






ES概述
Elasticsearch,简称为es,es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构DB Engines的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
ES简介
Elasticsearch简介
Elasticsearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。它用于全文搜索、结构化搜索、分析以及将这三者混合使用∶
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能。
英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回
应
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。 Github使用Elasticsearch检索1300亿行的代码。
但是Elasticsearch不仅用于大型企业,它还让像DataDog以及Klout这样的创业公司将最初的想法变成可扩展的解决方案。 Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据。
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
LUCENE简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引擎,部分文本分析引擎(英文与德文两种西方语言)。 Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言 , Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene是一个全文检索引擎的架构。那什么是全文搜索引擎 ?
全文搜索引擎是名副其实的搜索引擎,国外具代表性的有Google、Fast/AlITheWeb、AltaVista、Inktomi、Teoma、WiseNut等,国内著名的有百度(Baidu)。它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,因此他们是真正的搜索引擎。
从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称"蜘蛛"(Spider)程序或"机器人"(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中调用,如上面提到的7家引擎;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如Lycos引擎。
ES 和 solr比较
1、es基本是开箱即用(解压就可以用!), 非常简单。Solr安装略微复杂一丢丢 ! 2、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。 3、Solr 支持更多格式的数据,比如SON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
4、Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要 kibana友好支撑~!
5、Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用 ;●ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
● Solr是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
6、Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
ES安装教程
https://blog.csdn.net/qq_40942490/article/details/111594267
IK中文分词器
安装IK分词器之后,可以配置属于自己的字典,具体目录在config 中的xml文件中配置



ES数据结构与mysql的相同之处

使用RESTful风格接口操作ES

使用put命令创建索引(相当于数据库)以及数据,其中test1为索引,type为类型,1为行

ES搜索中的数据类型
核心数据类型
String, byte, short,integer,long,float,double,boolean,date
复合数据类型
Array,Object
使用put命令设计索引的数据类型

如果没有设置数据类型,就会在set值的时候自动设置数据类型

获取有多少索引

put命令
使用put命令可以直接覆盖数据,其中数据完全被覆盖,以新PUT进去的数据为主




其对应的版本号也是会更改的

更新命令
使用更新的命令,会根据字段名更新对应的值


删除命令

查询
准备数据

执行搜索命令

执行完搜索之后就发现通过 ‘小米’和‘mix4’都是可以进行查询的 ,然后通过分词器看看“小米mix4”,发现这个字符串被分词为 ‘小米’和‘mix4’,其中英文不分词

因为英文不分词 通过中文加部分英文(或者部分数字)的方式是不能查询出来的,而且通过分词器是可以开到分词成功的了。(说明,部分英文具体指分词之后的单词的一部分,例如 小米mix4 会被分为 ‘小米’+‘mix4’,其中‘m’就是mix4的部分英文)


条件查询指定字段 其中match是会使用分词器进行解析的

根据字段排序

分页 使用from和size

布尔值查询
其中 must 相当于mysql中的and;

should相当于mysql中的or;

must_not是不等于的意思(例如下面查询的是name不是小米和desc中没有买的)

Filter过滤器
查询名称中有小米的产品,且价格范围在100到2000的

多条件查询,多个条件使用空格或者逗号隔开,只要满足一个就可以被查询出来,这个时候可以通过分值进行计算,比如找房子,可以根据多个地区查找

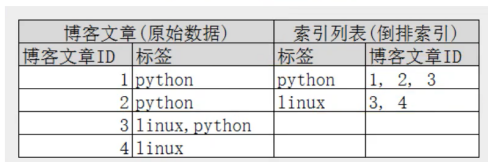
倒排索引!
关于分词器
搜索关键字
Match:是会经过分词器解析的

Term: 是精确查询,不经过分词器解析

数据字段类型不同
当字段类型是text时,是会经过分词器解析的
当字段类型是keyword时,不会经过分词器解析

例如我们在设计索引时,设置name是关键字,desc是text,则在我们搜索时会出现以下情况




高亮查询
使用highlight关键字,然后指定字段,默认样式是标签

自定义标签,要使用pre_tags和post_tags

引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
创建配置文件
package com.mu.es.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1", 9200, "http")
));
return client;
}
}
测试类
@SpringBootTest
class ElasticsearchApplicationTests {
// 注入ES客户端
@Autowired
RestHighLevelClient restHighLevelClient;
@Test
void testCreateIndex() throws IOException {
// 创建索引
CreateIndexResponse text_index = restHighLevelClient.indices().create(new CreateIndexRequest("text_index"), RequestOptions.DEFAULT);
System.out.println("text_index = " + text_index);
}
@Test
void test1() throws IOException {
// 判断索引是否存在
GetIndexRequest textIndexGet = new GetIndexRequest("text_index"); // 创建获得索引的请求
boolean exists = restHighLevelClient.indices().exists(textIndexGet, RequestOptions.DEFAULT);
System.out.println("exists = " + exists);
}
/**
* 删除索引
*
* @throws IOException
*/
@Test
void test2() throws IOException {
DeleteIndexRequest de = new DeleteIndexRequest("text_index");// 创建删除索引的请求
AcknowledgedResponse response = restHighLevelClient.indices().delete(de, RequestOptions.DEFAULT);
System.out.println("exists = " + response);
}
/**
* 在索引中添加文档数据
*
* @throws IOException
*/
@Test
void test3() throws IOException {
// 准备数据
User user = new User("mls", 25, "河南");
// 拿到索引的请求
IndexRequest request = new IndexRequest("text_index");
// 设置id
request.id("1");
// 设置请求的超时时间
request.timeout("1s");
// 将数据放入request请求
request.source(JSON.toJSONString(user), XContentType.JSON);
// 将请求发送到ES
IndexResponse index = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println("index = " + index.toString());
System.out.println("index.status() = " + index.status());
}
/**
* 判断文档是否存在
*
* @throws IOException
*/
@Test
void test4() throws IOException {
// 准备请求
GetRequest request = new GetRequest("text_index", "1");
Boolean exists = restHighLevelClient.exists(request, RequestOptions.DEFAULT);
System.out.println("exists = " + exists);
}
/**
* 获取文档信息
*
* @throws IOException
*/
@Test
void test5() throws IOException {
// 准备请求
GetRequest request = new GetRequest("text_index", "1");
// 获取文档内容
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
// 获取文档中具体存储的内容
System.out.println(response.getSourceAsString());
System.out.println(response);
}
/**
* 更新文档信息
*
* @throws IOException
*/
@Test
void test15() throws IOException {
// 准备数据
User user = new User();
user.setUsername("穆利帅");
// 准备请求
UpdateRequest request = new UpdateRequest("text_index", "1");
// 设置请求超时时间
request.timeout("2s");
// 将数据放在doc中
request.doc(JSON.toJSONString(user), XContentType.JSON);
// 发送请求
UpdateResponse update = restHighLevelClient.update(request, RequestOptions.DEFAULT);
System.out.println("update.status() = " + update.status());
}
/**
* 删除信息
*
* @throws IOException
*/
@Test
void test25() throws IOException {
// 准备请求
DeleteRequest request = new DeleteRequest("text_index", "1");
// 设置请求超时时间
request.timeout("2s");
// 发送请求
DeleteResponse delete = restHighLevelClient.delete(request, RequestOptions.DEFAULT);
System.out.println("update.status() = " + delete.status());
}
/**
* 批量插入
*/
@Test
void test11() throws Exception {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
List<User> users = new ArrayList<>();
users.add(new User("穆利帅0", 24, "beijing"));
users.add(new User("穆利帅1", 25, "beijing"));
users.add(new User("穆利帅2", 26, "beijing"));
users.add(new User("穆利帅3", 27, "beijing"));
users.add(new User("穆利帅4", 28, "beijing"));
users.add(new User("穆利帅5", 29, "beijing"));
for (int i = 0; i < users.size(); i++) {
// 同样批量更新和批量删除也是一样的
IndexRequest request = new IndexRequest("text_index");
request.id(String.valueOf(i))
.source(JSON.toJSONString(users.get(i)), XContentType.JSON);
bulkRequest.add(request);
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println("bulk.status() = " + bulk.status());
}
/**
* 查询
*
* @throws Exception
*/
@Test
void test111() throws Exception {
// 准备请求
SearchRequest searchRequest = new SearchRequest("text_index");
// 准备查询条件
SearchSourceBuilder builder = new SearchSourceBuilder();
// builder.query(QueryBuilders.termQuery("username","穆利帅1")); // 精确查询 分词器不分词
builder.query(QueryBuilders.matchQuery("username","穆利帅")); // 分词查询 分词器分词
// 起始
builder.from(0);
// 每页数目
builder.size(10);
// 排序
builder.sort("age", SortOrder.DESC);
// 设置查询条件的过期时间
builder.timeout(new TimeValue( 60, TimeUnit.SECONDS));
// 设置请求条件
searchRequest.source(builder);
// 发出查询请求
SearchResponse res = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = res.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("hit.getSourceAsString() = " + hit.getSourceAsString());
}
}
}















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}