









介绍
- TimSort是一个稳定、自适应、迭代的归并排序算法实现。
- TimSort是归并排序的优化版,它比传统归并排序中触发的归并次数要少
- Java版的实现是一个类,并直接用在了Arrays工具类中,用于对象排序,该类是改编自Tim Peters的Python集合排序算法实现。想详细了解,请查阅以下链接:
Python_link
C_link
源码阅读
package java.util;
/**
* 这个类里的排序方法是静态的,但是权限是默认的,所以我们自己想用一般就要创建一个实例调用。
* TimSort中有一些优化,它针对不同的数组长度,会使用不同的算法,只有输入的数组长度足够长
* 的时候,才能完全使用TimSort算法。而如果长度不够,它会执行二分插排排序来处理。
*
* @author Josh Bloch
*/
class TimSort<T> {
/**
* 最小会触发归并的序列长度。小于该值的序列将执行binarySort(没有执行任何归并)。
*
* 这个常量必须是2的倍数。 Tim Peter's 在C语言中的实现使用的是64,而在此使用32性能会更好些。
* 后面的是自定义该参数要同步修改哪些地方的提示,这里省略。
*/
private static final int MIN_MERGE = 32;
/**
* 要排序的数组
*/
private final T[] a;
/**
* 用于排序的集合
*/
private final Comparator<? super T> c;
/**
* When we get into galloping mode, we stay there until both runs win less
* often than MIN_GALLOP consecutive times.
*/
private static final int MIN_GALLOP = 7;
/**
* This controls when we get *into* galloping mode. It is initialized
* to MIN_GALLOP. The mergeLo and mergeHi methods nudge it higher for
* random data, and lower for highly structured data.
*/
private int minGallop = MIN_GALLOP;
/**
*最大初始化用于归并的临时数组大小,数组可以按需扩大。
*
* 跟Tim 的C版本不一样,当排序数组比较小的时候,我们没有分配那么大的存储空间。
* 这一更改是为了性能。
*/
private static final int INITIAL_TMP_STORAGE_LENGTH = 256;
/**
* 用于归并时的临时存储数组。可选择在构造中提供该工作空间数组,使用多少就分配多大。
*/
private T[] tmp;
private int tmpBase; // base of tmp array slice
private int tmpLen; // length of tmp array slice
/**
* 待归并的挂起run中的堆栈大小(此处用run作为别名)。这个挂起的堆栈是一个虚拟的堆栈。
* 记录这个run堆栈的参数有以下3个变量。
* 1) stackSize 记录堆栈中待归并run部分的个数
* 2) runBase 是一个数组,记录着待排序数组(a)中每一个排好序待归并部分的起始位置
* 3) runLen 是一个数组,记录着待排序数组(a)中每一个排好序待归并部分的长度(元素个数)
* Run i starts at
* address base[i] and extends for len[i] elements. It's always
* true (so long as the indices are in bounds) that:
*
* runBase[i] + runLen[i] == runBase[i + 1]
*
* so we could cut the storage for this, but it's a minor amount,
* and keeping all the info explicit simplifies the code.
*/
private int stackSize = 0; // Number of pending runs on stack
private final int[] runBase;
private final int[] runLen;
/**
* 创建一个TimSort实例来维护正在进行的排序的状态
*
* @param a the array to be sorted 待排序对象数组
* @param c the comparator to determine the order of the sort 对象的Comparetor对象
* @param work a workspace array (slice) 工作空间
* @param workBase origin of usable space in work array 工作空间中可用空间原点的指针位置
* @param workLen usable size of work array 工作空间中可用空间大小
*/
private TimSort(T[] a, Comparator<? super T> c, T[] work, int workBase, int workLen) {
this.a = a;
this.c = c;
// 分配临时存储空间,如果需要,后面增加它的大小
int len = a.length;
/* 分隔临时空间的基数,如果待排序数组的大小小于512,则直接指定分割基数为length/2,
* 如果待排序数组的大小大于等于512则,直接指定分割基数为256。
*/
int tlen = (len < 2 * INITIAL_TMP_STORAGE_LENGTH) ?
len >>> 1 : INITIAL_TMP_STORAGE_LENGTH;
// 基本入参校验,1 用户没有指定工作空间,2 工作空间可用空间长度小于分割基数,
// 3 工作空间可用空间原点指针位置 + 分隔基数 > 可用空间数
// 表示开发人员没有想自定义参数或指定的参数不合理,则使用默认的参数构造。
if (work == null || workLen < tlen || workBase + tlen > work.length) {
@SuppressWarnings({"unchecked", "UnnecessaryLocalVariable"})
T[] newArray = (T[])java.lang.reflect.Array.newInstance
(a.getClass().getComponentType(), tlen);
tmp = newArray;
tmpBase = 0;
tmpLen = tlen;
}
else {
tmp = work;
tmpBase = workBase;
tmpLen = workLen;
}
/*
* 分配要合并的运行堆栈(无法扩展)。堆栈长度在listsort.txt中有描述。
* C版本总是使用85,但是这个长度在JAVA中对于中长度数组来说代价太大(例如100个元素的数组)。
* 因此,我们为较小的数组指定较小的堆栈大小。下列计算中的神奇数字,在MIN_MERGE被声明后就要被改变。
* 最大的堆栈大小49,允许Integer最大值-4的数组长度,如果数组是最坏的情况,
* 可以根据场景增加堆栈大小。更多的说明在下面地址的第4部分:
* http://envisage-project.eu/wp-content/uploads/2015/02/sorting.pdf
*/
int stackLen = (len < 120 ? 5 :
len < 1542 ? 10 :
len < 119151 ? 24 : 49);
runBase = new int[stackLen];
runLen = new int[stackLen];
}
/*
* 下一个方法(包私有和静态)构成这个类的整个API。
*/
/**
* 在必要时使用工作空间数组进行临时存储,来对给定的范围进行排序。
* 这个方法被设计,用在执行Arrays的公共方法sort的必要边界校验之后。
* invoked from public methods (in class Arrays) after performing
* any necessary array bounds checks and expanding parameters into
* the required forms.
*
* @param a the array to be sorted 待排序数组
* @param lo 排序的第一个元素下标, 包含该元素
* @param hi 排序的最后一个元素下标, 不包含该元素
* @param c the comparator to use 排序策略
* @param work a workspace array (slice) 工作空间
* @param workBase origin of usable space in work array 工作空间可用空间原点指针位置
* @param workLen usable size of work array 工作空间可用空间大小
* @since 1.8
*/
static <T> void sort(T[] a, int lo, int hi, Comparator<? super T> c,
T[] work, int workBase, int workLen) {
// 断言,只有为true才能继续执行,否则抛出java.lang.AssertionError
// 待排序数组、排序策略不能为空,开始下标和结束下标要在数组的长度范围内,开始下标要小于等于结束下标
assert c != null && a != null && lo >= 0 && lo <= hi && hi <= a.length;
// 排序区间的元素个数
int nRemaining = hi - lo;
if (nRemaining < 2)
return; // 没有或1个就没有必要排序了
// 如果数组小于MIN_MERGE(32)就不归并了,使用二分插排。
if (nRemaining < MIN_MERGE) {
int initRunLen = countRunAndMakeAscending(a, lo, hi, c);
binarySort(a, lo, hi, lo + initRunLen, c);
return;
}
/**
* 从左到右遍历数组一次, 找到所有run区间(要归并的区间),扩大小的run区间到minRun个元素,
* 把所有run区间归并到主要的数组栈内。
*/
TimSort<T> ts = new TimSort<>(a, c, work, workBase, workLen);
// 获得最小可接受的run长度
int minRun = minRunLength(nRemaining);
do {
// Identify next run,从lo开始到要开始排序位置之间的长度
int runLen = countRunAndMakeAscending(a, lo, hi, c);
// 如果要运行的长度较短,就在(minRun, nRemaining)之间取较小值
if (runLen < minRun) {
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen, c);
runLen = force;
}
// Push run onto pending-run stack, and maybe merge
// 将每一轮的开始位置和长度压入run中挂起的堆栈中
ts.pushRun(lo, runLen);
// 归并存储run的堆栈中的所有run
ts.mergeCollapse();
// Advance to find next run
lo += runLen;
nRemaining -= runLen;
} while (nRemaining != 0);
// Merge all remaining runs to complete sort
assert lo == hi;
ts.mergeForceCollapse();
assert ts.stackSize == 1;
}
/**
* 对指定数组指定部分进行二分插入排序。这个方法是对小数量元素排序的最好方法。
* 时间复杂度为O(n*logn),但最差的复杂度为O(n^2)。
*
* 如果初始指定要排序的部分已经排好序,这个方法能够获得好处:方法假设从开始到结束
* 下标之间的元素已经排好序了。
*
* @param a the array in which a range is to be sorted 待排序数组
* @param lo the index of the first element in the range to be sorted 开始下标
* @param hi the index after the last element in the range to be sorted 结束下标
* @param start the index of the first element in the range that is 要开始排序的下标
* not already known to be sorted ({@code lo <= start <= hi})
* @param c comparator to used for the sort 比较策略
*/
@SuppressWarnings("fallthrough")
private static <T> void binarySort(T[] a, int lo, int hi, int start,
Comparator<? super T> c) {
// 断言,start必须在开始和结束区间内,才能执行下去
assert lo <= start && start <= hi;
if (start == lo)
start++;
// 从开始的后一个开始遍历
for ( ; start < hi; start++) {
// 执行插入排序
T pivot = a[start];
// Set left (and right) to the index where a[start] (pivot) belongs
int left = lo;
int right = start;
assert left <= right;
/*
* Invariants:
* pivot >= all in [lo, left).
* pivot < all in [right, start).
*/
while (left < right) {
int mid = (left + right) >>> 1;
if (c.compare(pivot, a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
/*
* 不变的是 pivot 大于等于所有左边的元素,小于等于右边所有元素。注意,如果有元素等于轴,
* 那么左边的还是在左边右边的还是在右边,所以插入排序是稳定的。
*
* 左右滑动元素,为轴腾出空间。
*/
int n = start - left; // The number of elements to move
// Switch is just an optimization for arraycopy in default case
switch (n) {
case 2: a[left + 2] = a[left + 1];
case 1: a[left + 1] = a[left];
break;
default: System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}
/**
* 返回从指定数组的指定位置开始运行的长度,并确保方法返回的结果总是升序的
*
* A run is the longest ascending sequence with:
*
* a[lo] <= a[lo + 1] <= a[lo + 2] <= ...
*
* or the longest descending sequence with:
*
* a[lo] > a[lo + 1] > a[lo + 2] > ...
*
* 用于稳定的归并排序, 降序需要被严格定义,这样才能安全地,不破坏稳定地调用方法反转一个降序序列。
*
* @param a the array in which a run is to be counted and possibly reversed
* @param lo index of the first element in the run
* @param hi index after the last element that may be contained in the run.
It is required that {@code lo < hi}.
* @param c the comparator to used for the sort
* @return the length of the run beginning at the specified position in
* the specified array
*/
private static <T> int countRunAndMakeAscending(T[] a, int lo, int hi,
Comparator<? super T> c) {
// 断言,仅在开始下标小于结束下标的情况下执行,即指定区间里至少有两个元素
assert lo < hi;
// 从指定区间的第二个元素开始向结束下标运行
int runHi = lo + 1;
if (runHi == hi) // 如果第二个就是结束位置了,就返回1,说明运行长度就一个位置
return 1;
// 找到运行的结束位置, 并且反转范围内的降序情况
// 从开始位置遍历,如果头两个元素是升序,就遍历到不是的位置停止,如果头两个元素就是降序,
// 就遍历到不是倒序的位置停止,然后将从开始到倒序停止的位置之间的元素反转,保证开发人员
// 指定的要排序数组的最前面一部分或整个都是升序的,考虑的是极端的边界情况。
if (c.compare(a[runHi++], a[lo]) < 0) { // Descending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) < 0)
runHi++;
reverseRange(a, lo, runHi);
} else { // Ascending
while (runHi < hi && c.compare(a[runHi], a[runHi - 1]) >= 0)
runHi++;
}
// 得到的结果是长度,在binarySort中,将runHi作为start参数,即要开始插排的位置
return runHi - lo;
}
/**
* 反转降序的数组
*
* @param a the array in which a range is to be reversed
* @param lo the index of the first element in the range to be reversed
* @param hi the index after the last element in the range to be reversed
*/
private static void reverseRange(Object[] a, int lo, int hi) {
hi--;
while (lo < hi) {
Object t = a[lo];
a[lo++] = a[hi];
a[hi--] = t;
}
}
/**
* 返回给定数组最小可接受的运行长度。binarySort运行时如果比实际要小,会自动扩大。
*
* 粗略的说,计算如下:
* - 如果n < MIN_MERGE,返回n(太小了,不值得为花哨的东西烦恼)。
* - 如果n是2的倍数,就返回MIN_MERGE/2
* - 其他返回k,MIN_MERGE/2 <= k <= MIN_MERGE
*
* @param n the length of the array to be sorted 数组要排序的长度
* @return the length of the minimum run to be merged
*/
private static int minRunLength(int n) {
// 断言,长度必须大于等于0
assert n >= 0;
int r = 0; // Becomes 1 if any 1 bits are shifted off
while (n >= MIN_MERGE) {
r |= (n & 1);
n >>= 1;
}
return n + r;
}
/**
* Pushes the specified run onto the pending-run stack.
*
* @param runBase index of the first element in the run
* @param runLen the number of elements in the run
*/
private void pushRun(int runBase, int runLen) {
this.runBase[stackSize] = runBase;
this.runLen[stackSize] = runLen;
stackSize++;
}
/**
* 检查等待合并的运行堆栈,并合并相邻的run,直到重新建立堆栈(归并后会生成一个新的run)
* Examines the stack of runs waiting to be merged and merges adjacent runs
* until the stack invariants are reestablished:
*
* 1. runLen[i - 3] > runLen[i - 2] + runLen[i - 1]
* 2. runLen[i - 2] > runLen[i - 1]
* 每次将新run推入堆栈时都会调用此方法,因此保证在进入该方法时对i < stackSize保持不变。
* This method is called each time a new run is pushed onto the stack,
* so the invariants are guaranteed to hold for i < stackSize upon
* entry to the method.
*/
private void mergeCollapse() {
// 只有run堆栈中存在2个或以上的run才执行
while (stackSize > 1) {
// run堆栈大小-2,得到的n
int n = stackSize - 2;
// 如果堆栈中还有run、
if (n > 0 && runLen[n-1] <= runLen[n] + runLen[n+1]) {
if (runLen[n - 1] < runLen[n + 1])
n--;
mergeAt(n);
} else if (runLen[n] <= runLen[n + 1]) {
mergeAt(n);
} else {
break; // Invariant is established
}
}
}
/**
* Merges all runs on the stack until only one remains. This method is
* called once, to complete the sort.
* 归并所有run堆栈中的run,直到只剩一个。这个方法只会调用一次来完成排序。
*/
private void mergeForceCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
if (n > 0 && runLen[n - 1] < runLen[n + 1])
n--;
mergeAt(n);
}
}
/**
* 归并堆栈中指定位置的run和它后面相邻的run。i必须是run堆栈中的倒数第二或倒数第三个下标。
* 换句话说,i必须等于stackSize-2 或 stackSize-3。
*
* @param i stack index of the first of the two runs to merge
*/
private void mergeAt(int i) {
// 断言,run堆栈大小必须大于等于2,里面至少有2个run
assert stackSize >= 2;
// 指定的下标必须合理
assert i >= 0;
assert i == stackSize - 2 || i == stackSize - 3;
int base1 = runBase[i]; // 左边run的开始位置
int len1 = runLen[i]; // 左边run的长度
int base2 = runBase[i + 1]; // 右边run的开始位置
int len2 = runLen[i + 1]; // 右边run的长度
assert len1 > 0 && len2 > 0; // 断言,两个run的长度必须大于0
assert base1 + len1 == base2; // 断言,两个run必须是挨着的
/*
* Record the length of the combined runs; if i is the 3rd-last
* run now, also slide over the last run (which isn't involved
* in this merge). The current run (i+1) goes away in any case.
*/
// 更新左边的run长度,合并左右两个run的长度
runLen[i] = len1 + len2;
// 如果i指向倒数第3个,现在的那倒数第二个将直接记录现在的倒数第一个run的相关参数,成为新的倒数第一
if (i == stackSize - 3) {
runBase[i + 1] = runBase[i + 2];
runLen[i + 1] = runLen[i + 2];
}
// run堆栈大小缩减1
stackSize--;
/*
* 找到run2第一个元素,要排到run1中的位置下标。
*/
// k:run2第一个元素,要排到run1中的某个位置,这个位置距离base1的长度
int k = gallopRight(a[base2], a, base1, len1, 0, c);
assert k >= 0;
// 移动run1的开始位置指针base1,移动k个长度
base1 += k;
// run1的长度可以相应减少k
len1 -= k;
if (len1 == 0) // 边界判断,如果k刚好就是原来run1的长度,则len1就是0了
return; // 这种情况表示run1和run2已经排好序了,就不用继续执行下面的代码了
/*
* 找到run1最后一个元素,要排到run2中的某个位置,方法与上面类似。
*/
len2 = gallopLeft(a[base1 + len1 - 1], a, base2, len2, len2 - 1, c);
assert len2 >= 0;
if (len2 == 0)
return;
// Merge remaining runs, using tmp array with min(len1, len2) elements
// len1和len2两个run的长度,以小的那个为基础,归并长的那个,这样长的run中多余的就不
// 需要继续循环,而是直接拷贝过去
if (len1 <= len2)
mergeLo(base1, len1, base2, len2);
else
mergeHi(base1, len1, base2, len2);
}
/**
* Locates the position at which to insert the specified key into the
* specified sorted range; if the range contains an element equal to key,
* returns the index of the leftmost equal element.
*
* @param key the key whose insertion point to search for
* @param a the array in which to search
* @param base the index of the first element in the range
* @param len the length of the range; must be > 0
* @param hint the index at which to begin the search, 0 <= hint < n.
* The closer hint is to the result, the faster this method will run.
* @param c the comparator used to order the range, and to search
* @return the int k, 0 <= k <= n such that a[b + k - 1] < key <= a[b + k],
* pretending that a[b - 1] is minus infinity and a[b + n] is infinity.
* In other words, key belongs at index b + k; or in other words,
* the first k elements of a should precede key, and the last n - k
* should follow it.
*/
private static <T> int gallopLeft(T key, T[] a, int base, int len, int hint,
Comparator<? super T> c) {
assert len > 0 && hint >= 0 && hint < len;
int lastOfs = 0;
int ofs = 1;
if (c.compare(key, a[base + hint]) > 0) {
// Gallop right until a[base+hint+lastOfs] < key <= a[base+hint+ofs]
int maxOfs = len - hint;
while (ofs < maxOfs && c.compare(key, a[base + hint + ofs]) > 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs)
ofs = maxOfs;
// Make offsets relative to base
lastOfs += hint;
ofs += hint;
} else { // key <= a[base + hint]
// Gallop left until a[base+hint-ofs] < key <= a[base+hint-lastOfs]
final int maxOfs = hint + 1;
while (ofs < maxOfs && c.compare(key, a[base + hint - ofs]) <= 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs)
ofs = maxOfs;
// Make offsets relative to base
int tmp = lastOfs;
lastOfs = hint - ofs;
ofs = hint - tmp;
}
assert -1 <= lastOfs && lastOfs < ofs && ofs <= len;
/*
* Now a[base+lastOfs] < key <= a[base+ofs], so key belongs somewhere
* to the right of lastOfs but no farther right than ofs. Do a binary
* search, with invariant a[base + lastOfs - 1] < key <= a[base + ofs].
*/
lastOfs++;
while (lastOfs < ofs) {
int m = lastOfs + ((ofs - lastOfs) >>> 1);
if (c.compare(key, a[base + m]) > 0)
lastOfs = m + 1; // a[base + m] < key
else
ofs = m; // key <= a[base + m]
}
assert lastOfs == ofs; // so a[base + ofs - 1] < key <= a[base + ofs]
return ofs;
}
/**
* 类似gallopLeft方法, 如果指定范围内包含一个元素与key相等,期望gallopRight方法返回
* 最右边相等元素之后的下标。
*
* @param key 要搜索其插入点的key
* @param a 在这个数组上查找
* @param base 范围内第一个开始下标
* @param len 查找范围的长度,必须大于0
* @param hint 开始查询的下标, 0 <= hint < n。开始查询的下标越接近结果,这个方法执行
* 的就越快。
* @param c 比较策略
* @return the int k, 0 <= k <= n such that a[b + k - 1] <= key < a[b + k]
*/
private static <T> int gallopRight(T key, T[] a, int base, int len,
int hint, Comparator<? super T> c) {
assert len > 0 && hint >= 0 && hint < len;
int ofs = 1;
int lastOfs = 0;
if (c.compare(key, a[base + hint]) < 0) {
// Gallop left until a[b+hint - ofs] <= key < a[b+hint - lastOfs]
int maxOfs = hint + 1;
while (ofs < maxOfs && c.compare(key, a[base + hint - ofs]) < 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs)
ofs = maxOfs;
// Make offsets relative to b
int tmp = lastOfs;
lastOfs = hint - ofs;
ofs = hint - tmp;
} else { // a[b + hint] <= key
// Gallop right until a[b+hint + lastOfs] <= key < a[b+hint + ofs]
int maxOfs = len - hint;
while (ofs < maxOfs && c.compare(key, a[base + hint + ofs]) >= 0) {
lastOfs = ofs;
ofs = (ofs << 1) + 1;
if (ofs <= 0) // int overflow
ofs = maxOfs;
}
if (ofs > maxOfs)
ofs = maxOfs;
// Make offsets relative to b
lastOfs += hint;
ofs += hint;
}
assert -1 <= lastOfs && lastOfs < ofs && ofs <= len;
/*
* Now a[b + lastOfs] <= key < a[b + ofs], so key belongs somewhere to
* the right of lastOfs but no farther right than ofs. Do a binary
* search, with invariant a[b + lastOfs - 1] <= key < a[b + ofs].
*/
lastOfs++;
while (lastOfs < ofs) {
int m = lastOfs + ((ofs - lastOfs) >>> 1);
if (c.compare(key, a[base + m]) < 0)
ofs = m; // key < a[b + m]
else
lastOfs = m + 1; // a[b + m] <= key
}
assert lastOfs == ofs; // so a[b + ofs - 1] <= key < a[b + ofs]
return ofs;
}
/**
* 在适当的位置稳定地归并两个相邻的run。第一个run的第一个元素必须必第二个run的第一个元素大,
* 并且第一个run的最后一个元素必须必第二个run中的所有元素都要大。
* Merges two adjacent runs in place, in a stable fashion. The first
* element of the first run must be greater than the first element of the
* second run (a[base1] > a[base2]), and the last element of the first run
* (a[base1 + len1-1]) must be greater than all elements of the second run.
*
* 对于性能,这个方法必须在第一个run长度小于等于第二个run长度时调用,另一个方法mergeHi则
* 需要在第一个run长度大于等于第二个run长度的时候调用。(它们都可以在两个run长度相等时调用)
* For performance, this method should be called only when len1 <= len2;
* its twin, mergeHi should be called if len1 >= len2. (Either method
* may be called if len1 == len2.)
*
* @param base1 index of first element in first run to be merged
* @param len1 length of first run to be merged (must be > 0)
* @param base2 index of first element in second run to be merged
* (must be aBase + aLen)
* @param len2 length of second run to be merged (must be > 0)
*/
private void mergeLo(int base1, int len1, int base2, int len2) {
// 断言,两个run的长度都要大于0,且两个run是相邻的
assert len1 > 0 && len2 > 0 && base1 + len1 == base2;
// Copy first run into temp array 这部分是将第一个run复制到了一个临时数组
T[] a = this.a; // For performance
T[] tmp = ensureCapacity(len1);
int cursor1 = tmpBase; // Indexes into tmp array 光标1,临时数组(run1)开始位置,0
int cursor2 = base2; // Indexes int a 光标2,run2开始位置
int dest = base1; // Indexes int a run1的开始位置
System.arraycopy(a, base1, tmp, cursor1, len1);
// Move first element of second run and deal with degenerate cases
// 移动第二个run的第一个元素,并处理退化的情况
a[dest++] = a[cursor2++];// run1的第一个元素设置为run2的第一个元素(对a操作)
if (--len2 == 0) {// 如果run2只有1个元素,把temp中存储的覆盖到已经改变的a中
System.arraycopy(tmp, cursor1, a, dest, len1);
return;
}
if (len1 == 1) {// 如果run1只有一个元素,把run2拷贝到原run1的位置
System.arraycopy(a, cursor2, a, dest, len2);
// run1的第一个元素
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
return;
}
Comparator<? super T> c = this.c; // Use local variable for performance
int minGallop = this.minGallop; // " " " " "
outer:
// 开始归并操作
while (true) {
int count1 = 0; // Number of times in a row that first run won
int count2 = 0; // Number of times in a row that second run won
/*
* Do the straightforward thing until (if ever) one run starts
* winning consistently.
*/
do {
assert len1 > 1 && len2 > 0;
if (c.compare(a[cursor2], tmp[cursor1]) < 0) {
a[dest++] = a[cursor2++];
count2++;
count1 = 0;
if (--len2 == 0)
break outer;
} else {
a[dest++] = tmp[cursor1++];
count1++;
count2 = 0;
if (--len1 == 1)
break outer;
}
} while ((count1 | count2) < minGallop);
/*
* One run is winning so consistently that galloping may be a
* huge win. So try that, and continue galloping until (if ever)
* neither run appears to be winning consistently anymore.
*/
do {
assert len1 > 1 && len2 > 0;
count1 = gallopRight(a[cursor2], tmp, cursor1, len1, 0, c);
if (count1 != 0) {
System.arraycopy(tmp, cursor1, a, dest, count1);
dest += count1;
cursor1 += count1;
len1 -= count1;
if (len1 <= 1) // len1 == 1 || len1 == 0
break outer;
}
a[dest++] = a[cursor2++];
if (--len2 == 0)
break outer;
count2 = gallopLeft(tmp[cursor1], a, cursor2, len2, 0, c);
if (count2 != 0) {
System.arraycopy(a, cursor2, a, dest, count2);
dest += count2;
cursor2 += count2;
len2 -= count2;
if (len2 == 0)
break outer;
}
a[dest++] = tmp[cursor1++];
if (--len1 == 1)
break outer;
minGallop--;
} while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP);
if (minGallop < 0)
minGallop = 0;
minGallop += 2; // Penalize for leaving gallop mode
} // End of "outer" loop
this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field
if (len1 == 1) {
assert len2 > 0;
System.arraycopy(a, cursor2, a, dest, len2);
a[dest + len2] = tmp[cursor1]; // Last elt of run 1 to end of merge
} else if (len1 == 0) {
throw new IllegalArgumentException(
"Comparison method violates its general contract!");
} else {
assert len2 == 0;
assert len1 > 1;
System.arraycopy(tmp, cursor1, a, dest, len1);
}
}
/**
* Like mergeLo, except that this method should be called only if
* len1 >= len2; mergeLo should be called if len1 <= len2. (Either method
* may be called if len1 == len2.)
*
* @param base1 index of first element in first run to be merged
* @param len1 length of first run to be merged (must be > 0)
* @param base2 index of first element in second run to be merged
* (must be aBase + aLen)
* @param len2 length of second run to be merged (must be > 0)
*/
private void mergeHi(int base1, int len1, int base2, int len2) {
assert len1 > 0 && len2 > 0 && base1 + len1 == base2;
// Copy second run into temp array
T[] a = this.a; // For performance
T[] tmp = ensureCapacity(len2);
int tmpBase = this.tmpBase;
System.arraycopy(a, base2, tmp, tmpBase, len2);
int cursor1 = base1 + len1 - 1; // Indexes into a
int cursor2 = tmpBase + len2 - 1; // Indexes into tmp array
int dest = base2 + len2 - 1; // Indexes into a
// Move last element of first run and deal with degenerate cases
a[dest--] = a[cursor1--];
if (--len1 == 0) {
System.arraycopy(tmp, tmpBase, a, dest - (len2 - 1), len2);
return;
}
if (len2 == 1) {
dest -= len1;
cursor1 -= len1;
System.arraycopy(a, cursor1 + 1, a, dest + 1, len1);
a[dest] = tmp[cursor2];
return;
}
Comparator<? super T> c = this.c; // Use local variable for performance
int minGallop = this.minGallop; // " " " " "
outer:
while (true) {
int count1 = 0; // Number of times in a row that first run won
int count2 = 0; // Number of times in a row that second run won
/*
* Do the straightforward thing until (if ever) one run
* appears to win consistently.
*/
do {
assert len1 > 0 && len2 > 1;
if (c.compare(tmp[cursor2], a[cursor1]) < 0) {
a[dest--] = a[cursor1--];
count1++;
count2 = 0;
if (--len1 == 0)
break outer;
} else {
a[dest--] = tmp[cursor2--];
count2++;
count1 = 0;
if (--len2 == 1)
break outer;
}
} while ((count1 | count2) < minGallop);
/*
* One run is winning so consistently that galloping may be a
* huge win. So try that, and continue galloping until (if ever)
* neither run appears to be winning consistently anymore.
*/
do {
assert len1 > 0 && len2 > 1;
count1 = len1 - gallopRight(tmp[cursor2], a, base1, len1, len1 - 1, c);
if (count1 != 0) {
dest -= count1;
cursor1 -= count1;
len1 -= count1;
System.arraycopy(a, cursor1 + 1, a, dest + 1, count1);
if (len1 == 0)
break outer;
}
a[dest--] = tmp[cursor2--];
if (--len2 == 1)
break outer;
count2 = len2 - gallopLeft(a[cursor1], tmp, tmpBase, len2, len2 - 1, c);
if (count2 != 0) {
dest -= count2;
cursor2 -= count2;
len2 -= count2;
System.arraycopy(tmp, cursor2 + 1, a, dest + 1, count2);
if (len2 <= 1) // len2 == 1 || len2 == 0
break outer;
}
a[dest--] = a[cursor1--];
if (--len1 == 0)
break outer;
minGallop--;
} while (count1 >= MIN_GALLOP | count2 >= MIN_GALLOP);
if (minGallop < 0)
minGallop = 0;
minGallop += 2; // Penalize for leaving gallop mode
} // End of "outer" loop
this.minGallop = minGallop < 1 ? 1 : minGallop; // Write back to field
if (len2 == 1) {
assert len1 > 0;
dest -= len1;
cursor1 -= len1;
System.arraycopy(a, cursor1 + 1, a, dest + 1, len1);
a[dest] = tmp[cursor2]; // Move first elt of run2 to front of merge
} else if (len2 == 0) {
throw new IllegalArgumentException(
"Comparison method violates its general contract!");
} else {
assert len1 == 0;
assert len2 > 0;
System.arraycopy(tmp, tmpBase, a, dest - (len2 - 1), len2);
}
}
/**
* Ensures that the external array tmp has at least the specified
* number of elements, increasing its size if necessary. The size
* increases exponentially to ensure amortized linear time complexity.
*
* @param minCapacity the minimum required capacity of the tmp array
* @return tmp, whether or not it grew
*/
private T[] ensureCapacity(int minCapacity) {
if (tmpLen < minCapacity) {
// Compute smallest power of 2 > minCapacity
int newSize = minCapacity;
newSize |= newSize >> 1;
newSize |= newSize >> 2;
newSize |= newSize >> 4;
newSize |= newSize >> 8;
newSize |= newSize >> 16;
newSize++;
if (newSize < 0) // Not bloody likely!
newSize = minCapacity;
else
newSize = Math.min(newSize, a.length >>> 1);
@SuppressWarnings({"unchecked", "UnnecessaryLocalVariable"})
T[] newArray = (T[])java.lang.reflect.Array.newInstance
(a.getClass().getComponentType(), newSize);
tmp = newArray;
tmpLen = newSize;
tmpBase = 0;
}
return tmp;
}
}
学习笔记
1 成员变量
| 变量名 | 变量类型 | 变量值 | 变量解释 |
|---|---|---|---|
| tmp | T[] | new T[50] | 临时数组 |
| tmpBase | int | 0 | |
| tmpLen | int | 50 | |
| stackSize | int | 0 | 归并的次数,初始为0 |
| runBase | int[] | new int[5] | 记录着待排序数组(a)中每一个排好序待归并部分的起始位置 |
| runLen | int[] | new int[5] | 记录着待排序数组(a)中每一个排好序待归并部分的长度(元素个数) |
2 sort方法入参
| 变量名 | 变量类型 | 变量值 | 变量解释 |
|---|---|---|---|
| a | T[] | Object | 可排序的对象 |
| lo | int | 0 | 指定待排序的开始位置下标(含) |
| hi | int | 100 | 指定待排序的结束位置下标(不含) |
| c | Comparator | Comparator | 比较策略 |
| work | |||
| workBase | |||
| workLen |
3 sort方法阅读笔记
注意:以下run将作为,每一个待排序数组中,指定要排序区间内,已经按照升序排好的,待归并的区间的称呼。
3.1 计算最小允许的run长度,以a.length=100来算
假设有一个待排序的数组,数组长度为100。
数组的其中一部分为:{ 5 , 9 , 3, 6, 2, 1, 7 …… 8}
int minRun = minRunLength(nRemaining); // 25
3.2 开始循环(do-while)
步骤:
- 获得从每次迭代的初始位置开始,到下一个run之间的长度
- 如果上一步计算到的长度不够25(minRun),就用二分插排法(binarySort)排序lo下标开始的25个元素
- 把排好序的“起始下标”、“run长度”两个参数分别存入runBase和runLen成员变量中
- mergeCollapse
- 边界值计算、判断是否还有未完成工作,结束或继续下一轮循环
3.2.1 计算最小run的长度
涉及较复杂的考虑、计算没研究,此处不作描述。
3.2.2 计算下一个run的长度
这里分两种情况进行讨论,第二种仅仅是作为说明。
3.2.2.1 假设a数组如下(最初设定的数组):
{ 5 , 9 , 3, 6, 2, 1, 7 …… 8}
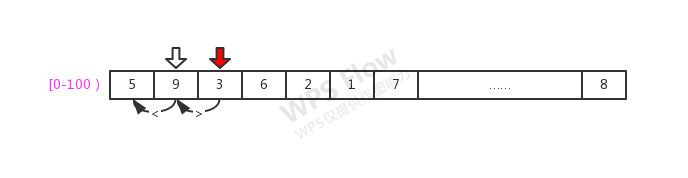
上图描述了获得下一个run长度的过程:第一步是第一和第二个元素进行比较,如果左<右则继续比较, 作为指针的runHi开始是指向第二个元素,比较后指向下一个元素(3);然后开始第二次比较,但是此时 左(9)> 右(3),就停止比较,得到了要排序的位置,此时runHi是在下标2的位置,那么这时得到的run 长度为runHi - lo = 2。
3.2.2.2 假设a数组如下(临时说明):
{ 9 , 5 , 3, 6, 2, 1, 7 …… 8} 这个数组与原数组仅仅是第一和第二元素的位置换了一下

上图描述了获得下一个run长度的过程:与3.2.2.1不同的是,第一个元素大于第二个元素,这种情况下, 作者进行了降序极端情况的优化,直接继续比较后续的每对相邻元素,直到非倒序的情况(反转前-绿), 如上图中的runHi;当满足这种情况时,算法中会将前3个降序排列的元素反转过来(反转后-黄),方法返回 的run长度计算公式一样,runHi - lo = 3。
3.2.3 判断是否需要用二分插排
作者通过一套测算较为完善,且性能较为优越的方法,得到了最小的run长度,如果开发人员在3.2.2中得到的长度小于默认的长度,就会使用binarySort(二分查找插入排序)排序好最小run长度个相邻元素,然后将该元素区间作为参数记录到成员变量的运行相关变量中,等待归并操作。
3.2.4 将上面得到的run的信息存入run堆栈
/**
* runBase:已经排好序的开始位置,runLen:这个run区间的长度
*/
private void pushRun(int runBase, int runLen) {
this.runBase[stackSize] = runBase;
this.runLen[stackSize] = runLen;
stackSize++; // 每存入一对run参数,size就要+1,记录总个数
}
3.2.5 执行归并
归并存储在run堆栈中的所有run。
3.2.5.1 归并条件
归并前先判断run堆栈中的run是否超过1个,否则没有归并的必要。
3.2.5.2 归并
该归并是传统的归并算法,但是是基于两个已经排好序的数组(run)来归并。
3.2.6 边界处理
处理边界值,结束本次循环前要为下一次循环计算好参数,然后开始判断是否满足条件进行下一次循环。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









