
idxwriter = null;
};
} catch ( Exception e) {
e.printStackTrace();
}
}
}
public IndexWriter getWriter(String indexpath) throws CorruptIndexException, LockObtainFailedException, IOException {
synchronized(lock_writer){
if(indexWriter == null){
Directory directory = FSDirectory.open(new File(indexpath));
if(IndexWriter.isLocked(directory)){
IndexWriter.unlock(directory);
};
IndexWriterConfig iWriterConfig = new IndexWriterConfig(Version.LUCENE_36, analyzer);
indexWriter = new IndexWriter(directory, iWriterConfig);
};
}
return indexWriter;
}
public IndexReader getReader(String indexpath) throws CorruptIndexException, IOException {
synchronized (lock_reader) {
if(indexReader == null){
indexReader = IndexReader.open(FSDirectory.open(new File(indexpath)));
};
}
return indexReader;
}
//关闭Reader
public void closeReader(IndexReader indexReader) throws IOException {
synchronized (lock_reader) {
if(indexReader != null){
indexReader.close();
};
}
}
}
paoding-dic-home.properties
#values are "system-env" or "this";
#if value is "this" , using the paoding.dic.home as dicHome if configed!
#paoding.dic.home.config-first=system-env
paoding.dic.home.config-first=this
#dictionary home (directory)
#"classpath:xxx" means dictionary home is in classpath.
#e.g "classpath:dic" means dictionaries are in "classes/dic" directory or any other classpath directory
#指定了字典文件的位置 当前放到了classpath下的paoding/dic下面
paoding.dic.home=classpath:paoding/dic
#seconds for dic modification detection
#paoding.dic.detector.interval=60
paoding.properties
paoding.config.file=classpath:paoding.properties
#配置字段文件的路径
paoding.dic.home=classpath:paoding/dic
#配置索引文件存放的位置
paoding.index.home =E\:/lucpaoding/index
paoding.knife.class.letterKnife=net.paoding.analysis.knife.LetterKnife
paoding.knife.class.numberKnife=net.paoding.analysis.knife.NumberKnife
paoding.knife.class.cjkKnife=net.paoding.analysis.knife.CJKKnife
代码结构图如下:
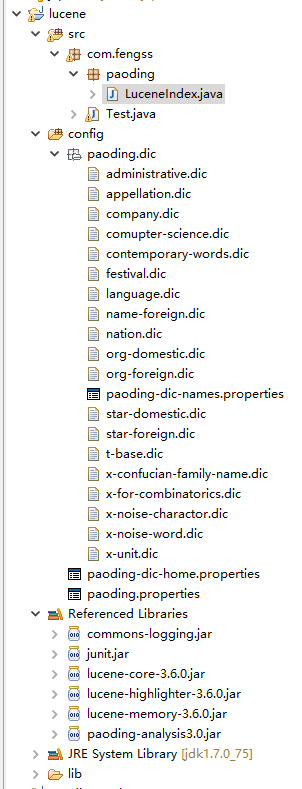
##简单描述下文件的用法
paoding.dic下面的文件是从paoding的原始包中复制过来的,直接放到项目中
中间有个paoing-dic-names.properties 指定了一些过滤的规则,默认是按其他的文章中的内容进行分词
但会过滤掉以x-开头的文件中的内容 。
最下面两个文件 也是直接复制过来,直接修改就可以了。















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









