






文章目录
思维导图

序列
- 概况
序列是一种数据存储方式,用来存储一系列数据。在内存中,序列就是一块地用来存放多个值的连续的内存空间。比如一个整数序列[1,2,3,4],可以表示为:

在python3中一起皆对象,在内存中实际是按照下图方式存储的:
a=[1,2,3,4]
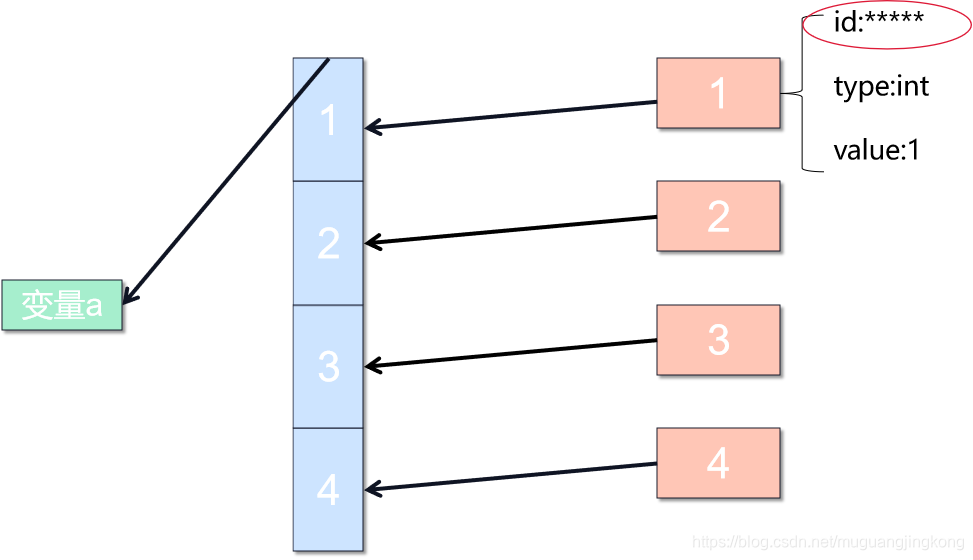
注意:四个元素就是四个对象,而存入列表的是这些对象的地址,不是值。列表本身也是对象,列表的地址传给了变量a
- 常用的序列结构:
字符串,列表,元组,字典,集合
一、列表简介
列表是用于存储任意数目、任意类型的数据结合
列表是可变序列,是包含多个元素的有序连续的内存空间
列表中的元素可以各不相同,可以是任意类型
>>> a=[1,2,'hi']
>>> a
[1, 2, 'hi']
二、列表的创建
1.基本语法[]创建
2.list()创建
使用list()可以将任何可迭代的数据转化为列表。数字,字符串均可。
>>> a=list(range(5))
>>> a
[0, 1, 2, 3, 4]
>>> a=list('hello')
>>> a
['h', 'e', 'l', 'l', 'o']
3.range()创建列表
range()语法格式为:
range([start]: end :step])
start参数:可选,表示起始数字,默认是0
end参数:必选,表示结尾数字。
step参数:可选,表示步长,默认为1,步长为复数表示倒序
python3中range()返回的是一个range 对象,而不是列表。我们需要通过list()方法将其转换成列表对象
>>> a=list(range(3,10,3))
>>> a
[3, 6, 9]
>>> a=list(range(3,-6,-1))
>>> a
[3, 2, 1, 0, -1, -2, -3, -4, -5]
>>> a=list(range(3,-6,-2))
>>> a
[3, 1, -1, -3, -5]
4.推导式生成列表
循环创建多个元素
>>> a=[x*3 for x in range(5)]
>>> a
[0, 3, 6, 9, 12]
用if条件过滤
>>> a=[x*3 for x in range(5) if x%2==0]
>>> a
[0, 6, 12]
三、元素添加
列表元素的增加和删除
当列表增加和删圳除元素时,列表会自动就进行内存管理,大大减少了程序员的负担。但这个特点涉及列表元素的大量移动,效率较低。除非必要,一般只在列表的尾部添加元素或删除元素,这会大大提高列表的操作效率。
1.append()方法
原地修改列表对象,在列表尾部添加新的元素,速度最快,推荐使用。
>>> a=[5,6]
>>> a.append(7)
>>> a
[5, 6, 7]
2.+运算符操作
并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。这样会涉及大量的复制操作,对于操作大量元索不建议使用。
>>> a=[10,20]
>>> id(a)
2602949497864
>>> a=a+[40]
>>> id(a)
2602949500680
>>> a
[10, 20, 40]
这里比较奇怪
>>> a+=[2]
>>> a
[10, 20, 40, 2]
>>> id(a)
2602949500680
3.extend()方法
将目标列表的所有元素添加到本列表的 尾部,是原地操作,不创建新的列表对象
>>> a=[10,20]
>>> b=[20,30]
>>> a.extend(b)
>>> a
[10, 20, 20, 30]
4.insert()插入元素
使用insert()方法可以将指定的元素插入到表对象的任意制定位置。这样会让插入位置后面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用。类似发生这种移动的函数还有:remove()、pop()、del(),它们在删除非尾部元素时也会发生操作位置后面元素的移动。
>>> a=[10,20]
>>> a.insert(1,100) #在a[1]位置插入100
>>> a
[10, 100, 20]
5.乘法扩展
使用乘法扩展列表,生成一个新列表,新列表元素是原列表元素的多次重复
>>> a=[10,20]
>>> id(a)
2602949567304
>>> a*3
[10, 20, 10, 20, 10, 20]
>>>
>>> id(a*3)
2602949578376
四、元素删除
1.del 删除
删除列表指定位置的元素
>>> a=[1,2,3,4,5,6]
>>> del a[1]
>>> a
[1, 3, 4, 5, 6]

2.pop()方法
pop()删除并返回指定位置元素,如果没有指定位置则默认操作列表最后一个元素
>>> a=[1,2,3,4,5,6]
>>> a.pop()
6
>>> a
[1, 2, 3, 4, 5]
>>> a.pop(3) #3是列表中元素的位置
4
>>> a
[1, 2, 3, 5]
3.remove()方法
删除首次出现的指定元素,不存在该元素抛出异常
>>> a=[1,2,3,4,5,6]
>>> a.remove(9)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: list.remove(x): x not in list
>>> a.remove(5)
>>> a
[1, 2, 3, 4, 6]
五、元素访问和计数
1.通过索引直接访问元素
我们可以通过索引 直接访问元素,索引的区间在[0,len(列表)-1],超出这个范围报错
>>> a=[1,2,3,4,5,6]
>>> a[6]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: list index out of range
>>> a[5]
6
2.index()
index()获得指定元素在列表中首次出现的索引
语法:index(value,[start,end])
>>> a=[1,2,3,4,5,4,3,2,1]
>>> a.index(2)
1
>>> a.index(3,3)#从索引位置3开始向后搜索第一个3
6
>>> a.index(4,1,7) #从索引位置1开始向后搜索第一个4,直到索引位置7,不包括位置7
3
3.count()获得指定元素在列表中出现的次数
>>> a=[1,2,3,4,5,4,3,2,1]
>>> a.count(5)
1
4.len()
返回列表长度,即是列表包含元素个数
5.成员资格判断
判断列表中是否有某个元素用关键字in
>>> a=[1,2,3,4,5,4,3,2,1]
>>> 6 in a
False
六、切片操作
切片是Python序列及其重要的操作,适用于列表、元组、字符串等等。切片的格式下:
切片slice 操作可以让我快速提是取子列表或修改。标格式为:
[起始偏移量start:终止偏移量end:步长step]
注:当步长省略时顺便可以省略第二个冒号
- 典型操作(三个量为正数的情况)如下:

- 其他操作(三个量为负数的情况)如下:

注:切片操操作时,起始偏移量和终止偏移量不在范围内,也不报错。起始偏移量小于0则会当做0,终止偏移量大于‘列表长度-1’,会被当成‘列表长度-1’
>>> a=[1,2,3,4,5,4,3,2,1]
>>> a[0:10]
[1, 2, 3, 4, 5, 4, 3, 2, 1]
七、排序
1.sort()修改原列表,不建新列表
>>> a=[1,2,3,4,5,4,3,2,1]
>>> a.sort() #默认升序
>>> a
[1, 1, 2, 2, 3, 3, 4, 4, 5]
>>> a.sort(reverse=True) #降序
>>> a
[5, 4, 4, 3, 3, 2, 2, 1, 1]
2.sorted()建新列表
排序返回新列表 ,不对原列表修改
>>> a=[1,2,3,4,5,4,3,2,1]
>>> id(a)
2602949822728
>>> a=sorted(a)
>>> a
[1, 1, 2, 2, 3, 3, 4, 4, 5]
>>> id(a)
2602949833928
3.reverse()
单纯将列表元素反着排序
>>> a=[1,2,3,4,5,4]
>>> a.reverse()
>>> print(a)
[4, 5, 4, 3, 2, 1]
4.reversed()返回迭代器
reversed()也支持逆序排列,与列表对象reverse()方法的区别是,reversed()不对原列表修改,只是返回一个逆序排列的迭代器对象
>>> a=[1,2,3,4,5,4,3,2,1]
>>> c=reversed(a)
>>> c
<list_reverseiterator object at 0x0000025E0BE6D9C8>
>>> list(c)
[1, 2, 3, 4, 5, 4, 3, 2, 1]
>>> list(c) #第二次运行,已经变成空列表
[]
八、列表相关的其它内置函数
1.max和min,用于返回列表中最大值和最小值
2.sum对数值型列表的所有元素进行求和,对非数值运算报错
>>> a=[1,2,3,4,5,4,3,2,1]
>>> max(a)
5
>>> sum(a)
25
九、多维列表
一维列表存储一维、线性数据
二维列表存储二维、表格的数据
姓名 年龄 城市
狗蛋 22 北京
旺财 23 长沙
铁柱 22 南京
>>> a=[['狗蛋',22,'北京'],
... ['旺财',23,'长沙'],
... ['铁柱',22,'南京']]
>>> a
[['狗蛋', 22, '北京'], ['旺财', 23, '长沙'], ['铁柱', 22, '南京']]
>>> a[1]
['旺财', 23, '长沙']
>>> a[1][2]
'长沙'
嵌套循环打印二维列表所有数据
>>> for m in range(3):
... for n in range(3):
... print(a[m][n],end="\t")
... print()
...
狗蛋 22 北京
旺财 23 长沙
铁柱 22 南京
十、元组
1.特点
列表属于可变序列,可以任意修改列表中的元素。元组属于不可变序列,不能修改元组中的 元素。因此,元组没有增加元素、修改元素、删除元素相关的方法。
因比,我们只需要学习元组的创建和删除,元组中元素的访间问和计数即可。元组支持如下操作:
索引访间
切片操作
连接操作
成员关系操作
比较运算操作年
计数∶元组长度len、最大值max、最小值min、求和 sum等。
并且这些操作与列表是一样的
2.元组的创建
通过()创建,()可以省略
>>> a=1,2,3
>>> a
(1, 2, 3)
>>> a
(1,)
如果元组只有一个元素,必须后面加逗号
通过tuple()创建
>>> b=tuple('123')
>>> b
('1', '2', '3')
>>> b=tuple([1,2,3])
>>> b
(1, 2, 3)
生成器推导创建元组
从形式上看,生成器推导式与列表推导式类似,只是生成器推导式使用小括号。列表推导式直接生成为表对象,生成器推导式生成的不是列表也不是元组,而是—个生成器对象。
我们可以通过生成器对象,转化成列表或者元组。也可以使用生成器对象的_next_()方法进行遍历,或者直接作为迭代器对象来使用。不管什么方式使用,元素访问结束后,如果需要重新访问回其中的元素,必须重新创建该生成器对象。
>>> a=(x*3 for x in range(5))
>>> a
<generator object <genexpr> at 0x0000025E0BE32C48>
>>> tuple(a)
(0, 3, 6, 9, 12)
>>> list(a) #只能访问一次,第二次就为空了,需要再生成一次
[]
>>> a
<generator object <genexpr> at 0x0000025E0BE32C48>
>>> a=(x*3 for x in range(5))
>>> a.__next__()
0
>>> a.__next__()
3
>>> a.__next__()
十一、元组元素的访问、排序
1.访问
同列表一样,不过返回的是元组对象
>>> a=(1,2,3,4,5,4,3,2,1)
>>> a[0:2]
(1, 2)
2.排序
因为元组元素不能修改,只能用sorted()排序
>>> a=(1,2,3,4,5,4,3,2,1)
>>> sorted(a)
[1, 1, 2, 2, 3, 3, 4, 4, 5]
十二、元组总结
1.元组的核心带点是:不可变序列。
2.元组的访问和处理速度比列表快。
3.与整数和字符串一样,元组可以作为字典的键,列表则永远不能作为字典的键使用。















 8471
8471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









